

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- odds
- LLM
- Hallucination
- GPT
- qwen
- moe
- Noise
- Embedding
- retrieval
- Statistics
- Document Augmentation
- Parametric RAG
- fine-tuning
- 파인튜닝
- NLP
- SFT
- DPO
- Do it
- Baekjoon
- DyPRAG
- coding test
- Transformer
- Algorithm
- Python
- RAG
- reranking
- Noise Robustness
- lora
- COT
- Retriever
- Today
- Total
왕구아니다
[논문 리뷰] Dynamic Parametric Retrieval Augmented Generation for Test-time Knowledge Enhancement 본문
[논문 리뷰] Dynamic Parametric Retrieval Augmented Generation for Test-time Knowledge Enhancement
Psalms 12:6-7 2026. 1. 28. 21:54본 논문 리뷰는 저의 개인적인 해석과 의견을 바탕으로 작성된 글입니다.
내용 중 해석의 오류나 개념적인 착오가 있다면, 망설이지 마시고 댓글로 혼내주시면 감사하겠습니다~
‼️ 본 논문은 "Parametric Retrieval-Augmented Generation"이라는 논문을 변형한 논문이므로 해당 논문을 먼저 읽고 아래 포스팅된 내용들을 읽어보시는 것을 추천드립니다~ (중간중간 본 논문에 작성된 자세한 P-RAG 내용은 생략하겠습니다)
https://wanggyuuu.tistory.com/13
[논문 리뷰] Parametric Retrieval Augmented Generation
본 논문 리뷰는 저의 개인적인 해석과 의견을 바탕으로 작성된 글입니다.내용 중 해석의 오류나 개념적인 착오가 있다면, 망설이지 마시고 댓글로 혼내주시면 감사하겠습니다~Preview- 문서를 입
wanggyuuu.tistory.com
Preview
- Parametric RAG 논문에서의 Offline 과정을 hypernetwork로 재구성
- parameter translator라는 MLP hypernetwork를 학습시켜 동적으로 inference 과정에서 검색된 문서의 LoRA를 생성해 LLM에 바로 주입시켜주는 방법론
Link
- 논문 : https://arxiv.org/abs/2503.23895
- 코드 : https://github.com/Trae1ounG/DyPRAG
GitHub - Trae1ounG/DyPRAG: [arxiv: 2503.23895] Dynamic Parametric Retrieval Augmented Generation for Test-time Knowledge Enhance
[arxiv: 2503.23895] Dynamic Parametric Retrieval Augmented Generation for Test-time Knowledge Enhancement - Trae1ounG/DyPRAG
github.com
Abstract과 Introduction은 RAG/PRAG에 대한 배경 지식이므로 생략하겠습니다~
📍3. Methodology
- 기존 PRAG의 목표는 문서 di마다 증강과 학습을 통해 성능이 좋은 매핑 함수 F를 얻는 것
- 그러나 새로운 문서나 질의가 들어올 때마다 동일한 절차를 반복해야 하므로, 계산 자원과 시간이 많이 들어 현실적인 환경에서는 비효율적
- 따라서 본 논문의 Motivation Question : ‼️ How to obtain a generalized mapping function F?
- 효율적이고 효과적인 파라미터 주입을 가능하게 하는 3단계 동적 프레임워크를 제안

Stage 1) Doc-Param Pairs Collection
- 문서-파라미터 쌍(di-pi)을 수집하는 것부터 시작
- 이때는 PRAG에서 사용한 문서를 파라미터화 시키는 과정과 동일하게 수행해서 문서-파라미터 쌍을 구성
- 각 문서(di)마다 증강 + QA pairs를 생성해서 LoRA를 학습시키는 과정을 의미

Stage 2) Dynamic Parametric RAG Training

- 위에서 K를 구성했으면, 이젠 각 문서 di를 임베딩 시키자
- 이때 LLM을 사용하는데, Transformer 마지막 hidden state에서 단어 분포로 변환되기 직전의 은닉 상태 si(차원 h)를 추출
- 문서와 파라미터 사이의 내재된 관계를 모델링하기 위해, 파라미터 변환기(Parameter Translator)라 불리는 간단한 하이퍼네트워크설계.
- 이 변환기를 통해 si를 parameteric representation으로 변환
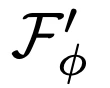
- 이 하이퍼네트워크는 기본 파라미터 Φ로 구성된 여러 개의 linear layer로 이뤄져있음(MLP 기반 초경량 네트워크)
- (Figure 13) 예시로 FFN의 up-project 모듈을 생각해보자

- DyPRAG의 목표는 LoRA 기본 수식에 있는 행렬 B와 A를 직접 학습하는 게 아니라, Parameter Translator가 생성하게 만드는 것
- 학습 시 Parameter Translator는 각 문서의 임베딩(si)을 입력받아 특정 레이어(l)의 LoRA 행렬 Bl (또는 Al)을 생성





- 이 과정은 모든 layer에 적용되기 때문에 처음에 각 문서 임베딩 si에 layer index를 concat해줌
- A에 대해서도 위 B 수식과 동일하게 수행됨
- 결국 목표는 이 parameter translator를 위에서 구성한 K안에 있는 각 문서의 파라미터 pi(정답)에 근사하게 각 문서의 임베딩 si를 넣었을 때 새로운 LoRA(p̂i) 파라미터를 생성할 수 있도록 학습시키는 것

