

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- coding test
- Document Augmentation
- lora
- Do it
- COT
- odds
- 파인튜닝
- Noise Robustness
- Python
- Noise
- Hallucination
- DyPRAG
- RAG
- Transformer
- reranking
- SFT
- Statistics
- GPT
- Baekjoon
- DPO
- NLP
- fine-tuning
- Retriever
- Algorithm
- Parametric RAG
- qwen
- retrieval
- Embedding
- LLM
- moe
Archives
- Today
- Total
왕구아니다
[논문 리뷰] Provence : efficient and robust context pruning for retrieval-augmented generation 본문
Paper Review/RAG
[논문 리뷰] Provence : efficient and robust context pruning for retrieval-augmented generation
Psalms 12:6-7 2026. 2. 15. 01:42본 논문 리뷰는 저의 개인적인 해석과 의견을 바탕으로 작성된 글입니다.
내용 중 해석의 오류나 개념적인 착오가 있다면, 망설이지 마시고 댓글로 혼내주시면 감사하겠습니다~
Preview
- NAVER LABS에서 발표한 논문
- Provence는 context pruning을 token-level binary classification으로 정의하고, LLM이 만든 silver label을 이용해 학습한 lightweight cross-encoder 모델
- Reranking과 pruning을 하나의 모델로 통합(unified)하여, 추가 연산 없이(pruning 거의 공짜) 높은 compression에서도 QA 성능을 유지하거나 오히려 향상
- Compression ratio를 고정하는 대신 threshold 기반 adaptive pruning을 사용해, 다양한 도메인에서 별도 튜닝 없이(out-of-the-box) robust하게 작동
Link
- 논문 : https://arxiv.org/abs/2501.16214
- 코드 : https://huggingface.co/naver/provence-reranker-debertav3-v1
naver/provence-reranker-debertav3-v1 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
📍0. Abstract

- 검색 증강 생성(RAG)은 대형 언어 모델(LLM)의 생성 품질 여러 측면을 향상시키지만, 긴 컨텍스트로 인한 계산 비용 증가와, 검색된 문서에 포함된 불필요한 정보가 생성 응답으로 전파되는 문제를 겪는다.
- 이를 해결하기 위한 기존 context pruning 방법들은 제한적이며, 다양한 상황(예: 관련 정보의 양이 가변적이거나, 길이가 다양하거나, 여러 도메인에서 평가될 때)에 대해 효율적이면서도 강건한 범용 모델을 제공하지 못한다.
- 본 연구에서는 이러한 격차를 해소하고, Provence(Pruning and Reranking Of retrieVEd relevaNt ContExts)를 제안한다.
- 이는 질문응답(QA)을 위한 효율적이고 강건한 context pruner로, 주어진 컨텍스트에 대해 필요한 프루닝 양을 동적으로 감지하며, 다양한 도메인에서 별도의 추가 조정 없이 사용할 수 있다.
- Provence의 세 가지 핵심 요소는 (1) context pruning을 시퀀스 라벨링 문제로 공식화하는 것, (2) 컨텍스트 프루닝과 리랭킹 기능을 통합하는 것, (3) 다양한 데이터로 학습하는 것이다.
📍1. Introduction
- RAG의 사용은 검색 지연과 LLM 입력 길이 증가로 인해 계산 비용을 추가로 발생시킨다.
- 또한 검색된 컨텍스트에 포함된 불필요한 정보가 생성 응답으로 전파될 수 있다.
- 이러한 문제들은 더 효율적이고 강건한 LLM을 개발함으로써 해결될 수 있다. (긴 컨텍스트를 더 효율적으로 처리하기 위한 아키텍처 변경이나, 불필요한 컨텍스트 처리를 개선하기 위해 다양한 데이터로 튜닝하는 방식 등이 있다)
- 그러나 LLM을 튜닝하는 것은 매우 많은 자원을 필요로 하거나, 폐쇄형 LLM의 경우 적용이 불가능할 수도 있다.
- 대안적 해결책은 사용자의 질문과 관련 없는 컨텍스트 부분을 제거하여 검색된 컨텍스트를 pruning하는 것이다.(이는 컨텍스트 길이를 줄이고 따라서 생성 속도를 향상시킨다)
- 이러한 context pruning 모듈은 어떤 생성 LLM과도 plug-and-play 방식으로 사용될 수 있으며, 사용이 간편하고 RAG 파이프라인에서 더 나은 투명성을 제공한다.
- 이전 context pruning에 대한 연구들의 문제점
- 첫째, 많은 접근법들은 단순화된 설정을 가정한다. 예를 들어, 각 컨텍스트에서 입력 질문과 관련된 문장이 하나뿐이라고 가정하거나, 압축 비율이 고정되어 있다고 가정한다.
- 그러나 실제로는 컨텍스트가 전혀 관련 정보가 없을 수도 있고, 전체가 관련 정보일 수도 있기 때문에 pruner는 이를 adaptive하게 감지해야 한다.
- 둘째, 많은 연구들이 실제로 사용하기에는 충분히 효율적이지 않은 context pruner를 제안한다.
- LLM을 그대로 pruning에 사용하거나 최종 컨텍스트를 sequential autoregressive 방식으로 생성해야 하는 추상적(abstractive) 컨텍스트 압축기를 설계하는 경우도 포함된다.
- 셋째, 대부분의 기존 연구들은 각 데이터셋에 대해 개별적으로 context pruner를 학습시키며, 다양한 데이터 도메인에 대한 강건성을 목표로 하거나 테스트하지 않는다.
- 첫째, 많은 접근법들은 단순화된 설정을 가정한다. 예를 들어, 각 컨텍스트에서 입력 질문과 관련된 문장이 하나뿐이라고 가정하거나, 압축 비율이 고정되어 있다고 가정한다.

