

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- RAG
- Transformer
- SFT
- Noise
- Hallucination
- 파인튜닝
- DyPRAG
- Document Augmentation
- GPT
- lora
- Embedding
- odds
- Python
- Retriever
- Parametric RAG
- Baekjoon
- Algorithm
- retrieval
- COT
- Statistics
- LLM
- NLP
- Noise Robustness
- moe
- coding test
- reranking
- Do it
- DPO
- fine-tuning
- qwen
Archives
- Today
- Total
왕구아니다
[논문 리뷰] InstructRAG : INSTRUCTING RETRIEVAL AUGMENTED GENERATION VIA SELF-SYNTHESIZED RATIONALES 본문
Paper Review/RAG
[논문 리뷰] InstructRAG : INSTRUCTING RETRIEVAL AUGMENTED GENERATION VIA SELF-SYNTHESIZED RATIONALES
Psalms 12:6-7 2026. 2. 17. 21:26본 논문 리뷰는 저의 개인적인 해석과 의견을 바탕으로 작성된 글입니다.
내용 중 해석의 오류나 개념적인 착오가 있다면, 망설이지 마시고 댓글로 혼내주시면 감사하겠습니다~
Preview
- INSTRUCTRAG는 검색된 문서에서 정답이 어떻게 도출되는지를 모델이 스스로 설명(rationale)하도록 만들고, 이 self-synthesized rationale을 ICL 또는 fine-tuning 데이터로 활용해 명시적(Explicit) denoising을 학습시키는 RAG 프레임워크
- RAG의 성능 문제는 retrieval 자체보다 “노이즈를 어떻게 처리하느냐”에 있으며, 정답만 학습하는 implicit 방식보다 denoising 과정을 설명하게 하는 explicit 학습이 더 강건하고 일반화에 유리하다는 것을 보여주고자 한다
Link
- 논문 : https://arxiv.org/abs/2406.13629
- 코드 : https://github.com/weizhepei/InstructRAG