- Parameter Translator가 뱉어낸 파라미터(p̂i)가 정말 쓸모 있는지 3가지 Loss의 조합해 판단

- (1) L_pred : Parameter Translator가 생성한 파라미터를 LLM에 끼워 넣었을 때, 모델이 질문에 대한 정답을 잘 생성하는가
- PRAG와 동일하게 증강 데이터 Di와 목적함수 사용


- (2) L_mse : 생성된 파라미터(pi)와 목표 파라미터(p̂i) 사이의 차이를 MSE로 계산
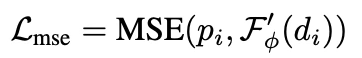
- (3) L_kl : 진짜 LoRA(pi)를 꼈을 때의 단어 확률 분포와 생성된 LoRA(p̂i)를 꼈을 때의 단어 확률 분포가 얼마나 유사한지(KL Divergence)를 측정
- 단순히 파라미터 숫자(L_mse)만 비슷하다고 해서 모델의 출력 결과가 같다는 보장 없음

- 위 3개의 loss의 합으로 최종 loss를 계산하는데, 각 문서 di마다 계산을 하고 감마 1,2는 조절 가능한 하이퍼파라미터로 각 손실 항의 값 범위를 비슷하게 맞추기 위해 각각 100과 0.01로 설정
Stage 3) Dynamic Parametric RAG Inference
- 테스트 쿼리(질문) q^t가 주어지면, 가장 관련성 높은 문서들을 선택하기 위해 검색 모듈 R(여기선 BM25사용)을 사용
- 그리고 선택된 각 문서 di^t에 대해 문서의 임베딩 si^t를 추출하고 이를 parameter translator에 입력하여 동적 LoRA 어댑터 p̂i를 얻음 (Figure 2 참고)
- 결국 PRAG처럼 문서의 핵심 정보를 텍스트 형태가 아니라 '모델 파라미터 형태(parameter modality)'로 저장
- 그런 다음 병합(merge)
Computation Cost

- 기존 PRAG의 offline cost : 총 12|d|
- 데이터 증강 : 문서 d의 평균 토큰 수를 |d|라고 가정하면, 증강 과정은 일반적으로 약 2|d|개의 토큰을 추가로 생성하므로, (입력 토큰과 합쳐) 총 3|d|만큼의 증강 비용이 발생
- LoRA를 학습 : 3|d|개의 토큰에 대한 순전파 비용과 6|d|개의 토큰에 해당하는 역전파(통상 순전파 비용의 2배) 비용이 드므로, 총 학습 비용은 9|d| (3(순전파) + 6(역전파) = 9)
- 단점 : 여전히 오랜 시간이 소요되며, 새롭게 검색된 문서를 동반하는 새로운 질문들에는 (미리 학습된 파라미터가 없으므로) 일반화하여 적용할 수 없음. 재학습 필요
- 이와 대조적으로, DyPRAG은 오직 N개의 '문서-파라미터(Doc-Param)' 쌍만을 필요로 하며, 작은 크기의 N만으로도 강력한 (일반화)성능을 달성할 수 있어 증강 및 학습 비용을 획기적으로 줄일 수 있음 (❓근데 애초에 문서-파라미터 쌍 자체를 만들려면 PRAG처럼 LoRA 학습이 필요하지 않나....)
- 그리고 MLP기반인 parameter translator의 연산 비용은 Transformer 기반의 거대 언어 모델(LLM)에 비하면 계산량 미미
- 기존 PRAG의 가장 주된 이점은 추론 비용의 감소(DyPRAG도 동일)
- |q|를 질문의 길이로, c를 검색된 문서의 개수
- PRAG와 DyPRAG의 추론 시 입력 문맥 길이는 오직 질문 길이인 q뿐, 문맥 내 주입(in-context injection) 방식을 쓰는 기존 RAG는 c|d| + |q|만큼의 긴 문맥을 필요
- 따라서 문서를 파라미터화시켜 주입시키는 방식은 추론 비용을 상당히 줄여주는데, 문서 길이(d)와 문서 개수(c)가 늘어날수록 그 비용 절감 효과가 더욱 커짐(반대로 RAG는 비용 더 늘어남)
- 주목할 만한 점은, 추론 비용이 모델이 생성하는 응답(답변)의 길이와도 밀접하게 연관되어 있다는 것 (Comparison of Response Length)
- 추론 비용을 계산할 때 오직 '문맥 길이(입력되는 텍스트의 길이)'만을 고려했었는데, 하지만 실제 사용 환경에서는 LLM이 생성해내는 '응답(출력)의 길이' 또한 추론 시간에 (큰) 영향을 미침
- 4개의 벤치마크 데이터셋에 걸쳐 '평균 응답 길이'를 기준으로 DyPRAG-Combine과 (기존) RAG를 비교한 결과, DyPRAG-Combine은 응답 길이를 유의미하게 줄였는데, 2WQA 데이터셋에서는 20% 줄였고, CWQ 데이터셋에서는 무려 최대 90%까지 감소함
- 이는 DyPRAG-Combine이 더 적은 토큰(단어)만으로도 질문에 올바르게 대답할 수 있음을 증명한 것이고, 결과적으로 추론 비용을 낮추고 불필요한(중복된) 정보를 피할 수 있음을 보여줌
- 모델이 지식을 파라미터로 확실히 알고 있으면(내재화), 주저리주저리 설명하거나 환각을 섞지 않고 "핵심 정답만 간결하게" 말함