- Table 1은 다양한 기존 방법들의 속성을 특정 기준에 따라 요약한 것이고, 그 어떤 방법도 나열된 모든 기준을 만족하지 못함을 보여준다.
- 또한 pruning의 단위(granularity)라는 차원을 포함하는데, 이는 토큰 단위 프루닝과 문장 단위 프루닝을 구분한다.
- 토큰 단위 pruning은 관사나 감탄사와 같은 저수준 문법 단위를 제거하며, 보통 질문과 무관하게 수행된다.
- 문장 단위 pruning은 답변 생성과 관련이 없다고 판단되는 의미 단위(문장)를 제거하는 것이다.
- 본 연구에서는 질문 의존적인(query-dependent) 문장 단위 pruning에 초점을 맞춘다.
- Provence의 특징은
- 1) Context pruning을 sequence labeling으로 정의 (pruner가 예측한 이진 마스크가 질문과 관련된 문장을 0개에서 전체까지 결정하도록 한다)
- 2) Reranking과 통합
- 3) 작은 모델로 학습
- 4) 다양한 도메인에서 robust
📍2. Provence

- 첫 번째 특징은 context pruning 문제를 sequence labeling 문제로 정의한 것이다.
- query–context 쌍을 인코딩하도록(cross-encoder) DeBERTa 모델을 파인튜닝하여, irrelevant context 부분을 제거하는 데 사용되는 binary mask를 출력하도록 한다.
- 학습을 위한 라벨은 LLaMA-3-8B-Instruct로 생성되며, 자동 생성된 라벨이기 때문에 이를 silver label이라고 부른다.
- 이렇게 했을 때의 장점은 다음과 같다.
- (1) 구조적으로, 모델은 context에 포함된 다양한 노이즈 수준을 처리할 수 있으며 적절한 pruning 비율을 선택할 수 있다.
- Provence는 binary classification이기 때문에 문장 개수가 자동으로 결정됨 → 동적으로 pruning ratio가 바뀜
- (2) query는 context 문장들과 함께 인코딩되며(cross-encoding), 이는 query와 context를 독립적으로 인코딩하는 extractive RECOMP와 비교했을 때 더 풍부한 표현을 제공한다.
- RECOMP 방식은 문장 embedding과 query embedding을 따로 구해 cosine similarity 계산
- (3) 경량 encoder를 사용함으로써 LLM 기반 또는 추상적(abstractive) 방법보다 더 효율적이다.
- (1) 구조적으로, 모델은 context에 포함된 다양한 노이즈 수준을 처리할 수 있으며 적절한 pruning 비율을 선택할 수 있다.
- 두 번째 특징은 RAG 파이프라인에서 reranking과 context pruning을 별개의 단계로 두는 대신, 이를 하나로 통합한 것이다.
- Provence에서는 reranking과 pruning을 하나의 forward step에서 수행할 수 있으며, 이로 인해 context pruning에 따른 추가 연산 비용이 거의 사라진다.