GitHub - weizhepei/InstructRAG: [ICLR 2025] InstructRAG: Instructing Retrieval-Augmented Generation via Self-Synthesized Rationa
[ICLR 2025] InstructRAG: Instructing Retrieval-Augmented Generation via Self-Synthesized Rationales - weizhepei/InstructRAG
github.com
📍0. Abstract
- 본 논문에서는 LLM이 스스로 생성한 rationale(설명)을 통해 denoising 과정을 명시적으로 학습하는 INSTRUCTRAG를 제안한다.
- 먼저 모델에게 “정답이 검색 문서로부터 어떻게 도출되는지 설명하라”고 지시한다.
- 이렇게 생성된 rationale은 in-context learning 데모로 쓰이거나(INSTRUCTRAG-ICL) supervised fine-tuning 데이터로 사용되어 (INSTRUCTRAG-FT) 모델이 명시적으로 denoising을 학습하게 된다.
- 기존 RAG와 달리 추가 감독 데이터가 필요 없으며, 답의 검증이 쉬워지고, 생성 정확도도 향상된다. (self-synthesis이기 때문에 GPT-4 라벨링 필요 없음)
📍1. Introduction
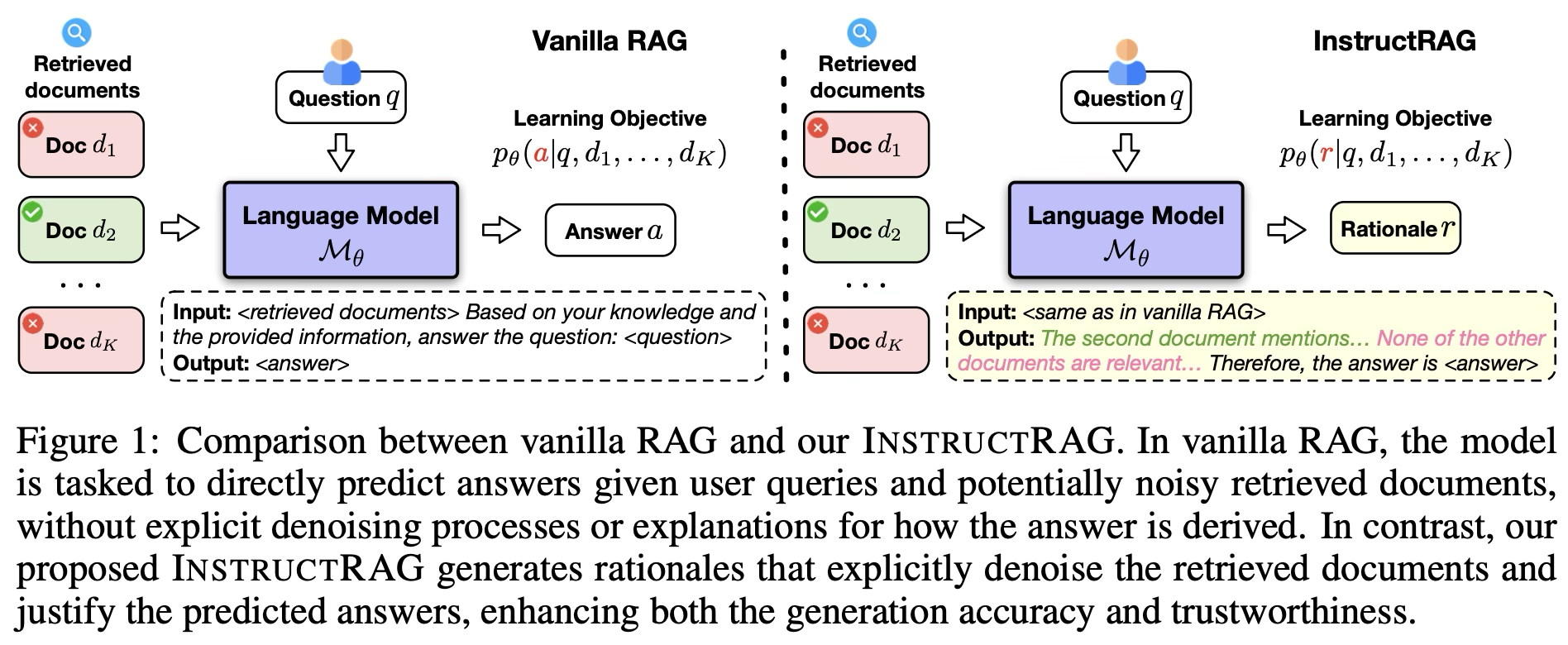
- 기존의 기본적인 RAG 방식은 노이즈가 섞인 입력을 그대로 받아 정답을 예측하도록 모델을 학습시킨다.
- (question + noisy documents) → answer
- 이렇게 학습하면 노이즈를 어떻게 처리하는지는 학습 목표에 명시되어 있지 않다.
- 반대로 명시적인 denoising 학습 데이터를 만들려면 많은 인간의 노력이 필요해 비용이 크다.
- 예를 들어 어떤 문서가 relevant한지 라벨링, 어떤 문장이 근거인지 표시, 왜 다른 문서는 irrelevant인지 설명 작성
- 본 논문에서는 검색된 정보를 명시적으로(Explicitly) 정제(denoise)하고, 예측한 답이 왜 맞는지 설명까지 생성하는 새로운 RAG 프레임워크, INSTRUCTRAG를 제안한다.
📍2. Our Method : InstructRAG

