

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Document Augmentation
- Algorithm
- Python
- odds
- Statistics
- coding test
- Embedding
- RAG
- Parametric RAG
- LLM
- reranking
- Retriever
- lora
- Baekjoon
- NLP
- COT
- GPT
- DyPRAG
- Noise Robustness
- moe
- fine-tuning
- qwen
- Noise
- DPO
- 파인튜닝
- Do it
- SFT
- Transformer
- retrieval
- Hallucination
Archives
- Today
- Total
왕구아니다
[논문 리뷰] ARAG: Agentic Retrieval Augmented Generation for Personalized Recommendation 본문
Paper Review/Recommendation System
[논문 리뷰] ARAG: Agentic Retrieval Augmented Generation for Personalized Recommendation
Psalms 12:6-7 2025. 10. 27. 20:38본 논문 리뷰는 저의 개인적인 해석과 의견을 바탕으로 작성된 글입니다.
내용 중 해석의 오류나 개념적인 착오가 있다면, 망설이지 마시고 댓글로 혼내주시면 감사하겠습니다~
Preview
- 다중 에이전트 협업 구조(4가지 특화된 LLM 에이전트)를 통합하여 개인화 추천을 수행하는 ARAG 프레임워크를 제안
1) User Understanding Agent : 사용자의 장기 기록과 현재 세션 맥락을 기반으로 취향 요약을 수행
2) NLI (Natural Language Inference) Agent : RAG가 검색한 후보 아이템과 사용자의 의도의도 간의 의미적 일치 정도를 평가
3) Context Summary Agent : NLI 에이전트가 분석한 결과를 요약해, 핵심 문맥을 정리
4) Item Ranker Agent : 맥락 정보를 통합해 사용자에게 가장 적합한 추천 아이템을 순위화
📍0. Abstract
- 외부 지식을 검색해 LLM에 주입시켜 주는 RAG를 사용하게 되면서 추천 시스템을 많이 향상시켜왔음
- 그러나 기존 RAG는 고정된 유사도 기반이기 때문에 시간에 따라 변하는 추천 상황에서 사용자의 미묘하고 복잡한 취향 변화를 제대로 반영하지 못 함
- 따라서 이 논문에서는 사용자의 장기 및 단기(세션) 행동을 더 잘 이해하기 위해, 다중 에이전트 협업 구조(4가지 특화된 LLM 에이전트)를 통합하여 개인화 추천을 수행하는 ARAG 프레임워크를 제안
- 1) User Understanding Agent : 사용자의 장기 기록과 현재 세션 맥락을 기반으로 취향 요약을 수행
- 2) NLI (Natural Language Inference) Agent : RAG가 검색한 후보 아이템과 사용자의 의도 간의 의미적 일치 정도를 평가
- 3) Context Summary Agent : NLI 에이전트가 분석한 결과를 요약해, 핵심 문맥을 정리
- 4) Item Ranker Agent : 맥락 정보를 통합해 사용자에게 가장 적합한 추천 아이템을 순위화
- ARAG 프레임워크를 통해 에이전트 기반 추론을 RAG 추천 시스템에 통합하는 접근이 매우 효과적임을 확인했고, 이 연구는 LLM 기반 개인화의 새로운 방향을 제시하고자 함
📍1. Instroduction
- RAG를 추천 시스템(시나리오)에 적용함으로써 발생하는 다양한 장점은 아래와 같음
- 1) 추천의 정확도와 개인화 수준을 높일 수 있음
- 2) 전통적인 추천 알고리즘에 (단순 기존 DB 검색을 넘어) 실시간으로 다양한 정보 검색 기능을 결합하는 데 활용될 수 있음
