

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- RAG
- Parametric RAG
- Baekjoon
- GPT
- NLP
- LLM
- DPO
- Hallucination
- Python
- retrieval
- Statistics
- Algorithm
- DyPRAG
- 파인튜닝
- reranking
- Retriever
- Do it
- COT
- Transformer
- Document Augmentation
- SFT
- Noise Robustness
- moe
- Embedding
- qwen
- lora
- fine-tuning
- Noise
- odds
- coding test
Archives
- Today
- Total
왕구아니다
[논문 리뷰] Retrieval-augmented Recommender System: EnhancingRecommender Systems with Large Language Models 본문
Paper Review/Recommendation System
[논문 리뷰] Retrieval-augmented Recommender System: EnhancingRecommender Systems with Large Language Models
Psalms 12:6-7 2025. 10. 9. 00:36본 논문 리뷰는 저의 개인적인 해석과 의견을 바탕으로 작성된 글입니다.
내용 중 해석의 오류나 개념적인 착오가 있다면, 망설이지 마시고 댓글로 혼내주시면 감사하겠습니다~
Preview
- 추천 시스템의 cold start 문제를 LLM을 이용해 해결하는 방향성 제시
- LLM을 추천 시스템 모델에 결합해 새로운 아키텍처 혹은 시스템을 만들 때 연구가 필요한 4가지 연구 질문 제시
1) LLM은 효과적인 추천을 실제로 제공할 수 있는가?
2) LLM 기반 추천의 한계는 무엇인가?
3) 신규 아이템 추천과 LLM의 환각 문제를 어떻게 해결할 수 있는가?
4) 검색 기반과 생성 기반을 결합하면 추천 품질이 향상되는가?
📍0. Abstract
- 추천 시스템(RS)은 e-commerce부터 콘텐츠 스트리밍까지 다양한 영역에서 사용자 맞춤형 추천을 제공하는 핵심 기술
- RS 단점 : 기존의 RS는 특정 도메인(예: 영화, 음악 등)에서는 높은 성능을 보이지만, 새로운 데이터나 도메인에서는 적응성(adaptability)이 떨어진다는 한계를 가지고 있음
- 최근 NLP의 발전으로 등장한 LLM은 인간 수준의 언어 이해와 생성 능력을 가지고 있음
- LLM 장점 : LLM은 맥락을 이해하고, 학습하지 않은(새로운) 데이터(unseen data)에도 유연하게 대응할 수 있음
- 만약 LLM과 RS를 결합한다면 LLM의 장점으로 RS의 단점을 해결할 수 있지 않을까?
- RS와 LLM을 결합하면 데이터가 부족한 ‘콜드 스타트(cold start)’ 상황에서도 문맥적으로 적합한 추천을 생성할 수 있는 강력한 시스템을 만들 수 있음
- 콜드 스타트(cold start)란?
- 새롭게 들어오거나 특정한 유저들의 데이터를 충분히 확보하지 못하여 유저에 적합한 추천을 하지 못하는 문제
- 따라서 본 논문은 LLM을 RS의 통합 가능성을 탐색하며, 이를 RaRS이라는 새로운 접근법으로 제안
- RaRS는 검색 기반(retrieval-based) 모델의 효율성과 생성 기반(generation-based) 모델의 표현력을 결합하여, RS가 더 맥락적이고 관련성 높은 추천을 제공하도록 향상시키는 접근법
📍0. Introduction
- 정보 과잉 시대인 요즘, 사용자에게 유용한 정보를 찾아 추천하는 것이 중요한 과제로 떠오르고 있음
- 과거에는 협업 필터링(CF), 행렬 분해(MF), 콘텐츠 기반 추천(CB) 같은 전통적 모델이 중심이었으나, 점차점차 연구의 흐름이 딥러닝 기반 추천 시스템(DL-RS)으로 이동하면서 최근에는 그래프 신경망(GNN), 강화학습(RL), 트랜스포머(Transformer) 기반 기법들이 추천 모델의 주류로 자리 잡고 있음
- 그러다 2022년 말 ChatGPT의 등장은 웹상에서 정보 검색과 상호작용 방식을 혁신적으로 바꾼 전환점이 됨
- 그 결과 많은 연구자들의 LLM을 추천 시스템에 통합하려는 시도가 급증함
- 예) BookGPT(LLM을 이용한 도서 추천 프레임워크), Chat-REC(LLM 기반의 대화형 추천 시스템), Generative Recommender(LLM을 활용해 사용자의 요구를 이해하고 능동적으로 제안하는 생성형 추천기)