INSTRUCTRAG는 “정답을 맞추는 모델”을 학습하는 것이 아니라 “노이즈를 제거하는 과정을 설명하는 모델”을 학습한다.

2.1 PROBLEM SETTING
- 기존 RAG
- 질문 q가 주어지면, retriever R는 외부 지식 베이스에서 노이즈가 포함될 수 있는 문서 집합 D= {d1,···,dK}를 반환한다.
- 모델은 이제 질문 q와 검색된 문서 D, 그리고 자신의 내부 파라메트릭 지식을 기반으로 정답 a를 예측해야 한다.
- 이를 확률적으로 표현하면 Pθ(a | q, D)
- 이 논문의 초점은 LLM의 노이즈 강건성(noise robustness)을 분석하고 RAG를 위한 효율적인 denoising 기법을 개발하는 것이다.
- retrieval 개선이 아니라 generation 단계의 noise robustness가 중심
- 따라서 retriever를 새로 학습하지 않고, 기존 off-the-shelf retriever를 그대로 사용한다. 또한 검색된 문서를 어떤 필터링이나 재정렬 없이 그대로 질문 앞에 붙여 모델에 입력한다.
2.2 RATIONALE GENERATION VIA INSTRUCTION-FOLLOWING

- 최근 연구들은 LLM을 인간의 의도에 잘 맞도록 정렬(alignment)시키는 데 큰 진전을 이루었고, 그 결과 모델은 사용자 지시를 매우 정확하게 따르는 고품질 데이터를 생성할 수 있게 되었다.
- 이러한 발전에 착안하여, LLM의 강력한 instruction-following 능력을 활용해 RAG를 위한 명시적 denoising 응답(즉, rationale)을 생성하도록 한다.
- [Table 1] 구체적으로, 질문–정답 쌍과 검색된 문서 집합이 주어지면, off-the-shelf LLM Mϕ를 사용해 다음과 같은 지시를 준다. “어떤 문서가 유용한지 식별하고, 이 문서들이 어떻게 정답으로 이어지는지 설명하라.” 이렇게 해서 rationale ri를 생성한다. 이 rationale은 어떤 문서가 유용한지, 어떤 문서는 노이즈인지, 정답이 어떻게 도출되는지를 구체적으로 설명한다.
- 생성된 rationale이 정답과 일치하는지 확인하기 위해, 간단한 substring match를 사용한다. 적어도 하나의 relevant 문서가 정답을 포함하고 있는 경우, 생성된 rationale이 정답과 일치하는 비율은 평균 98%에 달한다.
- 이 과정을 통해 QA 데이터셋을 T= {⟨q,a⟩} → T+ = {⟨q,r⟩}로 확장. 즉, answer supervision만 있던 데이터가 rationale supervision 데이터로 자동 확장. 이게 바로 self-synthesis의 핵심
2.3 LEARNING DENOISING RATIONALES IN RAG
- rationale이 추가된 데이터셋 T+를 사용하면, RAG 작업에서 명시적 denoising을 직접 학습하는 rationale learner Mθ를 효율적인 학습 전략으로 개발할 수 있다.
INSTRUCTRAG-ICL

- INSTRUCTRAG-ICL은 학습 없이(in training-free setting) in-context learning을 통해 denoising rationale을 학습하는 방식이다.
- [Table 10] 테스트 질문 q와 검색된 문서 집합 D가 주어지면, 먼저 T+에서 N개의 예시 ⟨qi,ri⟩∈T+를 무작위로 샘플링한다. 그 다음, 모델에게 이 예시를 따르도록 프롬프트하여 새로운 rationale r를 생성하게 한다.
- 메모리 절약과 추론 효율을 위해, ICL 데모에서는 예시 질문과 해당 rationale만 보여준다.
- example에서 retrieved documents는 포함하지 않는다. rationale 패턴만 학습하게 한다.
INSTRUCTRAG-FT
- INSTRUCTRAG-FT는 표준 language modeling objective를 사용해 supervised fine-tuning으로 denoising rationale을 학습하는 trainable 방식이다.
- 수식으로 표현하면, 질문 q와 검색 문서 D가 주어졌을 때 rationale r의 생성 확률을 최대화한다.