Storage Cost

- PRAG의 주요 단점 중 하나는 문서별 파라미터인 pi와 관련된 저장 비용 (각 문서의 파라미터를 저장해야됨)
- r을 LoRA의 랭크, L을 트랜스포머 레이어의 수, h를 히든 사이즈(차원 크기), 그리고 k를 FFN의 중간 크기
- 문서 하나에 대한 파라미터 표현(LoRA)에 들어가는 총 파라미터의 수는 6Lr(h+k)
- 예를 들어, Qwen2.5-1.5B 모델(28개 레이어, 히든 차원 1536, 중간 크기 8960)의 경우, 랭크 r을 2로 설정하면 문서 하나당 약 353만(3.53M) 개의 파라미터가 생성되며, 이는 16비트 정밀도로 저장할 때 약 6.73MB를 차지
- 실제로 저자들이 실험한 환경에서는(문서가 많으므로) Qwen2.5-1.5B 모델을 위해 18.66GB에 달하는 오프라인 파라미터를 저장함
- DyPRAG는 오직 Parameter Translator의 가중치만 저장하면 됨
- Parameter Translator의 중간 크기 p를 2로 설정하고, up-proj, down-proj, gate-proj 각각에 대해 별도의 Parameter Translator를 구성한다고 할 때, Qwen2.5-1.5B 모델에 대한 총 파라미터 수는 3L(phr +2p(h+1)+pkr)
- 이를 계산하면 약 404만(4.04M) 개의 파라미터가 되며, 16비트 정밀도로 저장 시 단 7.71MB만을 차지하는데, 이는 PRAG 방식 대비 0.04%에 불과한 수준
📍4. Experiments
4.1 Experiments Details
Datasets
- QA Datasets
- 2WikiMultihopQA (2WQA), HotpotQA (HQA), PopQA (PQA), ComplexWebQuestions (CWQ) / PRAG와 동일
Evaluation Metrics
- F1 Score 사용
- PRAG와 동일하게 2WQA는 질문 유형에 따라 4개 카테고리로, HQA는 2개로 나눔
- 모든 데이터셋은 첫 300개(평가 질문 개수) 질문 사용
LoRA for parameter translator
- parameter translator 학습용으로 평가 질문 300개와 겹치지 않게 200개를 추가로 뽑고 각 질문마다 Wikipedia dump에서 문서 3개씩 검색
- 문서 증강을 위해 각 문서는 한 번씩 재작성되었고, 각 문서를 기반으로 세 개의 QA 쌍이 생성
- 따라서 K는 총 4,800쌍으로 구성됨 (200(질문 수) * 3(질문마다 문서 수) * 8(QA 데이터셋))
- LoRA 모듈은 FFN행렬에만 적용. Query, Key, Value(QKV) 행렬에는 적용하지 않음
- 스케일링 계수 32, LoRA 랭크 r은 2로 설정하였고, 학습 안정성을 보장하고 파라미터 업데이트를 최대화하기 위해 dropout은 적용하지 않음
- LoRA 가중치는 원래의 LoRA 논문에서 제시한 설정에 따라 무작위 초기화
- LoRA 미세조정 과정에서 학습률은 3 × 10⁻⁴로 설정하였고, 학습은 1 epoch 동안 수행 (단, PQA는 2 epoch)
Training parameter translator
- embedding을 adapter parameters로 바꾸는 MLP 사용
- 학습률은 1 × 10⁻⁵
- epoch은 1
- intermediate size p는 32
- 입력 텍스트의 최대 길이는 3000으로 설정, 대부분의 위키 문서는 이보다 짧기 때문에 문서 손실 없이 거의 그대로 파라미터화함
- [아래 Table 1]에서 보고된 Qwen2.5-1.5B 및 LLaMA3.2-1B의 성능은 4,800개의 학습 샘플 학습한 결과. LLaMA3-8B는 2,400개의 샘플로 학습되었고 (단, 2WQA 데이터셋에 대해서는 480개 샘플만 사용)
Inference Settings


- DyPRAG와 모든 baselines 똑같은 프롬프트 템플릿 사용
- 모두 greedy decoding 사용
- max number of new tokens는 128
Retrieval Module R
- Elasticsearch로 BM25 구현
4.2 Main Results
Overall Analysis

- LLaMA3.2-1B를 사용했을 때 DyPRAG는 평균 27.57%의 점수를 기록하며, PRAG보다 1.06%, 표준 RAG보다 0.58%, vanilla 모델보다 5.18% 더 높은 성능을 보임
- 2WQA의 bridge 서브태스크에서 주목할 만한 결과가 나타났는데, DyPRAG는 48.15%의 점수를 기록하며, RAG와 PRAG를 각각 21.37%, 23.81%라는 큰 차이로 압도

