

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- retrieval
- Baekjoon
- Noise Robustness
- LLM
- reranking
- moe
- COT
- Transformer
- Hallucination
- DyPRAG
- lora
- Embedding
- coding test
- SFT
- Retriever
- Algorithm
- RAG
- Do it
- odds
- Python
- qwen
- NLP
- GPT
- fine-tuning
- Noise
- 파인튜닝
- Statistics
- Parametric RAG
- Document Augmentation
- DPO
Archives
- Today
- Total
왕구아니다
[논문 리뷰] Aligning Extraction and Generation for Robust Retrieval-Augmented Generation 본문
Paper Review/RAG
[논문 리뷰] Aligning Extraction and Generation for Robust Retrieval-Augmented Generation
Psalms 12:6-7 2026. 2. 19. 16:44본 논문 리뷰는 저의 개인적인 해석과 의견을 바탕으로 작성된 글입니다.
내용 중 해석의 오류나 개념적인 착오가 있다면, 망설이지 마시고 댓글로 혼내주시면 감사하겠습니다~
Preview
- Ext2Gen은 extract-then-generate 구조에서 pairwise preference(DPO) 기반 alignment를 통해 noisy retrieval 환경에서도 관련 문장만 추출하도록 학습시켜, generation 단계에서 precision–recall 균형을 맞추며 강건성을 확보함
- (i) 관련 청크 위치 변화와 최대 25개 irrelevant chunk를 추가한 controlled noisy setting
- (ii) BEIR 기반 대규모 실제 RAG 환경에서 Top-K(10/20/30) 및 다양한 retriever(Naive, HyDE, MuGI) 조합 테스트로 robustness를 다각도로 검증
- Ext2Gen-R2는 독립 compression 모듈 없이도 Default 및 SFT/Compression 기반 방법들을 일관되게 능가하며, retrieval 품질이 높아진 경우에도 추가적인 성능 향상을 보여 generation-side alignment의 보완적 역할을 입증함
Link
- 논문 : https://arxiv.org/abs/2503.04789
- 코드 : https://huggingface.co/DISLab/Ext2Gen-8B-R2
DISLab/Ext2Gen-8B-R2 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
📍0. Abstract
- Ext2Gen이라는 extract-then-generate 프레임워크를 제안하며, 이는 증거 선택과 답변 생성을 공동으로 수행하여 LLM을 강화한다.
- 이 방식은 질의와 관련된 내용을 동적으로 식별하고 노이즈를 억제하며, 별도의 사전 압축 모듈 없이도 동작한다.
📍1. Introduction

- retrieval 정확도의 발전에도 불구하고, 생성 과정에는 여전히 두 가지 핵심 문제로 인해 병목이 존재한다.
- 첫째, 관련 청크의 위치가 불확실하여 검색 결과 리스트 내에서 예측할 수 없는 위치에 배치된다.
- 관련 정보가 중간에 위치할 경우, lost-in-the-middle 현상으로 인해 잊혀질 수 있다.
- 둘째, 다양한 정도의 불필요한 청크가 포함되는 정보 노이즈로 인해 생성이 방해받으며, 이는 모델의 집중을 흐트러뜨린다.
- 본 논문에서는 정확한 retrieval을 넘어, 정보 망각과 노이즈에도 강건한 생성(robust generation)에 초점을 맞춘다.
- 핵심 아이디어는 모델이 먼저 노이즈가 포함된 검색 청크에서 질의와 관련된 문장을 추출하고, 그 추출된 내용을 정제하여 정확한 답을 생성하도록 학습시키는 것이다.
- 이러한 강건성을 체계적으로 달성하기 위해 생성 단계의 두 가지 문제를 alignment 문제로 정의한다. 즉, 모델이 갖추어야 할 능력과 실제 행동 사이에 괴리가 존재한다는 것이다.
- 이상적으로 모델은 관련 청크의 위치나 노이즈 존재 여부와 상관없이 정확히 식별해야 하지만, 실제로는 위치와 검색 과정에서 발생하는 노이즈에 의해 쉽게 방해받는다.
📍2. Alignment with Ext2Gen
2.1 Dataset Generation
QA Generation

- 출처 도메인의 다양성은 포괄적인 QA 데이터셋을 구축하는 데 필수적이며, 이는 모델이 다양한 맥락에 걸쳐 일반화할 수 있도록 돕는다.
- 이미 고품질 QA 쌍이 존재하는 도메인인 HotPotQA(Wikipedia)와 MS-MARCO(web search)에서는 각 데이터셋에서 4,000개의 QA 쌍을 직접 샘플링한다.
- MS-MARCO의 경우, 원래 데이터셋 정의에 따라 질문을 두 가지 유형(long-form (“description”) and short-form)으로 분류한다.
- 각 유형에서 2,000개씩 샘플링
- HotPotQA와 MS-MARCO를 합쳐 총 8,000개의 QA 쌍을 구성한다.
- QA 주석이 존재하지 않는 나머지 도메인(PubMed, CNNDM, GovReport)에서는 GPT-4o를 사용하여 각 도메인당 4,000개의 <질문, 답변> 쌍을 생성한다.
- 그 결과, 다섯 개의 서로 다른 도메인에 걸쳐 균형 잡히고 다양한 QA 세트가 구성된다.
Chunk Collection
- 앞서 QA 쌍을 만들었으니, 이젠 Answer에 답하기 위한 Question의 Documents(chunks)를 검색한다.
- QA 쌍을 생성하는 데 사용된 원래 청크를 “relevant” 청크로 지정한다.
- “irrelevant” 청크를 얻기 위해, 모든 텍스트 청크를 ChromaDB에 저장하고 multilingual-e5-large-instruct 모델을 사용해 dense retrieval을 수행하여 각 질의에 대해 top-50 청크를 검색한다.
- relevant 청크와 동일한 청크를 제거(exact matching)한 후, 남은 결과들을 “noisy” 청크로 간주한다.
- 여기서 이를 noisy라고 부르는 이유는, exact matching으로 제거되지 않은 일부 검색 청크가 여전히 관련 정보를 포함할 수 있기 때문이다.
- 이 과정을 통해 각 데이터셋당 4,000개의 QA–chunk 인스턴스가 생성되며, 다섯 개 데이터셋을 합쳐 총 20,000개의 인스턴스가 구성된다.
Data Filtering