- INSTRUCTRAG-FT의 학습과 추론은 동일한 데이터 형식을 사용한다

- 입력은 검색된 문서, 그 다음 질문, 출력은 denoising rationale r
📍3. Experiments
3.1 EXPERIMENTAL SETTING
RAG tasks and evaluation metrics

- 다섯 개의 지식 집약적 벤치마크에서 광범위한 실험을 수행한다.
- PopQA
- TriviaQA
- Natural Questions
- ASQA
- 2WikiMultiHopQA
- 검색 소스로는 Wikipedia corpus를 사용하며, sparse 및 dense retriever를 모두 실험에 활용한다.
- BM25 (sparse)
- DPR
- GTR
- Contriever (dense)
- retrieval 품질은 Recall@K로 측정한다.
- Recall@K의 의미는 상위 K개 검색 문서 안에 정답이 포함되어 있는가?
- 표준 평가 설정을 따라, ASQA 데이터셋에서는 다음 지표를 사용한다
- correctness (str-em)
- citation precision (pre)
- citation recall (rec)
- ASQA는 long-form QA 태스크이기 때문에 단순 정확도 외에 citation 기반 평가도 수행한다.
- 다른 네 개의 태스크(PopQA, TriviaQA, NQ, 2WikiMultiHopQA)에서는 accuracy를 사용한다.
- 추가적으로, LLM-as-a-judge 평가도 수행한다. 이유는 pattern-matching 기반 지표는 동의어 표현을 정확히 평가하지 못한다.

Baselines
- training-free 설정과 trainable 설정 모두에서 다양한 RAG baseline들과 비교한다.
- 최신 LLM들은 사전학습 과정에서 이미 많은 세계 지식을 학습했기 때문에, retrieval을 사용하지 않는 baseline(즉, vanilla zero-shot prompting)의 성능도 참고용으로 포함한다.
- training-free RAG baseline은 다음과 같다.
- (1) In-Context Retrieval-Augmented Language Modeling (RALM) : retrieval 없이 질문만 주는 baseline을 확장하여, 검색된 문서를 함께 프롬프트에 제공하는 방식이다.
- (2) Few-shot demonstration with instruction : 학습 데이터에서 정답이 포함된 QA 쌍을 샘플링하여 ICL 예시로 사용하는 방식이다.
- trainable RAG baseline은 다음과 같다.
- (1) Vanilla Supervised Fine-Tuning (SFT) : 노이즈가 섞인 입력이 주어졌을 때, 정답의 likelihood를 최대화하는 일반적인supervised 학습 방식이다.
- (2) RetRobust : relevant context와 irrelevant context를 섞어 학습하여, irrelevant 문맥에 대해 강건하도록 fine-tuning하는 방법이다.
- (3) Self-RAG : 특수 reflection token을 사용하여 adaptive retrieval을 수행하는 강력한 trainable baseline이다.
3.2 MAIN RESULT

Baselines without retrieval
- 기본 instruction-tuned 모델(Llama-3-Instruct 8B 및 70B)은 다섯 개 벤치마크 전반에서 이미 상당히 높은 성능을 달성한다. 즉, retrieval 없이도 꽤 잘 맞춘다.
- 특히 70B 모델은 TriviaQA에서 80.6%라는 놀라울 정도로 경쟁력 있는 성능을 보인다.
- 이 관찰은 해당 태스크에 필요한 지식이 대부분 모델의 파라메트릭 지식(parametric knowledge) 안에 포함되어 있음을 시사한다.
- 아마도 데이터 오염(data contamination) 때문일 가능성이 있다. 즉, 다운스트림 태스크의 테스트 데이터가 사전학습 데이터에 포함되어 있었을 가능성
RAG without training
- In-context RALM과 few-shot demonstration with instruction 방식은 retrieval을 사용하지 않는 baseline보다 일반적으로 더 높은 성능을 보인다. 이는 지식 집약적 태스크에서 retrieval이 중요함을 보여준다.
- 고무적인 점은, INSTRUCTRAG-ICL이 다양한 평가 지표에서 모든 training-free baseline을 일관되게 능가했다는 것이다.
- 이는 self-synthesized denoising rationale의 효과를 확인해준다.
- 단순히 문서를 보여주는 것보다 문서를 어떻게 해석할지 학습시키는 것이 더 중요하다
- 또한 8B에서 70B로 모델 크기를 늘렸을 때 성능이 향상된다는 점은, INSTRUCTRAG-ICL이 더 큰 backbone 모델에서도 효과적으로 확장된다는 것을 보여준다.
RAG with training
- Table 3의 하단 블록에서 볼 수 있듯이, INSTRUCTRAG-FT는 다섯 개 벤치마크 전반에서 non-retrieval 및 training-free baseline을 모두 능가할 뿐만 아니라, 대부분의 평가 지표에서 기존 trainable RAG baseline들보다도 상당히 높은 성능을 보인다.
- 유일한 예외는 ASQA 태스크에서 citation 관련 지표(precision 및 recall)에서 Self-RAG보다 약간 낮은 성능을 보인다는 점이다.
- 이는 본 연구의 초점이 citation이 아니라 generation의 correctness(EM 지표 향상)에 있기 때문이다.
Case Study