- 정적인 DB에 저장된 사용자 선호도나 아이템 속성에만 의존하지 않고, 그 이상의 정보를 활용할 수 있음
- 최근 트렌드, 사용자 리뷰, 전문가 의견, 실시간 시장 데이터 등 다양한 관련 정보를 동적으로 가져와 고려할 수 있음
- 다시 말해, 문맥을 인식하고 최신성 갖춘 추천을 가능하게 함
- ex) RAG를 활용한 영화 추천 시스템을 생각해 보자
- 최근의 비평가 리뷰, 관객 반응, 문화적 트렌드를 검색하고 분석하여 더 시의적절하고 관련성 높은 추천 제공 가능
- 3) 추천 이유를 설명하는 데에도 도움을 줄 수 있음
- 추천의 근거가 되는 정보를 함께 제시함으로써, 사용자의 신뢰와 몰입도를 높임
- 4) 적응적인(adaptive) 특성(실시간으로 외부 문서, 리뷰, 트렌드 데이터 등을 검색해 반영) 덕분에, 추천 시스템은 더 넓은 지식 기반을 활용하여 long-tail items(낮은 빈도의 수요를 가지지만 종류가 매우 다양한 '꼬리 부분' 상품군)이나 신규 사용자도 더 효과적으로 다룰 수 있음
- 즉, 협업 필터링에서 흔히 발생하는 cold start problem를 완화할 수 있음
- 그러나 개선이 필요한 부분(단점)도 존재함
- 1) 추천 환경에서 사용자의 행동을 결정짓는 세밀한 취향과 맥락적 요인을 제대로 포착하지 못함 (= 단순한 코사인 유사도 기반 검색이나 임베딩 매칭만으로는 사용자의 의도를 이해하기 어려움)
- 2) 사용자 선호도의 복잡성과 추천 아이템의 다면적 특성 때문에, 더 정교한 정보 검색 및 매칭 접근법이 필요
- 따라서 본 눈문에서 해결하고자 하는 RAG를 활용한 추천 시스템의 핵심 과제는 단순한 표면적인 텍스트 유사도 매칭을 넘어서, 사용자가 생성한 콘텐츠에 내재된 암묵적 선호, 관심사, 의도를 이해하는 것
- 또한 RAG가 검색해 온 후보 아이템의 순위를 매길 때, 관련성, 다양성, 참신성, 문맥 적합성 등 여러 요인을 동시에 고려할 수 있는 고도화된 랭킹 알고리즘이 필요
- 그래서 향후 RAG 기반 추천 시스템은 보다 정교한 의미적 이해와 시간적 변화를 반영해, 사용자 선호와 아이템 특성을 총체적으로 해석할 수 있어야 함
- 본 논문에서 제안한 ARAG는 여러 분야에서 최근 발전한 Agentic RAG의 원리를 기반으로 하여, 이를 개인화 추천 시스템의 구체적 문제(사용자 맥락 이해, 취향 반영 등)를 해결하는 방향으로 확장시킨 Agentic 기반 RAG 추천 시스템 프레임워크
- 구체적으로, ARAG는 대화형 순위화 작업을 더 효과적으로 수행하기 위해, 사용자의 장기적 행동 데이터를 검색하고, 이를 여러 에이전트에 순차적으로 전달하여 최종 문서(또는 아이템) 랭킹을 동적으로 조정함
- 즉, 각 에이전트가 장기 행동을 다른 관점에서 해석하고 조합해, 맞춤형 추천을 만드는 구조
📍2. Methodology

- [Figure 1]에서 볼 수 있듯이, ARAG 프레임워크의 입력은 두 가지 구성요소로 이루어짐
- 1) 사용자의 장기적 상호작용 기록(long-term context)
- 2) 사용자의 현재 세션 행동(current session)을 반영하는 정보
- 초기 상호작용 이력은 임베딩 기반 유사도를 사용해 의미적으로 관련 있는 후보 아이템(recall pool)을 검색하는 데 활용
- ARAG 프레임워크의 동작 순서는 아래와 같음
- 1) 먼저 기존 RAG 방식을 사용하여 초기 단계의 넓은 범위의 후보 아이템 집합(recall set)을 검색 (RAG Retriever)
- 2) NLI 에이전트가 각 후보 아이템의 텍스트 메타데이터(제목, 설명, 리뷰 등)를 분석하여 각 아이템이 추론된 사용자 의도와 의미적으로 일치하는지를 평가 (NLI Agent)
- 3) 문맥 요약 에이전트가 NLI 에이전트가 필터링과 평가한 결과를 요약하여 핵심 문맥 정보로 정리 (Context Summary Agent)