- 지금까지 만든 데이터셋에는 인간이 생성한 QA 쌍과 LLM이 생성한 QA 쌍이 모두 포함되어 있다.
- HotPotQA, MS-MARCO → human QA
- PubMed, CNNDM, GovReport → GPT-4o 생성 QA
- 그러나 LLM이 생성한 QA 쌍의 경우 환각(hallucination) 위험이 있으며, 이는 데이터셋에 바람직하지 않은 편향을 도입할 수 있다.
- 이 문제를 완화하기 위해 QA 쌍과 관련 청크를 면밀히 검사한다.
- 환각된 답변은 relevant 청크에 의해 뒷받침되지 않을 수 있기 때문
- 또한 환각 문제 외에도, “noisy”로 라벨된 일부 청크가 명시적으로 relevant로 표시되지 않았더라도 정답을 뒷받침하는 정보를 포함할 수 있다.
- 앞에서 noisy chunk는 Top-50에서 relevant 제외한 것. 하지만 일부 chunk는 간접적으로 정답을 포함할 수 있음. 이걸 그대로 두면 alignment 학습이 왜곡됨.
- 따라서 alignment 학습에 미치는 부정적 영향을 줄이기 위해, 초기 QA 쌍과 noisy 청크 세트를 정제하는 추가 필터링 단계를 도입한다.
- 이 단계에서 GPT-4o의 잠재적 자기 편향을 줄이기 위해 Llama3.3-70b-instruct를 필터링 모델로 사용한다.
- 동일한 LLM을 생성과 평가에 모두 사용하면 자기 출력에 유리한 편향이 발생할 수 있기 때문
- 구체적으로, Table 3의 validity check 프롬프트를 사용하여 Llama3.3 모델로 “Answer Validation”을 수행한다. (1) 여기서는 답변이 relevant 청크로부터 완전히 도출 가능한지를 평가하며, 그렇지 않으면 해당 QA 쌍을 환각으로 간주하고 제거한다. (2) 그리고 “Chunk Validation” 단계에서는 noisy 세트의 각 청크에 대해 해당 청크로부터 답을 도출할 수 없는지를 확인하며, 만약 가능하다면 그 청크는 noisy 세트에서 제거된다.
- 두 검사는 동일한 프롬프트를 사용하며, 이는 주어진 청크가 답을 지지하는지를 검증하는 동일한 작업이기 때문
- 이 과정을 통해 18,000개의 QA 쌍이 남으며, 각 청크는 명확히 relevant 또는 irrelevant로 라벨링되고, 답변은 참조 정답으로 사용된다.
- 초기 20K → filtering 후 18K
Input Consolidation

- 18K로 정제된 데이터셋에 대해, 각 질의와 그에 대응하는 irrelevant 청크 세트를 사용하여 RAG의 생성 단계를 모사하는 입력을 구성한다.
- 현실적인 noisy retrieval 상황을 더 잘 반영하기 위해, relevant 청크 1개와 irrelevant 세트에서 균등 샘플링한 최대 25개의 청크를 결합한 후, 이를 무작위로 섞어 하나의 청크 리스트를 구성한다.
- Relevant chunk: 1개 / Irrelevant chunk: 최대 25개 → 총 최대 26개 chunk
- 여기서 학습되는 두 가지 robustness
- (1) Noise robustness → irrelevant 비율 증가
- (2) Position invariance → relevant 위치 랜덤
- 이 리스트는 RAG에서의 Top-𝑘 retrieval의 변동성을 시뮬레이션하며, relevant 청크의 불확실한 위치와 다양한 양의 irrelevant 정보 존재를 모두 반영한다.
- Top-k가 커질수록
- Recall ↑
- Noise ↑
- 그리고 relevant chunk 위치는 예측 불가
- Ext2Gen은 이 분포 자체를 학습함
- Top-k가 커질수록
- 최종 답변 생성을 위한 입력 프롬프트는 질의와 무작위로 섞인 청크 리스트를 사용하여 구성되며, Table 1에 제시된 Ext2Gen 프롬프트 형식을 따른다.
- 다음 단계에서는 이렇게 구성된 noisy 입력을 사용해 chosen(바람직한) 출력과 rejected(바람직하지 않은) 출력을 모두 생성하고, alignment 학습을 통해 모델이 noisy retrieval 환경에서도 바람직한 응답을 생성하도록 유도한다.
2.2 Feedback Collection
Output Generation