- 위와 같이 ChatGPT의 성능은 인상적이지만, 그 잠재력을 학문적으로 체계적으로 검증한 연구는 아직 부족하다고 저자는 말함
- 따라서 본 논문의 실험 부분(section 4)에서 ChatGPT가 추천 시스템으로서 정확도 측면에서 얼마나 성능을 내는지 실험적으로 탐구함
- 결과적으로 ChatGPT, 특히 GPT-3.5 모델이 별도의 파인튜닝이나 프롬프트 엔지니어링 없이도 최신 RS 모델들과 유사한 수준의 성능을 보임
- 하지만 ChatGPT가 RS 분야의 정식 도구로 인정받기 위해서는 더 광범위하고 심층적인 연구가 필요
- 따라서 본 논문의 최종 목표는 RS분야에서 LLM에 대한 새로운 관점을 제시하고, 두 가지 구체적 연구 목표를 달성하는 것
- 상위 계층 통합(LLM을 이용해 대화형 AI 기반 추천 시스템) : LLM이 RS 위에 위치한 인터페이스 역할을 함. 즉, 사용자는 ChatGPT 같은 대화형 AI와 대화하지만, 실제 추천 결과는 기존 추천 시스템(RS)에서 가져옴. LLM은 '사용자 질문을 이해 → 적절한 추천 쿼리를 생성 → RS 결과를 받아 대화형으로 설명'하는 중개자 역할
- 하위 계층 통합(LLM의 언어 이해 능력으로 기존 RS를 고도화) : LLM이 RS의 내부 구성 요소로 통합된 구조. 즉, LLM이 직접 추천 알고리즘의 일부를 강화하거나 보조하는 역할. 예를 들어 1) 사용자 리뷰, 상품 설명 등의 텍스트 데이터를 LLM으로 임베딩하여 RS의 입력 피처로 활용, 2) LLM이 생성한 문맥적 유사도를 기반으로 추천 정확도 향상, 3) 신규 아이템 추천 시, LLM이 설명 텍스트를 이해하여 Cold-start 문제 해결
- 이러한 목표를 달성하기 위해 본 논문은 4가지 연구 질문을 중심으로 탐구를 진행
- 1) LLM은 효과적인 추천을 실제로 제공할 수 있는가?
- 2) LLM 기반 추천의 한계는 무엇인가?
- 3) 신규 아이템 추천과 LLM의 환각 문제를 어떻게 해결할 수 있는가?
- 4) 검색 기반과 생성 기반을 결합하면 추천 품질이 향상되는가?
📍2. Large Language Models and Prompt Engineering
- “Attention is All You Need”로 제안된 트랜스포머 구조의 등장이 NLP에 혁신적인 도약을 가져왔으며 이로 인해 ELMo, GPT, BERT 같은 대표적 사전학습 언어모델이 등장함
- Transformer : Attention is All You Need 논문 내용이 궁금하신 분들은 아래 링크 참고해 주세요🫡
- 논문 리뷰 : https://wanggyuuu.tistory.com/3
[논문 리뷰] Transformer : Attention Is All You Need
본 논문 리뷰는 저의 개인적인 해석과 의견을 바탕으로 작성된 글입니다.내용 중 해석의 오류나 개념적인 착오가 있다면, 망설이지 마시고 댓글로 혼내주시면 감사하겠습니다~이번에 리뷰할 "At
wanggyuuu.tistory.com
- 또한 few-shot, chain-of-thought와 같이 명확한 지시(프롬프트)만 잘 주면(프롬프트 엔지니어링), 대규모 파인튜닝 없이도 적은 비용으로도 복잡한 과제의 성능을 크게 향상시켜 LLM의 효과를 더욱 강화할 수 있음
- RLHF와 프롬프트 엔지니어링을 바탕으로, 2022년 11월 말 GPT-3 기반의 대화형 에이전트 ChatGPT가 등장하며 대화형 AI의 새 시대가 열림
- ChatGPT, LLaMA, PaLM 등은 다양한 맥락에서 뛰어난 성능을 보이지만 대표적으로 블랙박스 특성 때문에 추론 과정의 설명 가능성(해석 가능성)이 낮다는 문제가 있음
- 추천 분야에서는 특히 대규모 사전학습의 특성상 지식 최신성 한계가 발생하고(예: 2021년 이후 신규 아이템에 대한 지식 부족), 이 점이 실무 적용의 제약이 됨
- 그럼에도 LLM을 추천 시스템(RS)에 통합하면 기존 RS 방법론의 단점을 보완할 수 있음
- 기존 RS는 평점·명시적 피드백에 의존해 희소성의 한계를 겪는 반면, LLM은 리뷰, 소셜 미디어, 대화 기록 등 텍스트에서 암묵적 선호를 추출함으로써 사용자 선호를 새로운 관점(언어·서술 기반)에서 포착할 수 있음
- 결과적으로 LLM+RS의 결합은 텍스트 기반 맥락 정보를 활용해 더 정확하고 개인화된 추천을 제공하고, 사용자 경험을 전반적으로 향상시킴
📍3. Research Questions and Methodology
(RQ1) Can LLMs provide effective recommendations?