Training data
- 370k개의 질의를 포함하는 MS MARCO document ranking 데이터셋을 사용한다.
- MS MARCO 컬렉션은 웹에서 수집된 3.2M 문서로 구성된 도메인 다양성이 높은 datastore이다.
- 87K 개의 query가 포함된 Natural Questions 데이터셋 또한 사용한다.
Data processing
- MS MARCO 문서를 N개의 연속된 문장으로 구성된 passage로 나누는데, N은 1에서 10 사이의 랜덤 정수이다.
- 이는 pruner가 다양한 길이의 retrieved context에 대해 강건하도록 만들기 위함
- 그리고 각 passage 앞에 해당 페이지의 제목을 추가로 붙인다.
- 각 질문에 대해 SPLADE-v3 retriever와 DeBERTa-v3 reranker로 구성된 강력한 retrieval 파이프라인을 사용하여 상위 5개의 관련 passage를 검색한다. (질문당 5개 passages)
- 검색된 passage 집합은 retrieval의 불완전성 때문에 질문과 관련되거나 관련되지 않은 다양한 정도의 문서들을 자연스럽게 포함하게 된다.
Silver labels generation
- 질문과 검색된 passage(컨텍스트)가 주어지면, passage를 문장 단위로 분리한 뒤 Llama-3-8B-Instruct에게 해당 질문과 관련된 문장을 선택하도록 지시한다. (5개 passages의 문장들이 있으며 그 중에서 관련된 문장을 사람대신 LLM으로 판단)
- LLM을 사용할 때 가장 기본적인 프롬프트는 “주어진 질문과 관련된 문장의 인덱스를 출력하라”와 같은 단순한 프롬프트를 사용하는 것이다. (“Output indexes of sentences relevant to the given question”.)
- 그러나 LLM의 얕은 reasoning 때문에 불완전할 수 있으므로 LLM이 실제로 질문에 답하면서 관련된 문장을 인용하는 능력을 활용한다.
- “질문에 답해라. 단, context 안의 정보만 써라. 그리고 사용한 문장은 [i]로 인용해라.”
- 따라서 LLM에게 주어진 context의 정보만을 사용해 질문에 답하도록 지시하고, 관련 정보가 없을 경우 “No answer”를 출력하도록 한다.

- 또한 문장을 [i] 형식으로 쉽게 파싱할 수 있도록 인용 형식을 지정하고, context의 문장에도 동일한 번호를 부여한다.
- greedy decoding을 사용하며, 인용된 문장은 정규표현식을 통해 파싱한다. (다양한 프롬프트에 대한 실험 또한 진행)
- Llama-3-8B가 대부분의 경우 주어진 context만을 기반으로 답변할 수 있으며, 약 90%의 경우 인용을 출력한다는 것을 확인했다.
- LLM 출력에 인용(citation)이 없고 동시에 “No answer”도 포함되지 않은 경우를 제거한다. 왜냐하면 이러한 경우는 실제로 context에 관련 정보가 있음에도 LLM이 이를 인용하는 것을 “잊은” 경우이기 때문이다.