- 앞선 과정에서 만든 18K개의 데이터를 가지고 Table 1의 Ext2Gen 프롬프트를 활용해 서로 다른 성능 수준을 가진 8개의 LLM으로부터 여러 개의 출력 결과를 수집한다.
- 이 후보 출력들 중에서 고품질 응답은 “chosen”으로, 품질이 낮거나 결함이 있는 응답은 “rejected”로 라벨링된다.
- 이러한 모델 다양성은 효과적인 alignment에 필수적인데, 동일한 입력에 대해 다양한 품질의 응답을 수집할 수 있게 해주며, 이는 정보성이 높은 pairwise 피드백을 구성하는 데 필수적이다.
- Preference learning은 “좋은 답 vs 나쁜 답의 차이”를 학습함. 즉, 모델 다양성이 크면 → 이 차이가 명확해짐.
- 그 결과, 18,000개의 noisy 입력 인스턴스에 대해 8개 모델이 생성한 총 144,000개의 입력–응답 쌍이 생성되며, 다양한 품질 수준을 갖는다.
- 18K inputs × 8 LLM = 144K outputs
Output Compliance

- Ext2Gen에서 기대하는 출력 형식에 맞추기 위해, LLM의 출력 결과를 정규화하며, 추출 문장만 포함한 경우, 추출 없이 바로 답만 제시한 경우, 또는 잘못된 형식을 따른 출력은 제거한다.
- alignment 과정에서 이 단계는 모델이 일관된 출력 형식을 유지하도록 돕는다.
Feedback Composition
- 여러 출력 결과의 정답성을 비교함으로써 preference alignment를 위한 pairwise 피드백을 구성한다.
- 두 가지 관점에서 출력을 평가하기 위해 네 가지 지표를 사용한다.
- Acc와 LLMEval은 생성된 답이 정답을 포함하는지를 평가하며, ROUGE-L과 BERTScore는 정답과 생성 답변 간의 어휘적·의미적 유사성을 측정한다.
Rule 1: Inclusion-only
- Rule 1은 포함 기반 지표만 고려하며, Acc와 LLMEval을 이진값으로 사용한다. 1은 생성 답이 정답을 포함함을 의미하고, 0은 포함하지 않음을 의미한다.
- 여기서 chosen과 rejected 후보를 평가하기 위해 두 가지 조건을 사용한다.

- 식 1 : chosen이 될 수 있는 최소 조건 (절대 기준)
- 출력 i가 chosen 후보가 되려면 Acc = 1 이거나, LLMEval = 1 이거나, 둘 다 1. 즉, 정답을 최소한 포함해야 한다는 절대 기준

- 식 2 : chosen과 rejected를 비교하는 상대 조건 (비교 기준)
- 두 출력 i, j를 비교했을 때 inclusion 점수 합이 더 큰 쪽이 chosen. 즉, 상대 비교 기준
Rule 2: Inclusion → Similarity
- 이 규칙은 inclusion과 similarity 지표를 모두 고려하지만, Acc와 LLMEval을 ROUGE-L과 BERTScore보다 우선적으로 반영한다.
- 먼저 inclusion으로 판단 동점이면 → similarity로 추가 판단
- chosen과 rejected를 결정하는 기본 기준은 Rule 1과 동일하며, 이는 식 (1)과 식 (2)에 정의되어 있다.
- 그러나 rejected 출력을 결정할 때, 앞선 식 (2) 조건에 더해, 두 출력 𝑖와 𝑗의 inclusion 점수가 동일한 경우(Acc와 LLMEval이 동일한 경우) 더 많은 chosen-rejected 쌍을 생성하기 위해 추가 기준을 도입한다.
- 두 출력이 모두 정답 포함 → inclusion 점수 동일. Rule1에서는 이 둘을 구분 못함. 그래서 similarity 기준을 추가함.
- 구체적으로, 출력 𝑗가 chosen 출력 𝑖와 동일한 inclusion 점수를 가지더라도 아래 조건 식을 만족하면 rejected로 간주된다.

- 이는 출력이 단순히 정답을 포함하는 것뿐 아니라, 더 높은 어휘적·의미적 유사성을 보일 경우 선호되도록 보장한다.
- 𝜖 값은 0.30으로 설정되며, 이는 chosen 출력이 rejected 출력보다 충분히 높은 유사도 점수를 갖도록 하기 위함이다.
- 작은 similarity 차이로 chosen 결정하지 않음 → noisy preference 방지 → 안정적 alignment
- 두 규칙을 적용하여, inclusion 중심의 Rule 1에서는 120K개의 피드백 쌍을, inclusion과 similarity를 모두 반영한 Rule 2에서는 150K개의 피드백 쌍을 구성한다.
- 한 input에서 모델 8개가 답을 생성하면, 가능한 모든 쌍(pair)은 8C2 = 28개(이 8개 중에서 두 개를 골라 “누가 더 좋은가?”를 비교). 즉, 이론적으로는18K * 28 = 504K개까지 만들 수 있음. 그러나 Rule1,2 적용하면 몇 개는 걸러짐.