본 연구의 첫 번째 연구 질문으로, LLM이 기존 추천 시스템처럼 사용자에게 의미 있는 추천을 실제로 수행할 수 있는지를 검증하고자 함
- 연구 세팅 & 내용
- 모델 : GPT 3.5 기반 ChatGPT
- 사용 프롬프트 : "Given the following user history, give me 50 recommendations"
- 테스트 데이터 : MovieLens100K, Facebook
- 평가 기준 : Accuracy
- 결과 : ChatGPT가 Zero-shot 환경에서도 효과적으로 작동함. 즉, 사용자 이력에서 문맥적 정보를 추출해 상위 50개의 추천 항목을 생성. 사용자 이력 내 아이템 간 유사성을 파악하여 흥미로운 추천을 제공하는 것으로 보임(= 단순히 통계적 연관성만 보는 기존 CF와 달리, 의미적 유사성을 고려한 추천이 가능함을 시사함). SOTA 추천 모델과 성능 비슷.
- 문제점 : ChatGPT의 블랙박스적 특성 때문에, 추천이 이루어지는 구체적인 이유나 메커니즘을 이해하기 어려움(추천 근거 부족)
- 향후 연구 방향성 : LLM의 추천 성능을 향상시키기 위해, Chain-of-Thought(CoT)나 Tree of Thoughts(ToT)와 같은 고급 프롬프트 엔지니어링 기법을 탐색. 이 접근법을 검증하기 위해, 프롬프트 엔지니어링을 적용한 LLM과 적용하지 않은 LLM의 성능을 여러 추천 데이터셋에서 비교할 예정. 또한 LLM 기반 추천의 작동 메커니즘을 더 깊이 이해하기 위해 질적 분석도 수행(특정 상황에서 추천의 적절성과 일관성을 평가)
(RQ2) What are the limitations of using LLMs for recommendations?
이 연구 질문은 RQ1의 확장선상에 있음. RQ1에서 LLM이 효과적인 추천을 할 수 있다는 가능성을 보였다면, RQ2에서는 그 한계점과 취약 지점을 명확히 규명하려는 단계
- 프롬프트 엔지니어링 기법이 LLM의 정교하고 정확한 응답을 가능하게 해 성능을 향상시킬 수는 있지만, 특히 추천 시스템 맥락에서 이러한 방법의 한계 또는 모델의 한계를 면밀히 검토하는 것이 중요
- 이 질문에 답하기 위해, LLM이 얼마나 추천 다양성(diversity)과 신규성(novelty) 추천을 생성할 수 있는지를 철저히 평가할 예정
- 특히, 분포 밖(out-of-distribution) 아이템 탐색을 방해할 수 있는 인기 편향 문제를 다루고, 추천 과정에서의 우연성을 보장하는 데 초점을 둘 것(LLM은 거대한 텍스트 데이터를 학습했기 때문에, 인기 있는 아이템(ex. Harry Potter)을 과도하게 추천하는 경향이 있음)
- 이러한 요소들을 체계적으로 분석함으로써, 순수 LLM을 추천 시스템에 활용할 때의 실질적 제약 조건(특히 정확도 외의 지표들)에 대한 중요한 통찰을 얻는 것이 목적 -> 단순히 맞춘 정도(nDCG, HR, MAP)뿐 아니라 다양성, 신뢰도, 탐색성, 설명 가능성 등의 차원을 의미)
(RQ3) How to handle the recommendation of new items and alleviate the Hallucination Problem of LLMs?