Training of Provence
- context pruner는 질문과 검색된 context를 연결(concatenation)한 입력을 받고, 각 토큰(사전학습 모델의 tokenizer 기준)이 최종 context에 포함되어야 하는지를 나타내는 per-token binary label을 출력한다.
- silver labeling으로 생성된 ground truth를 사용하여 Provence를 binary per-token classifier로 학습한다.(Loss = Binary Cross Entropy)
- Training of Provence에서 중요한 포인트는
- 입력은 Query + Context (cross-encoder)
- 출력은 per-token binary mask
- silver label로 supervised training
- token-level vs sentence-level ablation 비교
- standalone 모드로도 사용 가능
[입력]
[CLS] Question [SEP] Context [SEP]
[예를 들어 두 개의 passages가 있다고 하면 아래처럼 silver labels generation을 통해 만들어졌다]
[1] Tesla CEO Elon Musk completed the deal. [2] The total cost was $44 billion.
[Tokenizer를 거치면]
Tesla / CEO / Elon / Musk / completed / the / deal / . The / total / cost / was / $ / 44 / billion / .
[출력은 토큰 단위로 binary classification]
Tesla → 0
CEO → 0
Elon → 1
Musk → 1
completed → 1
...
결국 token-level prediction을 하지만, 실제로는 sentence-level로 자연스럽게 클러스터링된다.
왜냐하면 training label이 문장 단위로 생성되었기 때문이다.
Silver label에서:
문장 전체가 relevant → 그 문장의 모든 토큰 = 1
문장 전체가 irrelevant → 그 문장의 모든 토큰 = 0
즉, 학습할 때 문장 내부 토큰들은 같은 label을 받는다.
그래서 모델도 자연스럽게 문장 단위로 예측하게 된다.
Unifying compression and reranking
- cross-encoder reranker가 Provence와 동일한 아키텍처와 입력(질문–패시지 쌍)을 공유한다는 점에 주목했다.
- reranker 구조
- Input: [CLS] Question [SEP] Passage [SEP]
- Output: relevance score (scalar)
- Provence pruner 구조:
- Input: [CLS] Question [SEP] Passage [SEP]
- Output: token-level binary mask
- → 입력이 완전히 동일하다.
- → backbone encoder도 동일하게 DeBERTa다.
- reranker 구조
- 그렇다면 두개의 모델을 따로 쓸 필요 없지 않나?
- context pruning(질문에 답을 생성하는 데 유용한 context 부분을 선택하는 작업)은 reranking(질문과의 관련성을 평가하는 작업)과 본질적으로 유사하다.
- 따라서 두 접근 방식을 하나의 모델로 통합하고, 두 개의 서로 다른 task head를 사용한다.
- 구체적으로, reranking head는 BOS 토큰에 대해 scalar 예측값을 출력하고, pruning head는 passage 토큰들에 대해 per-token 예측을 출력한다. Encoder를 한 번만 forward하면 reranking score과 pruning mask를 동시에 출력
- reranking head
- Transformer의 [CLS] (또는 BOS) 토큰 representation은 전체 시퀀스를 요약한다.
- → 이 representation을 MLP에 넣어 relevance score 생성
- reranking head
- 학습을 용이하게 하기 위해, 사전 학습된 reranker를 provence labeling 목적에 맞게 추가로 파인튜닝하되, 기존 reranking 성능을 유지하기 위한 ranking regularizer를 추가한다.
- 만약 이미 잘 학습된 reranker가 있다. 그 위에 pruning task를 추가 학습하면 reranking 성능이 망가질 위험 있음
- 그래서 Ranking regularization을 추가한다. 즉, 기존 reranker score를 teacher로 사용하여 새로운 모델이 그 점수를 유지하도록 강제함. 일종의 knowledge distillation이다.
- 이 regularizer는 기존 reranker가 출력한 reranking score에 대해 Mean Squared Error(MSE) loss를 적용한 것이다. (즉, provence가 예측하는 ranking score가 기존 reranker score와 최대한 비슷하도록)
- 이는 기존 모델이 teacher 역할을 하는 단순한 pointwise score distillation 과정으로 볼 수 있다.
- Teacher: 기존 DeBERTa reranker
- Student: Provence (rerank + prune 모델)
- 여기서는 passage 하나마다 점수를 예측한다. 그래서 pointwise distillation이다.