PROMPT TEMPLATES


3.3 ABLATION STUDY

Providing ground-truth answers and retrieved documents is important for rationale generation
- Table 4의 첫 번째 블록에서 보이듯이, rationale 생성 설계를 두 가지 측면에서 ablation(제거 실험)한다.
- (1) 정답 없이(w/o ground-truth answer) : rationale 생성 단계에서 모델이 정답을 제공받지 않으며, 검색 문서만을 기반으로 정답을 예측하고 그 도출 과정을 설명해야 한다.
- (2) 검색 문서 없이(w/o retrieved documents) : rationale 생성 단계에서 검색 문서를 제공하지 않으며, 이 경우 모델은 자신의 내부 지식만으로 주어진 정답을 설명해야 한다.
- 검색 문서나 정답에 접근하지 못하는 경우에도 여전히 비교적 잘 동작한다는 점은 고무적이다.
- 이 결과는 INSTRUCTRAG가 완전한 비지도 방식으로도 동작할 가능성을 시사한다.
Larger rationale generator leads to better results
- Table 4의 가운데 블록은 서로 다른 크기의 rationale generator가 성능에 어떤 영향을 미치는지를 보여준다.
- (1) 템플릿 기반 rationale 생성 방식 보다는 LM 기반 rationale generator의 필요성을 드러난다.
- 그 이유는 템플릿 기반 방식이 정답을 포함한 문서를 단순한 패턴 매칭으로 식별하기 때문이다. 이 방식은 lexical similarity만 고려하고 semantic meaning은 무시한다.
- 이러한 의미 정보의 무시는 템플릿 방식으로 생성된 rationale에 노이즈를 불가피하게 도입하며, 결과적으로 LM이 생성한 rationale보다 덜 효과적이 된다.
- (2) 70B generator를 사용하는 경우가 8B generator를 사용하는 경우보다 training-free와 trainable 설정 모두에서 일관되게 더 높은 성능을 보인다.
- 이는 더 강력한 모델이 생성한 self-synthesized denoising rationale이 더 좋은 supervision을 제공한다는 것을 의미한다.
Inference with demonstrations should only be applied to INSTRUCTRAG-ICL
- Table 4의 하단 블록에서는 모델 추론 단계에서 demonstration(예시)을 사용하는 것이 어떤 영향을 미치는지를 분석한다.
- demonstration은 INSTRUCTRAG-ICL에서는 중요한 역할을 하지만, INSTRUCTRAG-FT에서는 오히려 성능을 저하시킨다는 것을 발견했다.
- 그 이유는 INSTRUCTRAG-FT가 노이즈가 포함된 입력이 주어졌을 때 demonstration을 참고하지 않고 바로 denoising rationale을 생성하도록 최적화되어 있기 때문이다.
- 데모 없이 학습되었기 때문에 추론 시에도 데모 없이 동작하는 것이 자연스럽다.
- 따라서 INSTRUCTRAG-FT에 대해 추론 단계에서 in-context demonstration을 추가하는 것은 불필요하며, 학습과 추론 간의 불일치(discrepancy) 때문에 오히려 성능을 저하시킬 수 있다.
3.4 ANALYSIS