LLM이 가진 두 가지 핵심 한계 1) 지식의 시점 제한(신규 아이템 추천 불가능), 2) 환각을 동시에 다루는 연구 질문
- LLM을 이용한 신규 아이템 추천은, 모델이 학습 데이터의 시점에 제한된 지식을 갖기 때문에 어려움
- 예를 들어, GPT-3.5는 2021년까지만 학습했기 때문에, 2023년에 출간된 책이나 새로 출시된 영화를 알 수 없음.
- 즉, 정적(static) 지식 기반 모델이 동적(dynamic) 도메인인 추천 분야에 적합하지 않은 구조적 한계를 가지고 있음
- 또한 LLM은 정확하거나 사실이 아닌 허구적 정보를 만들어내는 환각 문제도 가지고 있음
- 예를 들어, 존재하지 않는 영화를 ‘새로운 영화’로 추천하거나, 잘못된 저자 정보를 생성하여 추천할 수도 있음
- 위 문제들을 해결하기 위해선 LLM 재학습하지 않고도 새로운 아이템(정보)을 반영할 수 있는 경량화 방법을 탐색 필요
- 예를 들어, 도메인 지식을 주입하는 방법, 전이학습(transfer learning)과 미세조정(fine-tuning) 기법을 함께 활용하는 방법, 정보 검색 기법(RAG), 사실 검증 메커니즘을 통합(사용자 피드백 활용)
(RQ4) Can the combination of retrieval-based (RS) and generation-based (LLM) methods effectively enhance the quality and relevance of the recommendations?
기존 추천 시스템(RS)은 “정확한 추천”에는 강하지만 “새로운 맥락에의 적응성”이 부족하고, 반대로 LLM은 “언어적 유연성”은 강하지만 “사실 근거와 데이터 일관성”이 부족. 따라서 두 접근을 결합해 ‘정확성 + 맥락성’을 모두 잡는 하이브리드 시스템(RaRS)을 만들겠다는 목표
- LLM과 RS를 결합하는 주요 목적은 전체적인 시스템 성능을 향상시키고, 일반적으로 발생하는 cold-start 문제를 극복하는 것
- 이러한 하이브리드 아키텍처를 평가할 때에는 벤치마크 데이터셋을 이용한 실험 수행과, 기존 추천 시스템 방법들과의 성능 비교를 할 것이며 추가적으로 Retrieval-augmented 추천 접근법에 대한 질적 피드백과 사용자 만족도를 평가할 예정
- 또한 단순히 실험 결과를 얻는 것에 그치지 않고, LLM이 추천 모델 내부의 어떤 층위(상위 대화 계층 or 하위 추론 계층)에서 작동하는 것이 최적인지를 규명하는 목적도 가지고 있음
- Top : LLM을 상위 계층에 두어 최신 RS와 통합된 대화형 AI를 만드는 방식
- Bottom : LLM을 하위 계층에 두어 RS 자체의 지능을 강화하는 방식
📍4. Experimental Settings
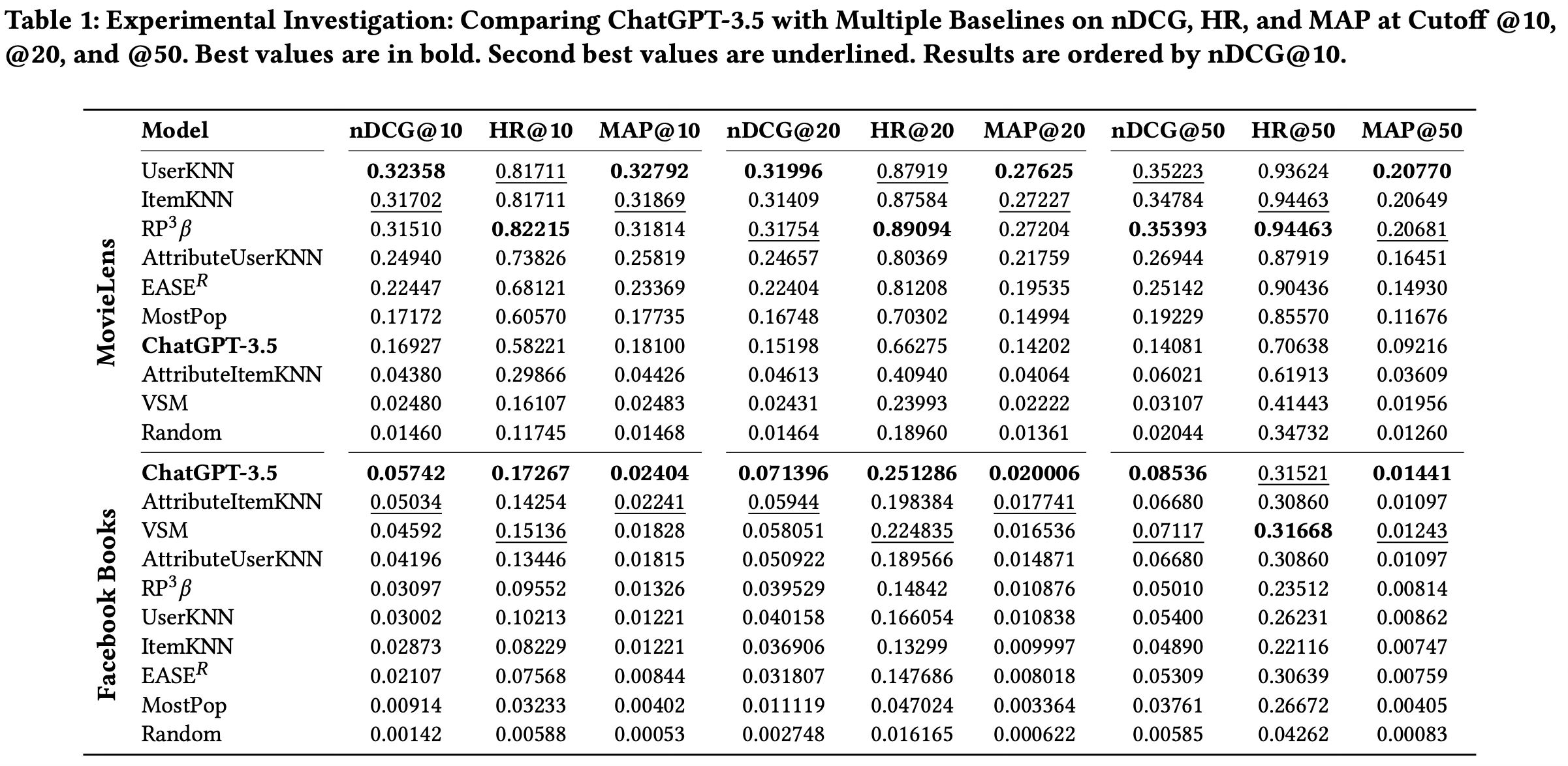
- 추천 시나리오를 해결하는 데 있어 ChatGPT 모델의 역량을 평가
- RQ1에 해당하는 실험 과정
- 사용한 프롬프트