- loss 함수 요소 하나씩을 살펴보면
- 1) N은 데이터 포인트 수(질문–문서 쌍의 개수)
- 2) Xn는 Ln + 1개의 입력 토큰 시퀀스이며, query와 passage가 연결되고 0번째 위치에 BOS 토큰이 포함된다.
- Xn 예시 : [BOS] Question tokens + Passage tokens
- 총 토큰 수 = Ln + 1
- +1은 BOS 토큰 때문
- 3) Zn (=Provence(Xn))는 모델이 출력한 Ln + 1개의 예측값 시퀀스
- 4) Z_{i,0} → BOS 토큰에 대한 ranking score
- 5) Z_{i,k} → 각 토큰 k에 대한 pruning 확률
- 6) Yn는 pruning을 위한 Ln개의 정답 binary label 시퀀스
- 7) Sn는 기존 reranker의 teacher score
- 8) Zn,0은 BOS 표현에서 예측된 ranking score
- Unified 모델의 경우, reranking과 context pruning은 encoder의 단 한 번의 forward step으로 수행되며, retrieve >> Provence (rerank 포함) >> generate 구조가 된다. 이로 인해 context pruning은 실행 시간 측면에서 거의 추가 비용이 들지 않는다.
Inference with Provence
- 추론(inference) 시에는 질문과 검색된 passage를 연결(concatenation)하여 Provence에 입력하며, 모델은 최종 context에 각 토큰을 포함할 확률을 출력하고(토큰별 확률), unified 모델의 경우 passage 전체에 대한 점수도 함께 출력한다.
- 토큰 확률을 이진화하기 위해 threshold T를 사용하며(유지/제거 결정), 이는 압축 비율에 직접적인 영향을 준다.
- 아래 실험 파트에서 보이듯이, threshold 값은 다양한 데이터셋에 걸쳐 대체로 그대로 사용할 수 있으며, 이는 모델이 다양한 QA 응용에 out-of-the-box로 활용 가능함을 의미한다.
- provence는 문장 단위 labeling 작업임에도 불구하고 토큰 단위 예측을 출력한다는 점을 강조한다.
- 최종 context에 토큰을 포함할 확률이 자연스럽게 문장 단위로 클러스터링된다는 것을 발견했다.
- 학습 시, 한 문장 전체 토큰 = label 1 또는 문장 전체 토큰 = label 0. 즉, 같은 문장 안의 토큰들은 항상 같은 정답을 받았다. 그래서 모델은 자연스럽게 문장 내부 토큰에 비슷한 확률을 부여하게 된다.

- 그러나 드물게 문장의 일부만 선택되는 경우가 발생할 수 있다.
- Transformer는 문장 구조를 “명시적으로” 이해하지 않는다. 모델은 단지 각 토큰을 독립적으로 확률 예측한다.
- 이 현상을 방지하기 위해 “sentence rounding” 절차를 적용한다.
- 아이디어는 “토큰 단위 예측을 문장 단위 결정으로 변환하자”
- 각 문장에 대해 유지된 토큰(예측값 1)의 비율을 계산한다. 그리고 그 비율이 0.5보다 클 경우에만 문장 전체를 선택한다.
- 문장에 토큰 10개 중 6개가 1로 예측됨 → ratio = 0.6
📍3. Experiments
3.1 Experimental setup
Provence training details
- Section 2에서 설명한 데이터로 Provence를 학습하며, PyTorch와 HuggingFace Transformers 라이브러리를 사용한다.
- Standalone Provence를 학습하기 위해 사전학습된 DeBERTa-v3 모델을 사용한다.
- Unified 접근 방식에서는 이미 학습된 cross-encoder(DeBERTa-v3 기반)에서 학습을 시작한다.
- Unified 모델에서는 ranking head는 기존 fine-tuned 버전으로 초기화하고, pruning head는 처음부터 학습한다.
- 학습률은 3×10⁻⁶, 배치 사이즈는 48로 설정하고 1 epoch 동안 학습한다.
- Joint training에서는 pruning과 reranking 사이에 약간의 trade-off가 존재한다.
- pruning은 token-level 최적화이고 reranking은 passage-level relevance 최적화인데 encoder를 공유하므로 pruning에 유리한 표현이 ranking에 약간 불리할 수 있음
- reranking regularization 계수는 0.05로 설정했으며, 이는 MS MARCO dev set에서 reranking 성능을 크게 저하시키지 않는 최소값으로 선택되었다.
Evaluation datasets
- 다양한 QA 데이터셋에서 Provence를 테스트한다.
- 먼저 Wikipedia 기반 데이터셋인 Natural Questions, TyDi QA, PopQA(단일 hop 질문), 그리고 HotpotQA(멀티 hop 질문)를 고려한다.
- 두 번째로 다양한 도메인(datastore 기반)의 데이터셋을 고려한다: BioASQ(의학), SyllabusQA(교육), RGB(뉴스).