- Table 5는 Rule 2 기준으로 구성된 150K 피드백 세트에서 각 LLM의 출력이 chosen 또는 rejected로 판단된 비율을 보여준다.
- 오른쪽에 위치한 더 강력한 LLM들이 더 자주 chosen되지만, 모든 출력이 선호되는 것은 아니며, 왼쪽의 약한 LLM들도 종종 더 나은 출력을 생성한다.
- 이는 다양한 LLM 풀에서 후보를 샘플링하는 전략을 뒷받침하며, 모델의 정체성이 아닌 실제 응답의 정확성을 기준으로 더 정교한 pairwise 선택이 가능하게 한다.
- Rule 1의 분포도 일관된 경향을 보이며, 150K 쌍은 120K 쌍을 모두 포함하는 상위 집합이기 때문이다.
- Rule2 ⊃ Rule1
2.3 Preference Optimization
- pairwise 피드백을 사용하며, 여기서 각 입력(질문과 해당 청크 리스트로 구성됨)은 하나의 선호되는 출력(chosen)과 하나의 덜 선호되는 출력(rejected)과 함께 짝지어진다.
- “이 입력에서는 이 답이 저 답보다 더 좋다”
- QA 생성 과정에서 GPT-4o가 일부 사용되었지만, GPT-4o의 응답은 학습 데이터에 포함되지 않는다.
- 대신, 학습에 사용되는 응답은 Table 4에 나열된 다양한 모델들로부터 생성되며, 이를 통해 특정 LLM을 모방하는 것을 방지하고 스타일 다양성을 유지한다.
- Alignment 튜닝을 위해 주로 Llama3.2-3b-instruct와 Llama3.1-8b-instruct를 generation backbones으로 사용한다.
- 실험에서는 SFT와 DPO를 중심으로 총 7가지 학습 설정을 탐구하여, pairwise 피드백이 백본 모델의 강건성을 얼마나 효과적으로 개선하는지 평가한다.
SFT-Best
- 각 질문에 대해 8개 LLM 중 네 가지 QA 지표의 평균 점수가 가장 높은 출력을 선택한다.(chosen만 사용)
SFT-{Metric}
- SFT-Best와 유사하지만, 네 개 평균이 아니라 단일 metric 기준으로 best를 선택한다.
- SFT-Acc
- SFT-LLMEval
- SFT-ROUGE
- SFT-BERT
Ext2Gen-{Rule}
- 단일 참조를 사용하는 SFT와 달리, 동일한 질문에 대해서도 여러 pairwise 피드백을 학습 신호로 활용한다.
- 두 가지 피드백 구성 규칙에 따라 DPO로 모델을 최적화하며, Ext2Gen-R1은 inclusion metric만 사용하고, Ext2Gen-R2는 inclusion과 similarity metric을 모두 사용한다.
- DPO 외에도 다른 alignment 튜닝 방법을 적용할 수 있는데, 이후 파트에서 KTO 및 SimPO와 비교한다.
📍3. Evaluation
3.1 Robustness Evaluation
Configuration
- 목표는 생성 백본의 강건성을 직접 향상시키는 것이기 때문에, 주로 Ext2Gen-R1/R2 두 주요 모델을 SFT를 적용하거나 적용하지 않은 다른 변형들과 비교한다.
- SFT와 DPO 모두에 대해, 주로 Llama3.2-3b-instruct와 Llama3.1-8b-instruct를 QLoRA를 사용하여 네 개의 NVIDIA H100 GPU에서 파인튜닝한다.
- 모든 설정에서 일관성을 유지하기 위해, 학습은 9,000 스텝 동안 진행되며, 옵티마이저는 AdamW를 사용하고, 배치 크기는 32, 초기 학습률은 5e-6, weight decay는 0.05로 설정한다.
- 평가 지표로는 Acc, LLMEval (GPT-4o 사용), ROUGE-L, BERTScore의 네 가지 지표를 사용한다.
Test Dataset
- QA 생성에서의 강건성을 평가하기 위해 Ext2Gen 학습 데이터와 동일한 파이프라인을 사용하여 테스트 세트를 구성하되, 다섯 개 소스 데이터셋의 “test split”을 사용한다.
- 입력만 필요하기 때문에, 테스트셋에 대해서는 학습 데이터셋을 구성하는 절차들 중에서 input consolidation 단계까지만 수행한다.
- 그 결과 총 1,000개의 QA 쌍이 생성되며, 다섯 개 소스 데이터셋 각각에서 200개의 QA 쌍을 샘플링하거나 생성한다.
- Ext2Gen 입력 프롬프트에서는 각 질문이 관련 청크와 최대 25개의 비관련 청크를 모두 포함한 청크 리스트와 함께 제공된다는 점에 유의해야 한다.
3.1.1 Main Results
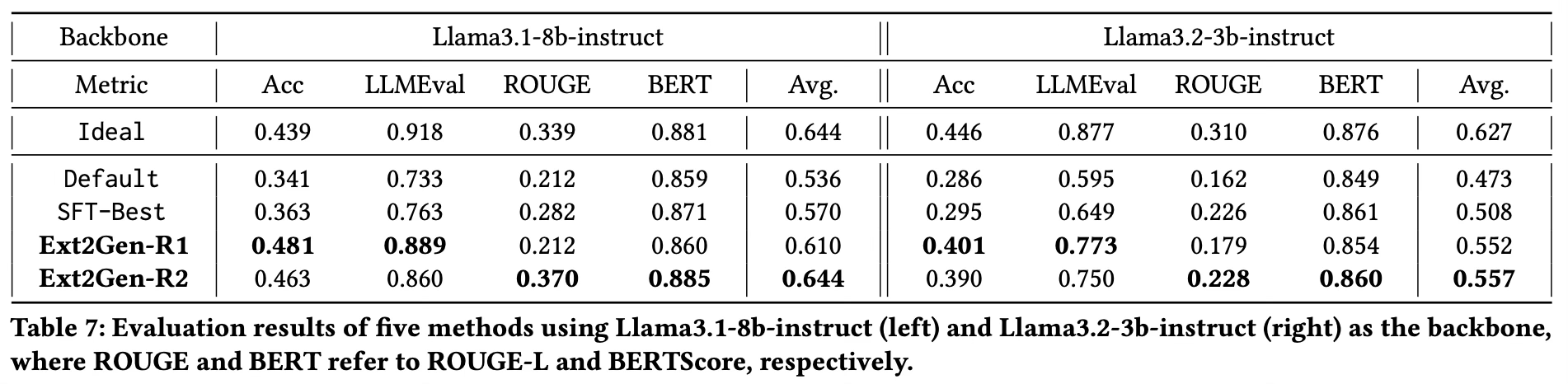
- Default(기본 모델)은 Table 1의 Ext2Gen 프롬프트를 사용하되 preference alignment 없이, 즉 SFT나 DPO를 적용하지 않은 결과를 의미하며, Ideal은 Default 설정에서 chunk 리스트에 관련 청크만 제공했을 때의 결과를 의미한다.
- 첫째, 기본 모델(Default)은 정보 망각과 정보 노이즈에 매우 민감하여 상당한 성능 하락을 겪으며, 특히 Llama3.2-3b-instruct와 같은 소형 모델에서 그 현상이 두드러진다.
- Information forgetting : relevant chunk가 중간에 위치하면 잊어버림 (lost-in-the-middle)
- Information noisiness : irrelevant chunk가 attention 분산
- 둘째, Ext2Gen을 통한 alignment는 모든 QA 지표에서 생성 성능을 크게 향상시킨다.
- 특히, 구성된 pairwise 피드백을 활용하면 단일 최고 출력만 사용하는 SFT-Best보다 Ext2Gen 시리즈가 훨씬 더 큰 향상을 보인다.
- 마지막으로, Ext2Gen-R2는 inclusion과 similarity 지표를 균형 있게 사용하는 것이 더 나은 Pareto alignment를 유도하며, 평균 점수 기준으로 가장 우수한 모델을 만든다는 것을 보여준다.
- Pareto alignment란 한 metric 개선이 다른 metric을 희생하지 않는 상태
- Llama3.1-8b-instruct를 사용할 경우, Ext2Gen-R2는 입력에 최대 25개의 비관련 청크가 추가되었음에도 불구하고 noise-free Ideal 모델과 거의 구분되지 않는 성능을 달성하며 강한 강건성을 보여준다.
- 한편, Ext2Gen-R1은 inclusion 지표에서는 Ext2Gen-R2를 능가하지만, similarity 지표에서는 뒤처진다.
3.1.2 Robustness against Relevant Chunk Position and Information Noisiness