- 다른 RAG 모델인 DRAGIN과 FLARE보다 성능 높게 나옴
- FLARE : LLM이 답을 생성하다가 확신 없는 토큰을 감지하면 그 시점에서 다시 retrieval을 수행하는 방식
- DRAGIN : 단순히 uncertainty가 아니라 이 불확실성이 뒤 토큰 생성에 큰 영향을 주는가?를 판단
- 결과를 보면 작은 모델에서는 FLARE와 DRAGIN 방법이 효과적이지 않음. 즉 모델 자체의 능력에 영향을 많이 받음. 그러기 때문에 generalized하다고 말할 수 없음
-
- LLaMA3-8B를 기반 모델로 사용했을 때, DyPRAG는 2WQA에서 DRAGIN과 FLARE보다 각각 1.56%, 2.63% 더 높은 성능을 보임
- 이러한 결과는 테스트 시점에 문서를 검색해서 보완하는 모델들보다 테스트 시점 지식 강화 측면에서 더 효과적이다(지식을 파라미터로도 같이 주기 때문에 더 강건)
DyPRAG-Combine Leads to Superior Performance
- DyPRAG-Combine은 평균적으로 PRAG-Combine보다 LLaMA3.2-1B에서는 1.86%, Qwen2.5-1.5B에서는 0.46%, LLaMA3-8B에서는 1.08% 더 높은 성능을 기록
- 본 방법이 도입한 동적 파라미터가 문맥 지식과 효과적으로 통합되며, 두 정보원이 서로를 보완할 수 있도록 만든다는 것을 보여줌
4.3 Out-Of-Distribution (OOD) Performance
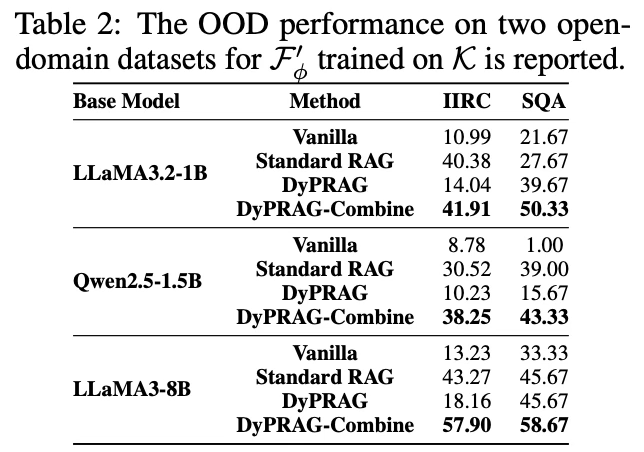
- 데이터
- StrategyQA (SQA)
- IIRC
- StrategyQA는 accuracy로 평가, IIRC는 f1 score로 평가
- StrategyQA는 zero-shot사용, IIRC는 few-shot 사용
- Vanila 보다 성능 높음
- 특히, 문서 기반 parametric 지식을 정답 문서와 함께 통합하는 DyPRAG-Combine은, 모든 시나리오에서 최고의 성능 달성
- 추가적인 오프라인 학습 없이는 OOD 시나리오를 처리할 수 없는 PRAG를 능가함을 보여줌
4.4 Effect of Intermediate Dimension p

- 위 Storage Cost 부분에서 확인했듯이, parameter translator의 전체 저장 비용은 3L(phr + 2p(h + 1) + pkr)이므로 p에 대해 선형적으로 증가
- [Table 3]에서 보이듯이, DyPRAG는 standard RAG와 PRAG 보다 항상 성능이 좋음
- 중요한 점은, p = 2는 단지 7.71MB의 저장 비용만으로 두 번째로 높은 성능을 달성
- 특히, DyPRAG는 standard RAG에 비해 추론 비용을 크게 줄이면서도, PRAG와 비교했을 때는 아주 적은 오버헤드(즉, 인코딩 및 변환 과정)만을 추가
- 반면, PRAG는 CWQ에서 300개의 테스트 질문에 대한 데이터를 저장하기 위해 672MB를 필요로 하여, 상당한 오버헤드를 유발
- 결론적으로 DyPRAG가 저장 비용을 획기적으로 줄일 뿐 아니라 과제 성능도 향상
4.5 Analysis of Contextual and Parametric Knowledge Conflict and Fusion
파라미터 주입과 문맥 주입을 결합했을 때(DyPRAG-combine) 왜 더 우수한 성능이 나타나는가?
Contextual + Parametric Knowledge Relieves RAG Hallucination

- [Table 4]를 보면 standard RAG와 DyPRAG 모두 오답을 말했지만, combine만 정답을 말함
- DyPRAG-Combine은 문맥 지식과 변환된 파라메트릭 지식을 효과적으로 통합함으로써, 올바른 답변을 제공할 수 있으며, 두 종류의 지식을 모두 효과적으로 활용할 수 있는 능력을 보여줌
- RAG와 비교했을 때, DyPRAG-Combine은 검색된 문서를 모델에 주입하기 전에 파라메트릭 지식으로 변환하므로 질문에 답할 때 LLM이 이미 관련 지식을 내재하도록 보장한다. 따라서 RAG에서 발생하는 hallucination을 방지함
DyPRAG Enables LLMs to Internalize Un-seen Knowledge