Evaluation settings
- RAG 벤치마킹 라이브러리인 BERGEN을 사용하여, 권장된 실험 설정에 따라 실험을 수행한다.
- 각 질문에 대해 SPLADE-v3와 DeBERTa-v3 reranker로 구성된 강력한 retrieval 파이프라인을 사용하여 상위 5개의 관련 passage를 검색한다 (단, RGB 데이터셋은 Google 검색 결과가 이미 제공됨).
- 그 후 질문 앞에 relevant document(전체 또는 pruning된)를 붙여 LLama-2-7B-chat에 입력하여 답변을 생성한다.
- 각 평가 데이터셋은 짧은 키워드 정답을 제공하며, 이를 사용하여 LLM 기반 평가(LLMeval)를 수행한다.
- pruning된 context의 비율을 compression 지표로 측정한다.
- 모든 context pruner(추상적 RECOMP 제외)에 대해, generator가 문맥을 이해하는 데 혼동이 없도록 첫 번째 문장(제목)을 반드시 선택하도록 강제한다.
- Extractive RECOMP는 NQ에서 학습된 모델을 사용하며, top-1/2/3 문장 설정을 고려하고, 각 문장 앞에 제목을 붙인다.
- LLMLingua 계열 모델(LLMLingua는 원하는 compression ratio를 직접 지정하는 모델)은 compression rate를 0.25, 0.5, 0.75로 변화시키며 공식 코드로 실험한다.
- LLMLingua2(BERT 계열 모델 기반 token pruning)에는 XLM-RoBERTa 모델을 사용한다.
- Provence는 threshold T를 0.1과 0.5로 설정한다.
- DeBERTa-v3 기반 reranker를 사용하는 DSLR(sentence-level pruning 모델,reranker 기반)과도 비교한다.
3.2 Main results

- Figure 2는 다양한 QA 데이터셋과 pruning 방법에 대해 compression(효율성)과 LLM 평가 성능(품질) 간의 trade-off를 보여준다.
- 서로 다른 compression 비율을 같은 표에서 비교하는 대신, 각 데이터셋마다 별도의 그래프를 제시하여 Pareto frontier를 더 잘 평가할 수 있도록 했다.