- 4) 3번과 동시에, 사용자 이해 에이전트는 세션 맥락에 기반해 사용자의 선호를 자연어 요약 형태로 생성 (User Understanding Agent)
- 5) 아이템 순위 에이전트가 앞서 생성된 모든 신호(요약, 문맥, 평가 결과 등)를 통합하여 최종 추천 순위 목록을 만듦. 이때, 사용자의 현재 취향과 과거 선호 모두에 가장 적합한 아이템을 우선적으로 배치 (Item Reranker Agent)
2.1 Formal Problem Statement
- 위에서 ARAG 프레임워크의 입력은 두 가지로 구성된다고 했다
- 1) 장기 문맥 (Cₗₜ) : 사용자의 과거 상호작용을 포착하는 정보
- 2) 현재 세션 (Cₛₜ) : 사용자의 최근 행동을 반영하는 정보
# 기호 정리
1) 사용자의 통합 맥락 (U)
U = (Cₗₜ, Cₛₜ)
2) 추천될 수 있는 모든 후보 아이템의 집합. 각 아이템 i는 텍스트 기반 메타데이터 T(i)를 갖는데, 제목, 설명, 리뷰 등이 이에 해당
I = {i₁, …, iₙ}
3) ARAG의 최종 목표는 아이템 집합 𝓘에 대해, 최종적으로 랭킹 혹은 순열(permutation) π를 생성하는 것
→ 즉, 𝓘에 포함된 아이템들을 “사용자에게 얼마나 관련성이 높은가”의 순서로 정렬하는 함수가 필요
π = fᴿᵃⁿᵏ(u, I)
2.2 ARAG Framework
ARAG를 구성하는 각 컴포넌트를 살펴보자
2.2.1 Initial cosine similarity-based RAG
- 먼저 RAG를 사용해 전체 아이템 집합 I 중 초기 후보 아이템 하위 집합 검색

- 아이템과 사용자 문맥을 모두 공유된 d차원 임베딩 공간으로 매핑하는 임베딩 함수가 있다고 가정하면 아래와 같음

- 상위 k개의 유사한 아이템을 아래 식으로 선택. 사용자 임베딩과 가장 유사한 아이템 임베딩을 유사도 기준으로 정렬하여 상위 k개를 선택 (임베딩 간의 유사도는 sim 함수(예: 코사인 유사도)를 통해 계산)
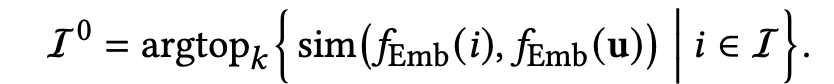
- 이렇게 얻어진 I0가 크기 k의 초기 recall set이며, 이후 단계의 에이전트들에 의해 정제됨
2.2.2 NLI Agent for Contextual Alignment
- 다음으로 NLI 에이전트는 I0의 각 아이템 i에 대해 그 아이템의 텍스트 메타데이터 T(i)가 사용자 문맥 u과 얼마나 잘 맞는지를 평가
- 아래는 NLI 에이전트가 산출한 정렬 점수(alignment score)를 의미하며, Phi는 LLM 기반의 추론 함수

- 점수가 높을수록 해당 아이템 i가 사용자의 관심사와 강하게 일치하거나 잘 부합한다는 뜻
2.2.3 Context Summary Agent
- Context Summary Agent는 NLI 에이전트가 '사용자 문맥과 충분히 일치한다'고 판단한 아이템들만 모아, 해당 아이템들의 텍스트 메타데이터를 요약
- 여기서 I+는 NLI 점수가 일정 기준 이상인 아이템 집합

- 결국 Context Summary Agent가 NLI가 판단한 아이템들만 요약본을 생성하는 과정을 식으로 표현하면 아래와 같음 (I+에 포함된 아이템들의 텍스트 메타데이터 T(i)를 LLM 기반 요약 함수를 이용해 요약)
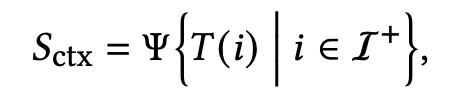
2.2.4 User Understanding Agent
- 위에서 Context Summary Agent는 각 아이템의 요약본을 생성했다면 User Understanding Agent는 사용자의 통합 맥락 U = (Cₗₜ, Cₛₜ)에 대한 요약본 생성
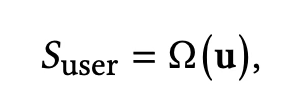
- 사용자 문맥 u을 입력으로 하는 LLM 기반 추론 함수를 이용해 사용자의 전반적 관심사와 현재의 즉각적 목표를 자연어로 표현한 설명을 생성
2.2.5 Item Ranker Agent