- RAGTruth 벤치마크를 사용하여,DyPRAG이 보지 못한 문맥 지식에 대해 어떻게 동작하는지를 추가로 분석
- RAGTruth 는 모델에서 발생하는 환각의 정도를 평가하기 위해 설계된 벤치마크 데이터셋
- 특히, RAGTruth의 일부 질문들은 제공된 문서를 반드시 활용해야만 답할 수 있도록 구성되어 있어 난이도가 더 높음
- RAGTruth에서 QA 유형 하위 데이터셋 100개를 무작위로 선택
- 흥미롭게도, 평가 과정에서 학습된 파라미터 수가 더 적은 parameter translator가 이러한 상황에서 오히려 더 좋은 성능을 보이는 것을 관찰함(오히려 일반화 잘됨)
- 구체적으로, LLaMA3.2-1B와 Qwen2.5-1.5B에 대해서는 480개의 예시만 학습하였고, LLaMA3-8B에 대해서는 240개의 예시만 학습
- [Figure 3]에서 보이듯이, DyPRAG-Combine은 RAG보다 현저히 뛰어난 성능을 보이는데, DyPRAG이 보지 못한 데이터를 다룰 때조차도, LLM이 문맥 지식을 더 잘 내재화하도록 하고 환각을 완화하는 데 효과적임을 보여줌


📍5. Appendix
Varying Number of Injected Documents

- [Figure 4] 결과를 보면 문서의 수가 많아진다고 DyPRAG의 성능이 드라마틱하게 변하지 않음
- 예를 들어, 2WQA와 CWQ 데이터셋에서는 상위 1개 문서만 사용할 때 최고의 성능을 보임
- 반면, HQA와 PQA와 같은 데이터셋에서는 문서 개수 c가 3일 때 최고의 성능이 관찰됨
- 이는 더 많은 관련 정보가 retrieval될 경우, LoRA 파라미터를 단순 평균하는 방식만으로도 지식을 효과적으로 통합할 수 있음을 시사
- 추가적으로, 네 개 데이터셋 중 PQA를 제외한 세 개 데이터셋에서는 문서를 지나치게 많이 주입할 경우 모델 성능이 저하됨
- 과제와 무관한 중복 정보가 모델 성능을 저하시킬 수 있음을 보여주며, 특히 문서 압축이 손실을 동반할 경우 그 영향이 더욱 큼
Effect of Doc-Param Pairs Siz

- Doc-Param 쌍으로 구성된 학습 데이터셋의 크기를 480에서 4800까지 증가시키며 실험 진행
- [Figure 5와 6]에서 보이듯이, DyPRAG는 단 480개의 학습 예제만으로도 강력한 성능을 달성. 크기가 커진다고 무조건 성능이 오르지 않음
Effect of Alignment Loss

- 위에서 parameter translator를 학습시킬 때의 Loss는 3가지를 결합해서 사용한다고 했다
- 3가지 Loss의 기여도를 분석해봄
- 결과는 [Table 7]에서 볼 수 있듯이, 어떤 단일 loss 항목을 제거하더라도 모델 성능은 저하됨
- 예를 들어, L_kl을 제거할 경우 모델 성능이 크게 하락
- 이는 목표 모델의 출력 분포와 정렬하는 것이 효과적인 전략
- LoRA 모양만 비슷하면 안되고 어떻게 말하느냐가 중요
- L_mse를 제거했을 때의 영향은 가장 작지만, parameter translator가 학습된 p에 최대한 가까운 new_p 값을 생성하도록 하는 것은 DyPRAG에 여전히 도움 됨
- 더 나아가, L_pred만 유지한 경우에도 DyPRAG는 안정적인 성능을 유지
- 표준 언어 모델링 손실이 전체 정렬 과정에서 중심적인 역할을 수행함을 시사
Comparison of Response Length
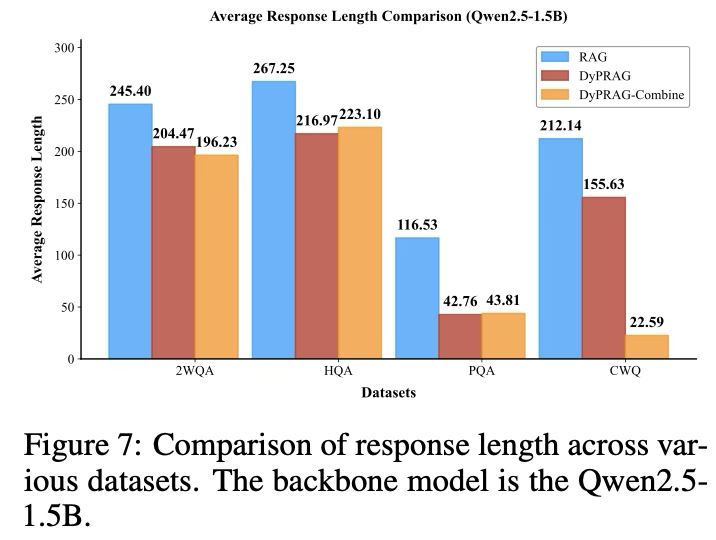
- 지금까지 추론 비용을 계산할 때 컨텍스트 길이만을 고려해왔는데, 실제 환경에서는 LLM의 응답 길이 또한 추론 시간에 영향을 미침
- DyPRAG-Combine은 응답 길이를 크게 줄이며, 2WQA에서는 약 20%, CWQ에서는 최대 90%까지 감소시킴
- 즉, 더 적은 토큰만으로도 질문에 정확히 답할 수 있음
- 결과, 추론 비용을 낮추고 중복된 정보를 피할 수 있음
Can Perplexity Reflects Knowledge Conflict?