INSTRUCTRAG-ICL consistently benefits from more demonstrations
- Figure 3a는 INSTRUCTRAG-ICL과 few-shot demonstration with instruction baseline의 demonstration 개수에 따른 성능 민감도(sensitivity)를 보여준다.
- Baseline few-shot ICL → 예시가 Question → Answer 형식
- INSTRUCTRAG-ICL few-shot → 예시가 Question → Rationale (denoising explanation) 형식
- 흥미로운 점은 baseline 방법의 경우 단 하나의 demonstration을 사용할 때 가장 좋은 성능을 보이며, 그보다 더 많은 demonstration을 제공하면 오히려 성능이 떨어진다는 것이다.
- 반면, INSTRUCTRAG-ICL은 demonstration 수가 증가할수록 성능이 일관되게 향상된다.
- 이는 self-synthesized rationale이 단순한 정답 기반 demonstration보다 denoising 측면에서 더 우수함을 입증한다.
INSTRUCTRAG-ICL and INSTRUCTRAG-FT are robust to increased noise ratios
- Figure 3b와 3c는 retrieved document 수를 증가시켰을 때, INSTRUCTRAG-ICL과 INSTRUCTRAG-FT의 generation accuracy와 그에 대응하는 retrieval precision 변화를 보여준다.
- 더 많은 문서를 검색하면 RAG 모델에 더 풍부한 외부 지식을 제공할 수 있지만, 동시에 더 많은 노이즈를 유입시키고 retrieval precision을 낮춘다.
- K 증가 → recall 증가 가능 → noise ratio 증가
- 그 결과, training-free와 trainable baseline 모두 문서 수가 증가할수록 성능 향상이 줄어들거나 오히려 성능이 하락한다.
- 이는 baseline들이 높은 노이즈 비율에 취약하다는 것을 보여준다.
- 반면, INSTRUCTRAG-ICL과 INSTRUCTRAG-FT는 노이즈 비율이 증가해도 성능이 저하되지 않으며, 오히려 더 향상되는 모습을 보인다. 이는 강건한 denoising 능력을 보여준다.
INSTRUCTRAG-ICL and INSTRUCTRAG-FT generalize well to unseen tasks

- Figure 4는 training-free 설정과 trainable 설정 모두에서 일반화 능력을 보여준다.
- In-domain (ID) 설정에서는
- training-free의 경우 → 타겟 도메인의 demonstration을 사용하고
- trainable의 경우 → 타겟 도메인 태스크로 직접 학습한다.
- 반면, Out-of-domain (OOD) 설정에서는
- source 도메인 데이터만 사용하고
- target 도메인에 대한 사전 지식은 없다.
- 모델은 source 도메인에서 학습한 지식을 활용해 보지 못한 target 도메인 태스크를 해결해야 한다.
- 실험 결과, InstructRAG 방법이 ID와 OOD 설정 모두에서 다양한 시나리오에 걸쳐 baseline을 일관되게 능가했다.
- 흥미롭게도, long-form QA에서 short-form QA로 일반화하는 시나리오(Figure 4b)에서는 training-free OOD 방법이 ID 방법보다 상당히 높은 성능을 보인다.
- OOD 방법은 source 도메인(ASQA)의 긴 답변(long answers) demonstration에서 이점을 얻었기 때문일 가능성이 있다. 즉, 긴 답변이 더 풍부한 reasoning을 제공했을 수 있다.
- 그 이유는 ASQA 질문이 모호하고 여러 해석이 가능하며, 정답이 긴 형식으로 다양한 관점에서 설명되기 때문이다. 이러한 긴 답변은 일종의 chain-of-thought demonstration으로 볼 수 있다. 즉, long-form rationale이 implicit CoT 역할을 한다.