- Figure 2는 입력 프롬프트 내에서 관련 청크의 위치(왼쪽)와 추가된 비관련 청크의 수(오른쪽)에 따라 네 가지 지표의 평균 점수(Avg.)가 어떻게 변화하는지를 보여준다.
- Ideal 모델은 입력에 관련 청크만 포함되어 있기 때문에 청크 위치 변화나 정보 노이즈의 영향을 받지 않고 일정한 점수를 유지한다는 것이다.
- 관련 청크 위치에 대한 실험에서, Ext2Gen-R2는 입력 내 관련 청크의 모든 위치에 걸쳐 다른 모든 방법을 지속적으로 능가하며, 심지어 Ideal 기준을 초과하기도 한다.
- 이는 중요한 정보의 위치 변화에 적응하는 강력한 능력을 보여주며, 이는 관련 내용이 예측 불가능한 위치에 나타날 수 있는 실제 검색 환경에서 매우 중요하다.
- 마찬가지로, 비관련 청크 추가로 인한 정보 노이즈 상황에서도 Ext2Gen-R2는 성능 저하에 대해 뛰어난 저항성을 보인다.
- 이는 다른 모든 기준 모델보다 현저히 높은 점수를 유지하며, 어려운 노이즈 환경에서도 관련 증거에 집중하고 노이즈를 걸러내는 향상된 능력을 반영한다.
- 이게 바로 alignment의 효과
3.1.3 Comparison with Compression Method
- 생성 모델 자체의 강건성을 직접 향상시키는 데 초점을 맞춘다.
- Robustness는 retrieval 단계가 아니라 generation 모델 내부에서 해결해야 한다.
- 의도는 다르지만, Recomp, CompAct, 그리고 EXIT는 retrieval과 generation 사이에 독립적인 필터링(압축) 모듈을 두어 가장 관련 있는 정보만 추출한다.
- 비록 생성 모델 자체를 직접 대상으로 하지는 않지만, 이들의 사전 필터링 전략은 노이즈나 비관련 입력이 생성 품질에 미치는 영향을 줄이려 한다는 점에서 개념적으로 본 연구와 관련이 있다.

