

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- moe
- Do it
- Statistics
- 파인튜닝
- Transformer
- Hallucination
- Algorithm
- Document Augmentation
- DyPRAG
- NLP
- RAG
- GPT
- lora
- Retriever
- Baekjoon
- SFT
- fine-tuning
- Python
- Noise
- coding test
- Parametric RAG
- odds
- Noise Robustness
- DPO
- qwen
- reranking
- COT
- retrieval
- Embedding
- LLM
- Today
- Total
왕구아니다
[논문 리뷰] RankCoT : Refining Knowledge for Retrieval-Augmented Generation through Ranking Chain-of-Thoughts 본문
[논문 리뷰] RankCoT : Refining Knowledge for Retrieval-Augmented Generation through Ranking Chain-of-Thoughts
Psalms 12:6-7 2025. 5. 23. 21:58본 논문 리뷰는 저의 개인적인 해석과 의견을 바탕으로 작성된 글입니다.
내용 중 해석의 오류나 개념적인 착오가 있다면, 망설이지 마시고 댓글로 혼내주시면 감사하겠습니다~
Preview
- RAG 파이프라인 안에서 LLM이 불필요한 문서로부터 혼란을 겪는 문제를 해결하기 위해 제안된 지식 정제 기법
- RAG 파이프라인 안에서 질문과 검색된 문서를 RankCoT 모델을 이용해 답변 생성에 필요한 CoT를 생성(self-refined or
reranked CoT 생성)
- 최종 답변은 질문과 앞서 생성된 CoT를 바탕으로 LLM이 생성
Link
- 논문 : https://arxiv.org/abs/2502.17888
- 코드 : https://github.com/NEUIR/RankCoT
논문 읽기 전...
RAG 파이프라인 안에서 Knowledge Refinement란 무엇인가
특정 도메인에 특화된 LLM을 개발하는 방법으로는 크게 두 가지 접근 방식이 있다. 하나는 사전 학습된 LLM을 도메인 데이터로 추가 학습시키는 Fine-tuning, 다른 하나는 질문에 맞는 문서를 외부에서 검색해 LLM에 주입하는 Retrieval-Augmented Generation(RAG) 방식이다. 최근에는 Fine-tuning이 높은 비용과 많은 자원을 요구하기 때문에, 효율성과 확장성을 고려한 RAG 방식이 점차 각광받고 있다.
RAG 시스템의 성능은 “얼마나 정밀한 문서를 LLM에 넣어주느냐”에 크게 달려 있다. 사용자의 질문에 가장 관련성 높은 정보를 정확히 전달하지 못하면, LLM이 아무리 뛰어나도 엉뚱한 답변을 생성할 수 있다. 이처럼 검색된 문서 중에서 불필요한 정보를 걸러내고, 가장 유의미한 문서를 선별·정제하는 과정이 바로 RAG 파이프라인 내의 Knowledge Refinement이다.
대표적인 방법으로는 Cross-Encoder 기반의 문서 재정렬(Reranking) 기법이 있다. 이 방식은 먼저 벡터 데이터베이스에서 질문과 유사한 Top-N 문서를 추출한 후, 질문과 각 문서의 쌍을 Cross-Encoder에 입력하여 유사도를 다시 계산하고 문서를 재정렬하거나 상위 문서만 선택한다. 최근에는 LLM 자체를 활용한 재정렬 방식도 연구되고 있으며, 문서의 순서를 조정해 LLM의 attention 효율을 높이는 Long Context Reordering(https://arxiv.org/abs/2307.03172) 기법도 있다. (아마 다양한 방법론의 논문들이 있을 텐데 전 기본만 설명하겠습니다....)
또한, 초기 검색 단계에서 질문과 관련 없는 문서(Noise)가 섞여 들어올 가능성도 존재하기 때문에, 이러한 문서에 대해 LLM이 더 강건하게 판단할 수 있도록 학습시키는 전략(https://wanggyuuu.tistory.com/1) 또한 Knowledge Refinement의 범주에 포함된다.
결론적으로, Knowledge Refinement는 RAG의 전반적인 성능을 높이기 위한 핵심 요소로, 질문에 가장 적합한 문서를 선택하고 구조화하여 LLM이 정답을 도출하기 쉬운 환경을 만들어주는 과정이라 할 수 있다.