- 더 나아가, INSTRUCTRAG가 QA가 아닌 다른 지식 집약적 태스크, 예를 들어 코드 생성(code generation)에도 일반화될 수 있는지를 연구한다.
- Table 5a에서 보이듯이, PopQA로 학습된 INSTRUCTRAG-FT를 전혀 보지 않은 코드 생성 태스크(HumanEval)에 직접 적용한다.
- 이 실험은 CodeRAG-Bench 설정을 따른다. QA로 학습 → 코드 데이터로 추가 학습 없음 바로 → 코드 생성에 적용. 즉, 완전한 cross-task generalization 실험이다.
- 코드 생성 성능은 표준 평가 지표인 pass@k(k번 시도 중 정답 코드가 포함되는 비율)로 측정하며, baseline으로는 off-the-shelf Llama-3-8B-Instruct를 사용한다.
- 실험 결과, non-retrieval 설정과 RAG 설정 모두에서 InstructRAG가 보지 않은 코드 생성 태스크에서도 일관되게 더 나은 일반화 성능을 보인다.
- 이 결과를 보아 QA 태스크로 학습된 INSTRUCTRAG는 기본 Llama-3-8B-Instruct보다 코딩 솔루션의 설계를 설명하는 텍스트 기반 주석(comment)을 더 많이 생성하는 경향이 있다. 이러한 설명적 주석이 더 정확한 코드 생성을 유도한다.
- rationale 학습 → 설명적 reasoning 강화 → 코드 설계 설명 증가 → 코드 정확도 향상
Evaluation with LLM-as-a-judge
- 질문응답 태스크에서 accuracy나 exact match는 표준 평가 지표이지만, 이 지표들은 주로 패턴 매칭에 의존하기 때문에 완벽하지 않다는 것이 알려져 있다.
- 즉, 단순 문자열 비교에 기반한다는 한계가 있다.
- 이러한 지표는 예측값과 정답이 동의어인 경우를 제대로 처리하지 못한다. 예를 들어, “Donald Trump”와 “Donald J. Trump”는 의미적으로 동일하지만, 문자열이 완전히 일치하지 않으면 정답으로 인식되지 않는다. 이로 인해 편향된 평가 결과가 발생할 수 있다.
- 따라서 우리는 LLM-as-a-judge 방식을 사용하며, GPT-4o를 평가 모델로 활용한다.
- 이 방식은 judge 모델이 의미적 동등성(semantic equivalence)을 고려할 수 있게 하며, 보다 공정한 평가를 가능하게 한다.
- Table 5b에서 보이듯이, open-domain Natural Questions 벤치마크에서 training-free와 trainable RAG 설정 모두에 대해
- InstructRAG와 baseline 모델을 평가한다.
- 패턴 매칭 기반 지표와 비교했을 때, LLM-as-a-judge는 일반적으로 더 높은 평가 점수를 보여준다.
- InstructRAG가 패턴 매칭 기반 평가와 LLM 기반 평가 모두에서 baseline을 일관되게 능가한다.
📍4. Conclusion
- 본 연구에서는 검색된 문서를 명시적으로(Explicitly) 정제하고 정확한 응답을 생성하는 단순한 RAG 방법인 INSTRUCTRAG를 제안하였다.
- 대형 언어모델의 강력한 instruction-following 능력을 활용하여, INSTRUCTRAG는 정답이 검색 문서로부터 어떻게 도출되는지를 구체적으로 설명하는 rationale을 생성한다.
- 이렇게 생성된 synthetic rationale은 ICL 예시로도, supervised fine-tuning 데이터로도 사용될 수 있으며, 이를 통해 모델은 명시적인 denoising 과정을 학습하게 된다.
Limitations
- 본 연구는 주로 질문응답(QA) 유형의 태스크에서 실험을 수행하였으며, open-ended generation과 같은 다른 시나리오에서도 얼마나 일반화될 수 있는지는 아직 명확하지 않다.
- 또한 accuracy와 exact match는 표준 평가 지표이긴 하지만, 편향이 존재하며 모델 생성 품질을 완벽하게 반영하지 못한다.
- 평가 결과는 length bias의 영향을 받기 때문에 긴 응답일수록 정확도가 더 높게 나오는 경향이 있다. → 길게 쓰면 정답 문자열이 포함될 확률이 높아진다.
- 또 다른 잠재적 한계는, 모델이 학습 데이터의 샘플 편향(sample bias)에 영향을 받을 수 있다는 점이다.
'Paper Review > RAG' 카테고리의 다른 글
'Paper Review/RAG' Related Articles
more