- "Given a user, as a Recommender System, please provide the top 50 recommendations. You know that user [ID] likes the following [movies/books]: {history of items rated by the user}."
- ChatGPT가 자신의 지식을 활용해 추천을 생성할 수 있도록, 데이터셋 내 아이템 이름(예: MovieLens의 영화 제목, Facebook Books의 책 제목)을 프롬프트에 포함
- 사용자별로 위 프롬프트를 적용하고, 그들의 이전 아이템 상호작용 이력을 고려하도록 하여, ChatGPT가 관련도 순서대로 상위 50개의 추천 목록을 생성하게 함
- 모델 : OpenAI의 ChatGPT-3.5-turbo API
- 모델 설정 : 결과의 재현성을 보장하기 위해 temperature 값을 0으로 설정하여 일관된 응답이 생성되도록 함
- 데이터 전처리 : API의 4096 토큰 제한을 해결하기 위해, k-core 값을 10으로 설정하여 사용자-아이템 상호작용을 사전 필터링 진행(= 모든 사용자와 아이템이 최소 10번 이상의 상호작용을 가진 데이터만 사용)
- 평가 진행 : 데이터셋을 학습용과 테스트용으로 분리. Train 데이터 기반 사용자 이력으로 추천 생성. Test 데이터는 nDCG, HR, MAP 지표를 @10, @20, @50 기준으로 계산하는 데만 사용
- 사용한 프롬프트
- baseline 모델들은 Elliot이라는 오픈소스 RS 평가 프레임워크 내에서 전통적인 방식으로 학습과 평가를 수행
- CF 기반 추천 모델은 사용자와 아이템의 ID 정보만을 사용했고, CBF 모델은 장르 등의 콘텐츠 정보를 사용해 학습 (텍스트 정보까지 사용한 ChatGPT와 대조적인 모습)
- Table 1에 기록된 결과를 보면 MovieLens 데이터셋에서는 경쟁력 있는 성능을 보였으며, Facebook Books 데이터셋에서는 탁월한 성능을 보임
- 이 연구 결과로 보아 ChatGPT가 책에 대한 상당한 사전 지식을 갖고 있기 때문에 강력한 추천 시스템으로 기능할 수 있다는 것이 저자의 가설
- 이 실험은 ChatGPT가 zero-shot 환경에서도(별도 학습·튜닝 없이도) 추천 시스템의 과제를 수행할 수 있음을 입증함
- MovieLens 데이터와 Facebook Books 데이터에서 서로 다른 결과가 나온 것으로 보아 도메인 의존성이 존재함
- Section 2에서 말한 것처럼, 고급 프롬프트 엔지니어링 기법(Chain-of-Thought(CoT), Tree-of-Thought(ToT), few-shot prompting)을 적용하면 LLM의 성능을 더 향상시킬 수 있음
- 또한 ChatGPT 계열 모델의 지속적인 진화(예: GPT-4, GPT-4o 등)가 향후 추천 시스템 성능에도 직접적인 영향을 줄 것으로 보임
📍5. Conclusion