- 최근 연구들은 다양한 지표를 활용하여 LLM 및 RAG 시스템에서의 환각을 탐지하는 방법을 탐구해왔음
- factuality score
- consistency
- confidence
- PPL, entropy, self-check 등
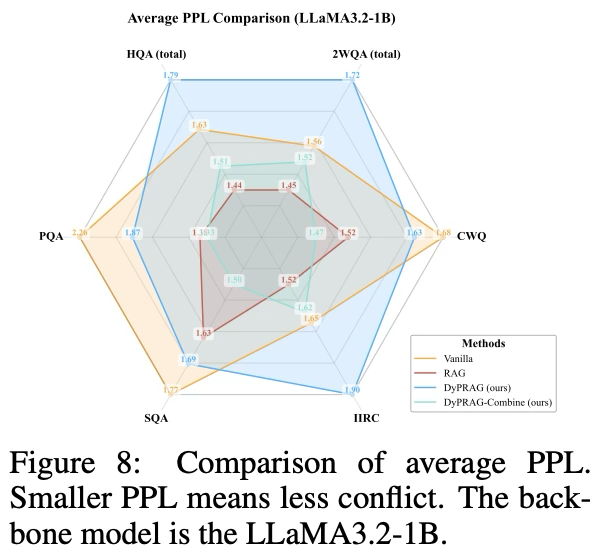
- 저자들은 먼저 단일 생성만으로 계산 가능한 가장 단순하면서도 효과적인 지표인 Perplexity(PPL)를 사용하여 지식 충돌을 평가[Figure 8]
- Perplexity(PPL)은 언어 모델이 어떤 문장을 얼마나 당황(perplexed)하는지를 수치로 나타낸 것
- 예를 들어
- PPL = 1 : 완벽 예측 (사실상 불가능)
- PPL = 10 : 평균적으로 10개 중 하나 고르는 느낌
- PPL = 100 : 엄청 헷갈림
- 예를 들어
- Perplexity(PPL)은 언어 모델이 어떤 문장을 얼마나 당황(perplexed)하는지를 수치로 나타낸 것
- 결과를 보면 Vanilla 모델과 DyPRAG는 더 높은 PPL을 보이는 반면, DyPRAG-Combine과 RAG는 현저히 낮은 PPL을 보임
- 그렇다면 DyPRAG는 불안정하고 DyPRAG-Combine / RAG는 안정적이라는 말인데 위에서 살펴본 본 논문의 QA 결과 Table1,2와는 결과(DyPRAG가 RAG보다 성능 좋음)가 다름
- 예를 들어, DyPRAG-Combine은 IIRC 데이터셋에서 최고의 성능을 달성했음에도 불구하고, 계산된 PPL은 더 높은 지식 충돌 가능성을 시사하는데, 이는 명백히 잘못된 해석
- 저자들은 이러한 불일치가 주로 DyPRAG에서 파라미터 주입으로 인해 발생하는 모델 파라미터 변화에서 비롯되며, 이는 단순한 PPL 방식으로는 탐지할 수 없기 때문이라고 가정
- DyPRAG의 본질 : test-time parameter change
- PPL의 전제 : 고정된 모델 분포
- 결론은 문장 전체 의미에 기여하는 정도가 토큰마다 다르다는 점을 고려할 때, 토큰 단위 불확실성의 평균으로 계산되는 PPL은 문장 전체의 불확실성을 효과적으로 포착하지 못한다