- 따라서 Ext2Gen을 세 가지 압축 방법과 더불어, GPT-4o를 압축 모델로 사용하여 Table 8의 특수 프롬프트를 적용한 GPT-Filter와 비교한다.
- 이 방법들은 생성 이전 단계에서 검색된 청크를 압축하는 반면, Ext2Gen은 정렬 튜닝을 통해 문장 선택을 생성 단계 내부에 통합한다.
- 따라서 Ext2Gen은 별도의 독립 모델이 필요 없으며, 증거 선택을 답변 품질과 직접적으로 연결한다.
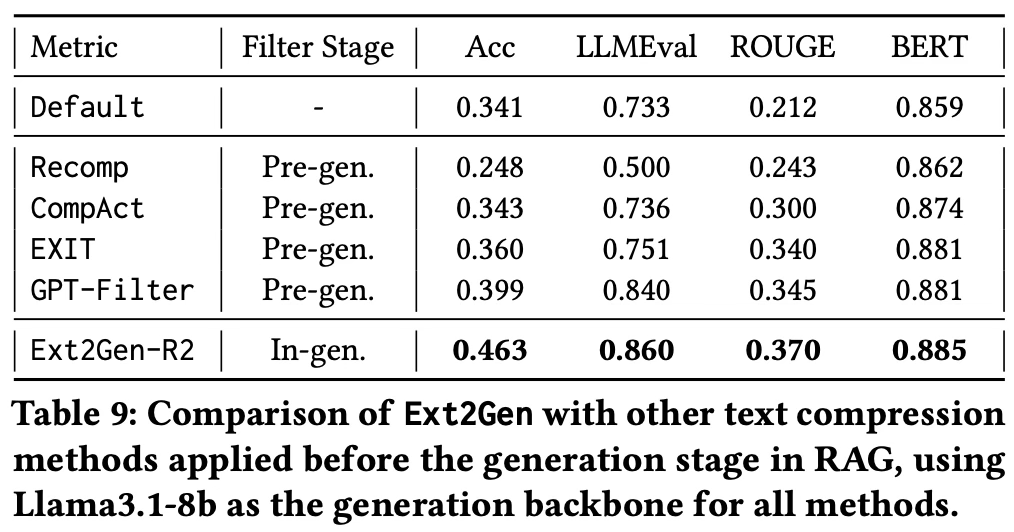
- Table 9는 요약된 텍스트만 생성 모델에 제공하는 네 가지 사전 압축 방법과 Ext2Gen의 QA 성능을 비교한다.
- Ext2Gen-R2가 모든 지표에서 사전 압축 방법들을 능가한다.
- 생성 단계 내부의 필터링은 모델이 정적인 사전 선택 문맥에 의존하는 대신, 답변을 생성하면서 동적으로 문장 선택을 조절할 수 있게 한다.
3.1.4 Additional Analysis
- 이 파트에서는 추출된 문장의 품질과 효율성을 평가하는 것, 다양한 피드백 튜닝 전략을 비교하는 것, 그리고 여러 최적화 기법과 모델 백본에 걸쳐 Ext2Gen의 강건성을 테스트하는 것이 포함된다. (Ext2Gen의 일반화 가능성과 실용적 장점을 강조)
Quality of Extracted Sentences

- Table 10에서는 세 가지 지표를 사용하여 추출 문장의 품질을 평가한다.
- Precision은 추출된 문장 중 관련 청크에서 유래한 문장의 비율을 측정하며, 모델이 얼마나 정확하게 올바른 출처에서 내용을 선택하는지를 나타낸다.
- Precision = (관련 청크에서 추출된 문장 수) / (전체 추출 문장 수)
- Recall은 최소 한 개 이상의 추출 문장을 포함하는 관련 청크의 비율을 측정하며, 모델이 필요한 정보를 얼마나 포괄적으로 다루는지를 반영한다.
- Recall = (추출된 relevant chunk 수) / (전체 relevant chunk 수)
- 마지막으로, 전체 추출 성능을 요약하기 위해 precision과 recall의 조화 평균인 F1 점수를 보고한다.
- Ext2Gen-R1은 inclusion 기반 지표만으로 구성된 피드백으로 학습되었기 때문에, 정답을 포함할 확률을 높이기 위해 더 긴 응답을 생성하는 경향이 있으며, 그 결과 recall은 높지만 precision은 낮다.
- 반면 Ext2Gen-R2는 inclusion 지표뿐 아니라 lexical similarity 지표도 포함하여, 정확할 뿐 아니라 간결하고 참조 답변과 유사한 응답을 유도한다.
- 이는 precision과 recall 사이의 더 나은 균형을 만들어내며, 결국 가장 높은 F1 점수를 달성한다.
Output and Latency