- 이 논문은 검색 기반(기존 추천 시스템)과 생성 기반(LLM)을 통합해 RaRS을 만들 수 있는지 실현 가능성을 탐구
- 최종 목표는 추천 정확도 전반을 끌어올리고, 특히 신규 사용자/아이템에서 성능이 떨어지는 cold-start 문제를 완화하는 것
- 논문 전반의 첫 번째 축은 LLM이 RS에서 실제로 어떻게 쓰일 수 있는지를 평가하는 것
- 이를 통해 두 가지 RaRS 구조를 제시함
- Top-layer LLM : SOTA RS 위에 LLM을 올려 대화형 인터페이스/설명/상호작용을 담당하게 함
- Bottom-layer LLM : RS 내부 모듈(예: 재순위화·설명 생성·필터링)을 LLM 능력으로 고도화함
- LLM 통합은 데이터가 희소한 상황(콜드/롱테일)에서도 문맥적으로 적합한 추천을 만들 수 있음
- 검색의 정합성/신뢰성과 생성의 유연한 추론/설명력을 합치면, 기존 RS의 한계를 넘어서 익숙한 도메인(영화·음악 등)은 물론 미개척 도메인에서도 개인화 추천의 폭과 깊이가 확장됨
- 프롬프트 엔지니어링, 구조 개선, 검증·검색 결합 같은 지속적 고도화를 통해, e-commerce부터 streaming platforms 산업 전반의 추천 경험을 혁신할 잠재력이 있음을 전망함
💬 6. Takeaway
학부 연구생(인턴)을 시작하기 위해 교수님을 찾아갔더니 교수님께서 간단한(?) SCIE급 논문을 작성해 보면 좋을 것 같다고 말씀해 주셨다. 사실 'LLM에 관심이 있습니다!'하고 무작정 메일 보내고 찾아갔던 터라 '논문 작성이요?' 당황을 했지만 그래도 좋은 기회라고 생각을 했다. 교수님과 첫 미팅을 하며 엄청 거창한 모델 튜닝 방법론을 연구하는 게 아니라 모델을 어떻게 활용하면 좋은지를 연구하는 방향으로 논문을 작성해 보라는 의미셨다. 미팅이 끝난 후 여러 간단한 논문들을 주며 읽어보라고 하셨고 그중에 이번 논문이 포함되어 있었다.
위 논문을 읽으며 내가 생각하는 논문의 스타일과 많이 달랐다. 보통의 논문들은 모델의 구조를 바꿔보는 실험이거나 기존에는 없던 방법론을 제시하는 내용이었다면 이 논문은 뭔가 실험 부분이 중점이 아닌 자신의 생각을 나열해 놓은 느낌이라 읽으며 살짝 의아했다. 프롬프트도 좀 더 구체적으로 작성해보거나 체계적으로 CoT 방법을 적용해본다거나 아니면 LLM이 추천한 이유를 데이터의 출처 뿐만 아니라 다른 방법으로 설명해 사용자들이 믿을 수 있게 만들거나 했다면 좀더 추천 시스템에 LLM을 붙이는 이유가 명확해지지 않았을까 생각이 든다. 그래서 내 논문 주제는 뭐로.........
'Paper Review > Recommendation System' 카테고리의 다른 글
| [논문 리뷰] ARAG: Agentic Retrieval Augmented Generation for Personalized Recommendation (0) | 2025.10.27 |
|---|
'Paper Review/Recommendation System' Related Articles
more