Effective Detection with Sentence-Level Metrics
- 저자들은 위에서 말한 PPL의 한계를 고려하여, 다중 생성 결과를 활용하는 대안적 지표들을 탐색
- 단일 입력에 대해 여러 출력을 생성하는 것이 문장 수준 불확실성을 추정하는 데 효과적이라는 점이 기존 연구를 통해 입증되었기 때문에 이 방법을 활용(모델이 확신할수록 여러 샘플이 비슷함)
- 실험은 temperature를 1.0, top_p를 0.95, top_k를 20으로 설정하고, 다섯 개의 응답을 생성
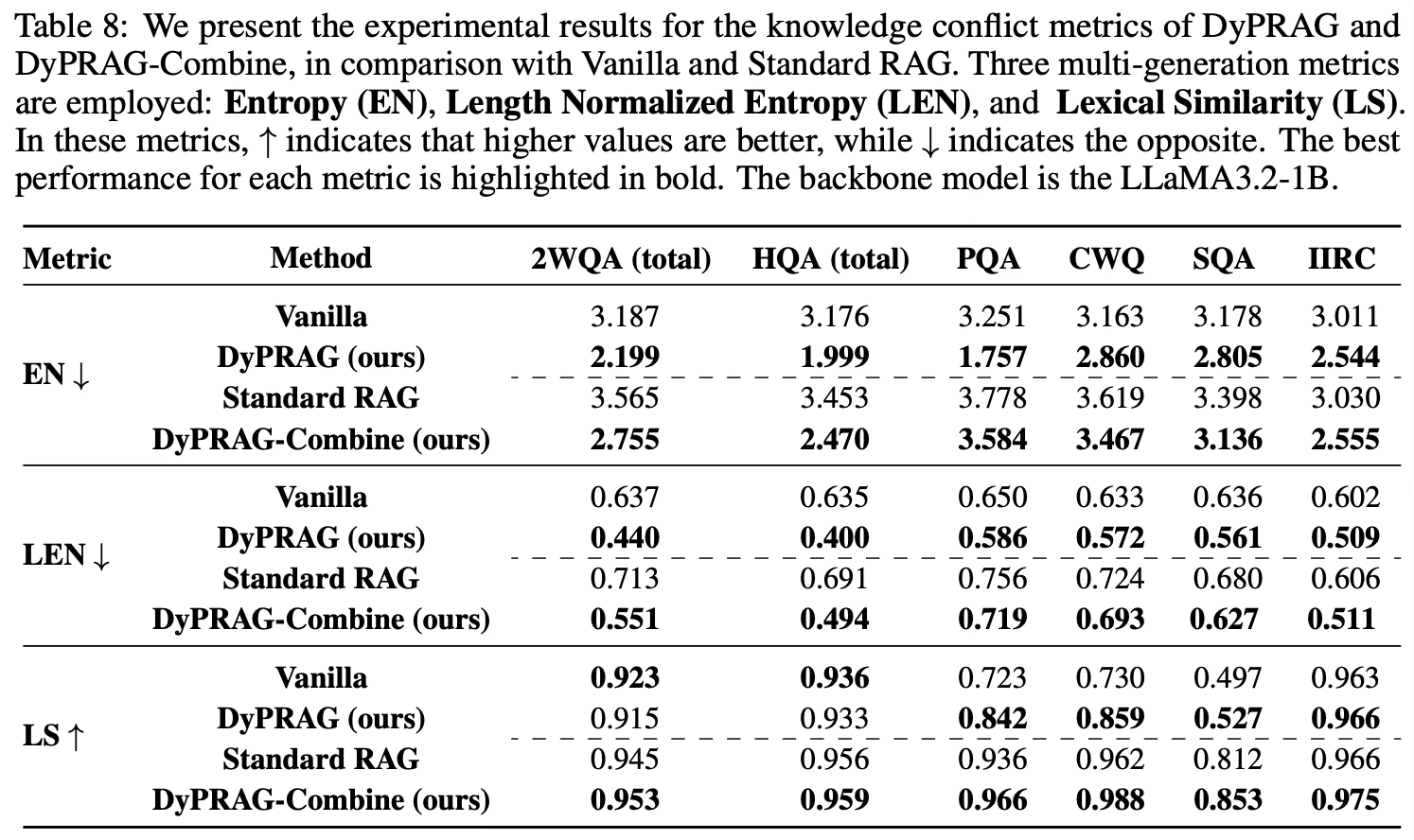
- 생성물에 대해서 RAG 환각 발생 확률을 평가하기 위해 Entropy(EN), 길이 정규화 엔트로피(LEN), 그리고 어휘적 유사도(LS)를 계산
- EN (Entropy) : 여러 응답 간 불확실성
- LEN (Length Normalized Entropy) : EN을 응답 길이로 보정
- LS (Lexical Similarity) : 응답들 간 표면적 단어 유사도
- [Table 8] 결과를 보면 DyPRAG가 대부분의 시나리오에서 지식 충돌이 적고, 특히 가장 강력한 DyPRAG-Combine에서 두드러짐 (여러 번 답하게 해도 답이 거의 흔들리지 않는다. 지식이 내부적으로 정렬됨)
- 또한 in-context injection이 적용될 때 EN과 LEN이 모두 증가함
- 이는 RAG 시스템에서 retrieval된 문서가 종종 모델의 내부 지식과 충돌함을 시사
- 반면 DyPRAG를 사용해 변환된 파라미터 지식을 주입할 경우 지식 충돌 가능성이 현저히 감소
- 그러나 LS 결과는 컨텍스트를 추가하면 충돌이 줄어든다고 나타나는데, 이는 기존의 RAG 환각 정의와 모순됨
- LS는 문서 따라 말하면 안전하다고 착각하게 만들지만, 실제 RAG 환각은 “지식 충돌로 인한 답변 불안정성”이기 때문에 DyPRAG 환경에서는 EN과 LEN 같은 문장 수준 불확실성 지표가 더 적합
Parameter Injection Makes LLMs Trust Themselves