- 마지막으로, Item Ranker Agent는 앞서 생성된 S_user(사용자 요약)과 S_ctx(아이템 문맥 요약)을 입력으로 받아 최종 순위를 ranking
- Item Ranker Agent는 다음 prompt에 따라 작동함
- 1) 이전 세션에서의 사용자 행동을 고려하고
- 2) 사용자 이력 중 현재 랭킹 작업과 관련된 부분을 참조하며
- 3) 후보 아이템들을 검토하고
- 4) 구매 가능성이 높은 순으로 내림차순 정렬한다
- [Figure 1 참고] 예를 들어, 사용자 요약에 “비건 가죽 제품, 체크무늬 가방, 세련된 액세서리”에 대한 관심이 명시되어 있다면, Item Ranker Agent는 Dasein Hobo 핸드백보다 BUTIED 체크무늬 토트백을 더 높은 순위에 둘 수 있음(이는 재질(material)과 스타일(style) 모두에서 사용자 취향에 더 부합하기 때문)
- Item Ranker Agent의 작동 원리는 아래와 같음. 전체 후보 아이템 I 에 대해 최종 순열 π = {r_1, r_2, …, r_n}을 산출

2.3 Agent Collaboration Protocol
ARAG의 구현 절차를 더 명확히 설명하기 위해, 이 절에서는 에이전트 간의 협업 프로토콜을 정의 (각 에이전트가 언제 실행되고 어떤 데이터를 주고받는지를 구조적으로 설명하는 부분)
- ARAG는 블랙보드(blackboard) 스타일의 다중 에이전트 시스템으로 구현되었고, 모든 에이전트는 공유된 구조적 메모리 B (shared structured memory B)에 데이터를 읽고 쓰는 방식으로 상호작용함
- Blackboard architecture : 여러 지능형 모듈이 공통 메모리(블랙보드)에 정보를 남기고 이를 다른 모듈이 참조하는 협업 구조를 뜻함
- 각 에이전트는 JSON 구조의 메시지 객체 m {id, role, content, score, timestamp} 을 메모리 B에 작성. 이로써 후속 에이전트들은 단순히 원시 데이터(raw data)뿐 아니라, 이전 에이전트들이 남긴 추론 근거까지 참고해 더 높은 수준의 판단을 내릴 수 있음
- Parallel inference
- User Understanding Agent와 NLI Agent는 동시에 병렬로 실행됨
- User Understanding Agent는 사용자 선호 요약인 m_user를 메모리 B에 기록하고, NLI 에이전트는 그 아이템의 텍스트 메타데이터 T(i)가 사용자 문맥 u과 얼마나 잘 맞는지를 평가한 벡터 m_nli를 기록
- Cross-agent Attention
- Context Summary Agent는 m_user와 m_nli 두 정보를 모두 참조함
- 사용자 요약 m_user는 관련성 우선순위, NLI 점수 m_nli는 가중치로 사용
- 이 정보를 바탕으로 문맥 요약 S_ctx를 구성하고, m_ctx로 메모리 B에 기록
- Final Ranking
- 이전 단계에서 생성된 두 개의 메시지인 사용자 요약 m_user와 문맥 요약 m_ctx을 입력으로 받아, 최종 추천 순위 리스트 생성
- 또한, 각 추천 결과에 대한 추론 근거도 함께 산출
- ARAG는 각각의 전문적인 하위 작업(NLI, 요약, 사용자 이해, 랭킹)을 서로 다른 대형 언어모델(LLM) 에이전트에 분담함으로써, 다음 세 가지 주요 기능을 가능하게 함
- 1) 맥락 인식 : 사용자의 장기 행동과 단기 행동이 모두 최종 랭킹 결정 과정에 반영됨
- 2) 의미적 근거 : NLI 에이전트와 요약 에이전트는 추천 결과의 정확도를 높이고, 동시에 설명 가능성을 강화함
- 3) 개인화 : 최종 점수는 사용자의 고유하고 변화하는 선호도를 반영. 이를 통해 추천 결과가 항상 관련성을 유지하면서, 사용자의 변화에 유연하게 적응할 수 있음
📍3. Experiments

3.1 Dataset
- Amazon Review 데이터셋(He & McAuley, 2016) 사용