- 첫째, Provence는 유사한 compression 비율에서 다른 pruning 방법들보다 가장 높은 성능을 달성한다.
- 둘째, Provence는 LLMLingua처럼 더 많은 계산을 요구하는 모델들보다도 더 나은 성능을 보이며, 효율성이 효과성과 교환되지 않았음을 보여준다.
- 또한 Provence는 모든 데이터셋에서 높은 compression 수준에서도 성능 저하가 없거나 거의 없는 유일한 방법이다.
- 더 나아가, 일부 데이터셋(예: PopQA)에서는 Provence로 pruning을 수행할 경우 노이즈 제거 효과로 인해 성능이 오히려 향상된다.
The effect of threshold
- Context pruner를 바로(out-of-the-box) 사용할 수 있는지 여부에서 중요한 요소는 적절한 하이퍼파라미터 값을 설정하는 데 얼마나 많은 노력이 필요한가이다.
- 많은 pruning 모델은 compression ratio를 직접 지정해야 하고, 데이터셋마다 튜닝 필요하고 domain마다 다시 조정해야 한다.
- Provence의 경우, 하이퍼파라미터는 pruning threshold T를 설정하는 것뿐이다.
- Figure 2에서 (T = 0.1과 T = 0.5일 때), Provence의 pruning 비율은 데이터셋에 따라 자동으로 50%에서 80%까지 변한다는 것을 확인할 수 있다.
- Provence는 compression ratio를 직접 지정하지 않는다. threshold만 설정한다. 그런데도 어떤 데이터셋에서는 50% 정도 자르고 어떤 데이터셋에서는 80%까지 자른다.
- 이는 동일한 T 값이 모든 도메인에서 잘 작동한다는 것을 보여주며, Provence가 하이퍼파라미터 선택에 대해 강건함을 의미한다.
Efficiency

- Table 2는 다양한 pruning 방법들이 요구하는 compression 시간과 MFLOPS를 나타낸다.
- Compression time → pruning 단계에 걸리는 실제 시간
- MFLOPS → 연산량 (Million Floating Point Operations per Second)
- 예상대로 LLama-2-7B-chat 기반 LongLLMLingua는 가장 느린 context pruner이다.
- RECOMPabstr.는 MFLOPS는 Provence보다 적지만, autoregressive 특성 때문에 실제로는 더 느리다.
- Unified 모델의 경우 pruning은 re-ranking 단계의 일부이므로 거의 추가 비용이 들지 않는다.
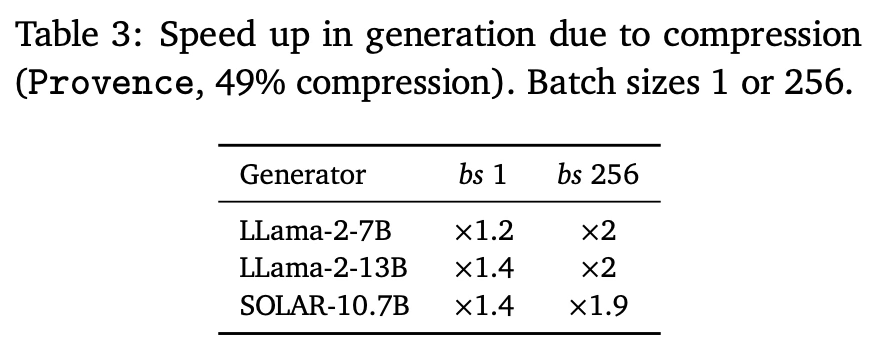
- Table 3은 Provence 모델(약 50% compression)로 인한 속도 향상을 나타낸다.
- 모든 실험은 단일 Tesla V100-SXM2-32GB GPU에서 vLLM을 사용하여 수행되었다.
- 큰 배치 사이즈에서는 inference 시 약 2배 속도 향상을 일관되게 관찰했다.
- 작은 배치 사이즈에서는 속도 향상이 줄어든다 (특히 작은 모델에서). 저자들은 이것이 주로 CPU/GPU 통신 병목 현상 때문이며, compression으로 인한 inference 이득을 가린다고 본다.
4.3. Analysis