- Table 11은 단일 NVIDIA H100 GPU에서 배치 크기 1로 측정한 Ext2Gen 계열과 Default 모델의 출력 통계 및 지연 시간을 제시한다.
- ROUGE와 같은 lexical similarity 지표를 inclusion 지표와 함께 포함하는 Ext2Gen-R2는 더 간결한 추출 문장과 답변을 생성한다.
- 이는 출력 품질을 향상시킬 뿐 아니라 Default보다 더 빠른 추론 속도를 낳는다.
- 반면 ACC와 LLMEval과 같은 inclusion 기반 피드백만으로 학습된 Ext2Gen-R1은 더 많은 문장을 추출하고 더 긴 출력을 생성하며, 이는 더 높은 recall을 가져오지만 지연 시간 증가와 낮은 precision을 초래한다.
- 이 결과는 Ext2Gen-R2처럼 피드백 구성 시 lexical similarity와 inclusion 지표를 모두 고려하는 것이 강건성을 향상시킬 뿐 아니라, 더 간결하고 집중된 추출 덕분에 지연 시간 감소에도 유익하다는 것을 시사한다.
SFT Variants
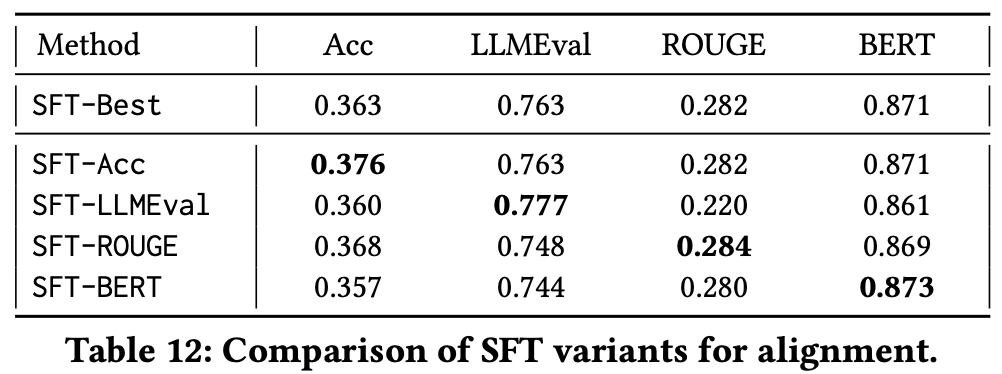
- Table 12는 단일 QA 지표를 사용하여 피드백을 구성한 다른 SFT 변형들과 Ext2Gen-R2를 비교하며, 이때 Llama3.1-8b-instruct가 사용된다.
- 단일 지표에 집중하면 alignment tax가 발생하여 다른 QA 지표에서 성능 저하가 나타날 수 있다.
- Alignment Tax : 특정 metric만 최적화하면 그 metric은 올라가지만 다른 metric은 떨어질 수 있음
- 각 변형은 자신이 목표로 한 지표에서는 우수한 성능을 보이지만, 다른 지표에서는 저조한 성능을 보이는 경향이 있다.
- 예를 들어, SFT-LLMEval은 LLMEval 점수는 가장 높지만 ROUGE-L 점수는 가장 낮으며, 반대로 SFT-ROUGE는 ROUGE-L을 극대화하지만 LLMEval을 희생한다.
Generalization to Optimization Method
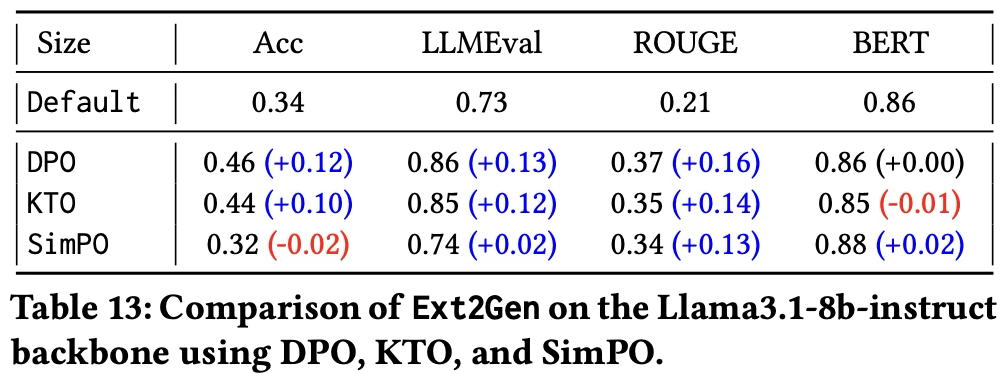
- KTO는 쌍(pairwise) 선호 데이터를 이진 피드백(“1”은 바람직함, “0”은 바람직하지 않음)으로 대체하므로, pairwise 데이터셋을 KTO용 이진 형태로 변환한다. (단일 출력에 대해 binary label만 필요)
- 반면 SimPO는 참조 모델이 필요 없으며, 평균 로그 확률을 암묵적 보상으로 사용하여 생성 지표와의 정렬을 개선하면서 계산 및 메모리 비용을 줄인다.
- 모든 방법이 QA 성능을 향상시키지만, DPO는 Acc, LLMEval, ROUGE-L에서 가장 높은 향상을 보이며, 이것이 저자들이 주요 실험에서 DPO를 기본 방법으로 채택한 이유이다.
- KTO는 pairwise 선호 데이터 대신 이진 레이블만 사용함에도 불구하고 DPO와 비교 가능한 성능을 보인다.
- 이는 KTO가 피드백 구성을 단순화함으로써 더 효율적인 대안을 제공할 수 있음을 시사한다.
Generalization to Other Backbone