- 여러 카테고리 전반에서 무작위로 10,000명의 사용자 선택 후 사용자–아이템 상호작용 부분집합을 실험에 사용
- 사용자의 리뷰 항목
- 시간 정보(timestamps)
- 평점(ratings)
- 텍스트 피드백(textual feedback)
- 상품 메타데이터(product metadata)
- 데이터가 가지고 있는 추천 시스템의 난제들
- 희소한 상호작용 행렬(sparse interaction matrices)
- 시간에 따른 사용자 선호 변화(shifting user preferences)
- 다양한 제품 분류체계(diverse product taxonomies)
3.2 Benchmark Models
[Table 1 참고]
- Recency-based Ranking
- 단순한 시간적 휴리스틱(temporal heuristic)을 사용한 모델
- 사용자의 가장 최근 상호작용이 현재의 선호를 가장 잘 반영한다는 가정을 기반으로 한 모델
- 이 모델은 추가적인 필터링 없이, 최근 아이템들을 직접 LLM 프롬프트에 추가
- 시간적으로 더 먼 과거의 상호작용보다는, 가장 최근의 행동을 우선시함으로써 단순성과 계산 효율성을 얻음
- Vanilla RAG
- 임베딩 기반 검색을 활용하여, 사용자의 과거 상호작용 기록 중에서 의미적으로 유사한 항목을 찾아냄
- 이렇게 검색된 관련성 높은 항목들은 LLM 프롬프트에 추가하여 추천 생성 시 맥락(context)으로 활용됨
- GPT-3.5-turbo (v0125) 모델을 사용
- 실험의 재현성을 높이기 위해 temperature 파라미터를 0으로 설정
3.3 Results
- 평가지표
- NDCG@5 : 추천 정확도(순위 품질)
- HIT@5 : 적중률(추천 성공률)
- 결과 해석
- 성능 향상률(%)을 보면, 의류(Clothing) 도메인에서 가장 높음
- 주관적인 선호가 높은 도메인에서 Agent들이 개인의 취향을 유의미하게 파악하는 것 같음
- Agentic RAG의 효과가 도메인 특성에 따라 다를 수 있음을 시사
3.4 Ablation Study
- ARAG의 각 에이전트(모듈)가 전체 성능에 얼마나 영향을 미치는지 살펴보자
- Vanilla RAG + User Summary Agent
- 모든 도메인에서 일관된 성능 향상
- 정적 임베딩 기반 검색만으로는 부족하며, 사용자 선호 요약이 추천의 맥락 적합성(context relevance)을 높이는 데 중요한 역할을 한다는 점을 확인
- Vanilla RAG + User Summary Agent + Context Summary Agent
- 특히 의류 도메인에서 성능이 크게 향상
- 호환성과 스타일이 중요한 카테고리에서는 아이템 수준의 맥락 이해가 핵심적이라는 점을 시사
- ARAG
- 자연어추론(NLI)을 통한 의미적 추론이 사용자 의도와 후보 아이템 표현 사이의 간극을 효과적으로 메운다는 점을 시사
📍4. Conclusion
- ARAG는 검색 기반 추천을 단순한 검색 과정이 아닌, 4개의 특화된 LLM 에이전트가 협력하는 추론 task로 재정의
- ARAG는 사용자 이해, 의미 정렬, 맥락 통합 그리고 순위 결정의 역할을 명확히 분리함으로써, 단순 임베딩 기반 검색 결과를 세밀하게 필터링되고 의미적으로 정교한 후보 리스트로 변환
- 이러한 결과는, RAG 프로세스 내부에 에이전트 협업을 통합하는 접근법이 고도의 개인화와 맥락 인식을 갖춘 추천을 구현하기 위한 효율적이고 실용적인 방법임을 보여줌
💬 5. Takeaway
LLM의 별다른 튜닝 없이도 기존 대비 성능이 향상된 추천 시스템 아키텍처를 구상했다는 것에 신기했다. 이제 LLM 프롬프트만으로 어느 정도의 성능이 나오는 거로 봐서는 LLM한테 얼마나 정제되고 정확한 정보를 프롬프트에 어떻게 삽입시켜 주는지가 중요해진 것 같다.
'Paper Review/Recommendation System' Related Articles
more