Robustness to the position of relevant information in the context
- 간단한 toy 예제를 사용하여 Provence의 성능을 확인하고, 입력 context 내에서 relevant 정보의 위치에 대한 강건성을 평가하기 위해 needle-in-the-haystack 실험을 설계했다.
- 5개의 질문-답 쌍을 작성하고, Wikipedia에서 샘플링한 100개의 passage에 답(“needle”)을 문장 사이의 임의 위치에 삽입했다.
- 이상적으로는 Provence가 “needle” 문장만 선택하고, 나머지 모든 문장은 제거해야 한다.
- 1문장 needle과 2문장 needle의 두 가지 설정을 고려한다.
- Figure 3 (Left)을 보면 Provence가 대부분의 경우 “needle” 문장을 정확히 선택함을 관찰했으며, 예외는 맨 왼쪽 또는 맨 오른쪽 위치에 있을 때이다.
- 대부분의 경우 Provence는 irrelevant 문장을 선택하지 않는다.
- 1문장 needle과 2문장 needle 모두에서 유사한 결과가 나타났으며, 이는 Provence가 relevant 문장의 개수를 유연하게 감지할 수 있음을 보여준다.
Adaptability to the variable number of relevant sentences
- Provence가 문맥에서 relevant 문장의 개수를 동적으로 감지하는 능력을 평가하기 위해, 다양한 데이터셋의 질문-문맥 예시에서 Provence가 선택한 문장 수 L와 silver oracle이 선택한 문장 수를 비교한다.
- L = 0인 경우(즉, relevant 문장이 없는 경우)의 silver oracle은 질문을 무작위로 샘플링된 문맥과 짝지어 쉽게 만들 수 있다.
- L ≥ 1인 경우에는 Llama-3-8B-Instruct가 생성한 labeling을 사용한다.
- Figure 3 (Middle)는 대부분의 경우, 모든 데이터셋에서 Provence가 감지한 relevant 문장 수가 silver oracle 값과 가깝다는 것을 보여준다.
- 반면 extractive RECOMP는 항상 사전에 지정된 개수의 문장을 선택한다.
Robustness w.r.t. context granularity
- Figure 3 (Right)은 서로 다른 granularity(문맥 분할 단위)를 가진 Wikipedia datastore에서 두 데이터셋에 대한 Provence 성능을 보여준다.
- 각 datastore는 Wikipedia 페이지를 𝑁개의 문장(𝑁 ∈ {2, 6, 10}) 또는 100 단어 단위로 나누고, 각 chunk 앞에 페이지 제목을 붙여 생성된다.
- Provence는 모든 경우에서 높은 성능을 보였으며, pruning된 context를 사용한 성능이 원본 context를 사용한 성능과 거의 유사하다.
- 예상할 수 있듯이, context가 길수록 compression 비율은 더 높다.
Reranking effectiveness

- Table 4는 기존 reranking baseline과 unified Provence(그 baseline에서 학습을 시작한 모델)의 reranking 성능을 비교한다.
- pruning과 ranking을 동시에 학습하는 joint training 절차를 통해 초기 reranking 성능을 유지하는 context pruner를 학습할 수 있음을 확인했다.
- 또한 NQ 데이터셋에서 유사한 조건으로 학습된 모델의 결과도 비교 지점으로 포함했다.
- Provence는 MS MARCO로 학습했다. 그런데 NQ로 학습한 모델과 비교했을 때 성능 차이가 크지 않다.
Applicability in different settings

- Figure 8은 다양한 retrieval–generator 설정에서 Provence의 적용 가능성을 보여주며, Figure 2에서 보고된 것과 유사한 결과를 달성함을 나타낸다.
📍4. Conclusion
- 본 연구에서는 QA를 위한 강건하고(adaptable), 효율적인(context pruner) 모델인 Provence를 제안한다. 이 모델은 reranking 기능과 통합된 unified 모델로 사용할 수도 있고, 경량 standalone 모델로도 사용할 수 있다.
- 기존 extractive 방식과 달리, Provence는 각 context에 대해 필요한 pruning 비율을 동적으로 감지하며, 다양한 QA 도메인에서 별도 튜닝 없이(out-of-the-box) 사용할 수 있다.
Limitations
- 논문에서 다양한 설정에서 사용 가능함을 보였지만, Provence는 QA 응용에만 초점을 맞추고 있다.
- 또한 한 번에 단일 passage만 처리한다.
- 그리고 영어 데이터로만 학습되었다.
'Paper Review > RAG' 카테고리의 다른 글
'Paper Review/RAG' Related Articles
more