- Table 14는 Qwen 백본에서 학습된 네 가지 접근 방식(Ideal, Default, SFT-Best, Ext2Gen-R2)에 대해 네 가지 평가 지표에 걸친 QA 성능을 보고한다.
- 전반적으로 Ext2Gen-R2는 기준 모델들을 지속적으로 능가하며, 특히 Acc와 LLMEval이라는 두 핵심 지표에서 Default 대비 두드러진 향상을 보인다.
- 이 결과는 Ext2Gen 프레임워크가 서로 다른 아키텍처에 걸쳐 전이 가능함을 확인해준다.
3.2 Deployment to RAG
Test Datasets
- 이전 실험들이 일부 LLM 생성 QA에 의존했던 것과 달리, 이번 평가는 전적으로 사람이 작성한 QA를 사용하여 모델 성능에 대해 더 현실적이고 엄격한 평가를 수행한다.
- Ext2Gen-R2를 실제 RAG 환경에 배치하여, 대규모 코퍼스를 저장한 벡터 데이터베이스에서 텍스트 청크를 온라인으로 검색하고, 해당 질의와 Top-𝐿 검색 청크를 LLM에 입력한다.
- 세 가지 인간 주석 기반 RAG 벤치마크—Natural Questions (NQ), MS-MARCO, HotpotQA—각각에서 200개의 질의-답변 쌍을 샘플링하여 총 600개의 예시를 구성한다.
- 검색 코퍼스로는 BEIR 벤치마크를 따르며, NQ와 HotpotQA에 대해 각각 270만 개와 500만 개의 텍스트 청크를 사용하고, MS-MARCO에 대해서는 8,800만 개 청크를 사용한다.
Retrieval
- 각 질의에 대해 Top-K 텍스트 청크를 검색하며, K는 {10, 20, 30}으로 변화시킨다.
- 모델의 일반화 능력을 평가하기 위해, 세 가지 검색 방법을 적용한다.
- multilingual-e5-large-instruct 모델을 사용하는 기본 밀집 검색기인 Naive, 그리고 쿼리 재작성(query rewriting)을 통합한 두 고급 검색기인 HyDE와 MuGI이다.
- 검색된 청크들은 Ext2Gen 프롬프트에 추가되어 핵심 문장을 추출하고 최종 답변을 생성하는 데 사용된다.
- 중요하게도, 쿼리 재작성이 포함된 향상된 검색 방법을 포함함으로써, 검색 결과의 품질이 높고 노이즈가 적은 상황에서도 Ext2Gen이 여전히 상당한 성능 향상을 제공하는지를 검증하고자 한다.
4.2.1 Main Results
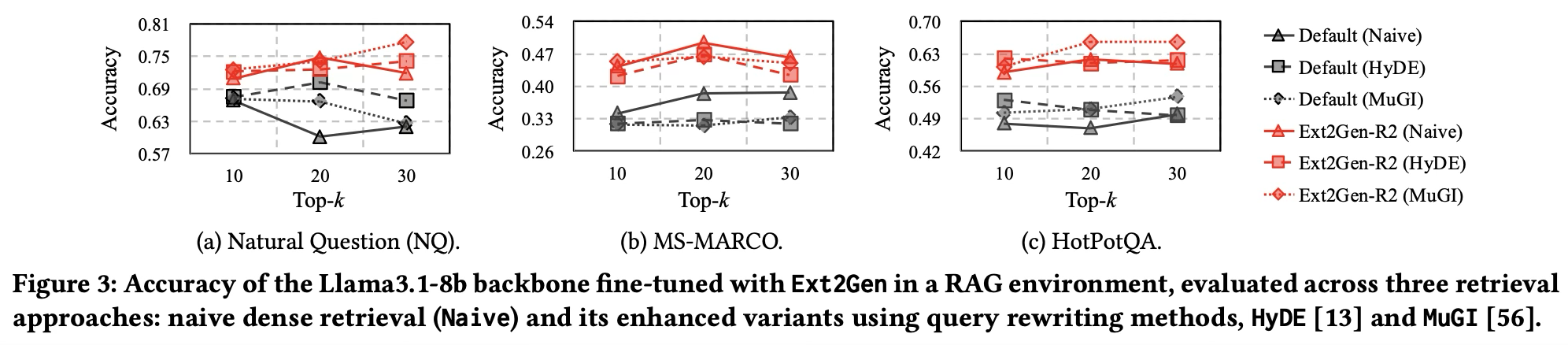
- 첫 번째 구성은 표준 Llama3.1-8b-instruct 백본(Default)을 세 가지 검색 방법과 함께 사용하고, 두 번째 구성은 동일한 백본을 Ext2Gen-R2로 학습한 모델을 사용한다.
- 핵심 관찰은 Top-K를 증가시키면 더 많은 관련 청크가 포함되어 검색 recall이 향상된다는 것이다.
- 그러나 Default 모델은 NQ에서는 정확도가 감소하고, HotPotQA에서는 미미한 향상만을 보인다.
- 이는 Top-K가 증가함에 따라 검색 precision이 감소하고, 더 많은 노이즈가 입력에 포함됨을 시사한다.
- Default 모델은 이러한 노이즈 정보를 걸러내는 데 어려움을 겪으며, 관련 청크의 위치에도 민감하여 추가로 검색된 내용을 효과적으로 활용하는 데 한계를 보인다.
- 반면 Ext2Gen-R2는 검색으로 인한 노이즈와 불확실한 청크 위치에도 불구하고 일관된 답변을 요구하는 인간의 기대와의 정렬 격차를 효과적으로 해소하며 강한 강건성을 보여준다.
- 또한 Ext2Gen-R2는 기본 검색(Naive)에서도 잘 작동하지만, 고급 쿼리 재작성 방법(HyDE, MuGI)과 결합할 경우 더욱 큰 향상을 보이며 NQ와 HotPotQA에서 가장 높은 정확도를 달성한다.
📍4. Conclusion
- retrieval 노이즈와 청크 위치 불확실성에 대한 RAG의 강건성을 향상시키는 extract-then-generate 프레임워크인 Ext2Gen을 제안한다.
- 잘 선별된 데이터로 구성된 preference-aligned pairwise 피드백을 활용함으로써, 문장 추출에서 precision과 recall의 균형을 맞추고 더 신뢰할 수 있는 답변 생성을 달성한다.
- 이 접근 방식은 독립적인 압축 모듈의 필요성을 제거하며, 따라서 그 성능 향상은 특히 의미가 있다.
'Paper Review > RAG' 카테고리의 다른 글
'Paper Review/RAG' Related Articles
more