- [Figure 9] 결과를 보면 기본 LLM은 어떤 감독이 더 늦게 태어났는지에 대해 정확한 파라미터 지식을 이미 가지고 있다
- 그러나 각 감독에 대한 검색된 문서를 추가하자(RAG), 컨텍스트 지식이 모델을 오히려 잘못된 방향으로 이끈다
- 그 결과, 모델은 잘못된 답변인 ‘William Lustig’을 선택하게 되지만, DyPRAG는 동일하게 올바른 답을 유지한다
- 이를 통해 DyPRAG가 지식 충돌 문제를 효과적으로 완화할 수 있음을 보여준다
- 이렇게 RAG는 context에서 불필요한 부분을 모델한테 삽입해 환각을 만들지만 DyPRAG는 정확한 지식을 파라미터로 주입함으로써 지식을 효과적으로 통합한다
- 그 결과, LLM이 자신의 지식에 더 일관되게 의존할 수 있게 된다
Dynamic Parametric Knowledge Enhances LLMs at Test-time

- DyPRAG는 테스트 시점에서 지식을 강화하기 위한 효과적인 plug-in-play 기법으로 작동함
- [Figure 10]에서 보이듯이, DyPRAG는 전체 사례 중 14.67%에서 대형 언어 모델의 기존 파라미터 지식을 바꿔 정답을 맞추게 만들었다
- 따라서 DyPRAG는 추가적인 파인튜닝 없이도 추론 과정에서 모델의 지식을 직접적으로 향상시킬 수 있다
Proportion of Different Combinations
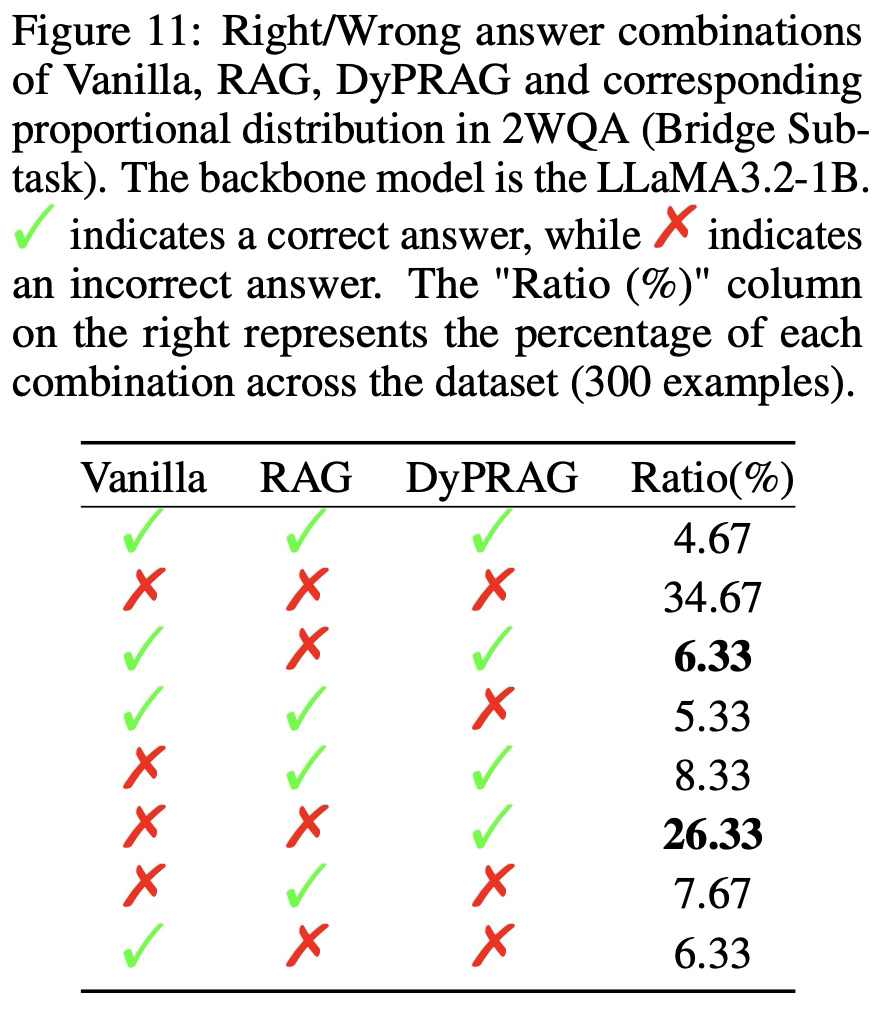
- [Figure 11]를 보면 기본 LLM과 RAG가 모두 오답을 낸 경우에도 DyPRAG는 26.33%의 확률로 정답을 제공한다
- 이는 DyPRAG가 누락된 파라미터 지식을 효과적으로 주입할 수 있으며, in-context injection 방식보다 우수함을 의미
- 추가적으로, 기본 LLM이 정답을 제공하는 경우, 즉 모델이 정확한 내부 지식을 이미 보유한 경우에, RAG는 5.33%의 정답률을 보이는 반면, DyPRAG는 6.33%로 더 나은 성능을 보이며, 이는 파라미터 주입이 지식 충돌을 더 적게 유발함을 보여준다

- [Figure 12]에서는 DyPRAG-Combine에서도 유사한 경향이 나타난다
- 이러한 결과는 DyPRAG가 파라미터 지식을 성공적으로 주입함을 증명
- 또한, 지식이 담긴 LoRA 어댑터를 주입함으로써 내부 파라미터 지식과 외부 컨텍스트 지식 간의 충돌을 완화한다
💬 6. Takeaway
실험이 생각보다 많았다. 뭔가 특별한 하이퍼네트워크 구조가 아니라 일반적인 구조가 뭔가 새롭진 않았지만 그래도 다양한 실험을 적어놔 인상깊었다. 결국 parameter translator를 학습시키기 위한 데이터를 LoRA로 만들어야 하는데, 이 부분을 줄일 수 있는 어떠한 방법이 있으면 좋을거 같다.