그렇다면 이제 RankCoT 논문에서는 어떻게 Knowledge Refinement를 수행했는지 읽어보겠습니다 🙃
📍0. Abstract
- RAG의 한계
- 검색된 문서들 중에 관련 없는 문서도(노이즈) 포함하고 있기 때문에 관련 있는 문서만 가지고 정확한 답변을 내기에는 어려움이 있음
- 이런 문제를 바탕으로 RakCoT는 지식 정재(knowledge refinement)를 위해 질문과 검색된 문서들 간의 CoT 기반으로 요약본을 만들고 이를 reranking signal로 사용
- RankCoT 학습 과정
- CoT 후보 생성 : 질문과 검색된 각각의 문서들 간의 CoT 후보들을 생성
- 재정렬 기반 학습 : 생성된 CoT 후보들 중에서 가장 적절한 것을 선택하고, 이를 재현하도록 LLM을 미세 조정. 이 과정에서 LLM은 관련 없는 문서를 필터링하는 능력을 학습
- 자기반성 메커니즘 : LLM이 생성한 CoT를 스스로 평가하고 개선하여 더 높은 품질의 학습 데이터를 생성
- Generator 모델한테 더 짧고 효과적인 요약을 제공하며, 관련 없는 정보를 효과적으로 제거하여 응답의 정확성을 향상시킴
📍1. Instroduction
- RAG는 외부 지식을 검색해(보통 dense retrieval method 사용) 질문과 같이 LLM한테 넣어줌으로써 질문과 관련성 있는 답변 생성
- 그러나 여전히 정밀한 답변을 생성함에 있어서 외부 지식과 LLM 자체(parameterized memory) 학습 데이터 간의 충돌이 어려움으로 자리 잡고 있음
- Knowledge Refinement 방법으로 재정렬(reranking) 모델을 사용하더라도 여전히 선별된 문서들을 LLM에 입력해야 하므로, 문서 전체가 관련 있어 보이더라도 그 안에 포함된 질문과 무관한 내용이 생성 모델(LLM)을 혼란스럽게 만들 수 있음
- 즉, 문서가 “관련 있음”으로 분류되었다고 해서, 그 안의 모든 내용이 유용하다는 보장은 없으며, 이러한 비관련 정보들이 답변 품질을 저해할 수 있다는 한계가 존재
- 위 문제(reranking)를 프롬프팅을 통해 검색된 문서로부터 질문과 관련 있는 지식들을 요약함으로써 해결하기도 함
- 그러나 질문과 관련 없는 문서에 대해서도 요약하기 때문에 오히려 노이즈가 될 수도 있음
- 재정렬(reranking)과 요약(summarization) 모듈은 각각 Knowledge Refinement를 위한 장점을 가지고 있지만, 기존의 RAG 시스템에서는 이 두 모듈이 보통 서로 분리된 형태(reranking 수행하고 summarization 수행)로 동일한 LLM을 단순히 프롬프트 방식으로 호출하여 구현
- 즉, 정제와 요약을 통합적으로 다루지 못하고 독립적으로 처리하기 때문에, 정보 품질을 극대화하는 데 한계가 있는 구조
RankCoT
- 문서 재정렬(Ranking)과 요약(Summarization)의 장점을 결합하여 검색 결과를 효과적으로 정제하는 Knowledge Refinement 방법

- RankCoT 모델을 이용한 답변 생성 과정
- RankCoT는 질문과 검색된 모든 문서들을 입력으로 받아, Chain-of-Thought(CoT) 기반의 요약을 생성
- 이러한 방식으로 생성된 CoT 기반의 요약본은 LLM이 질문에 대해 더 정확한 응답을 생성하는 데 도움을 줌
- RankCoT 학습 과정
- 핵심 목표는 질문에 대해 가장 유효한 문서로부터 CoT 스타일 요약을 생성하도록 LLM을 학습시키는 것
- 1) 질문 + 검색된 문서 입력
- 2) 각 문서별로 LLM이 CoT 스타일 추론 과정 생성
- 여기서 CoT는 일종의 “문서 기반 요약 + 추론”이라 보면 됨
- 이때 Self-Refinement (자기 정제) 과정을 거침
- 위에서 생성한 CoT들을 다시 LLM에 넣고 질문에 대한 최종 정답을 생성
- 여러 CoT 후보 중, 정답을 포함하는 CoT → Positive
- 그렇지 않으면 → Negative
-
- 3) Fine-tuning
- 위에서 만들어진 데이터 (질문 + 문서 + CoT + Positive/Negative 라벨)를 가지고 LLM을 CoT 생성 능력에 대해 fine-tuning
- 질문에 가장 적합한 문서가 있을 때 → 좋은 CoT를 만들도록 학습
- 관련 없는 문서일 경우 → 잘 걸러내고 CoT를 생성하지 않도록 학습
📍2. Related Work
- 외부 문서를 검색해 LLM한테 넘겨주는 RAG는 NLP 많은 task에서 답변 성능을 높임
- 그러나 문제점 존재
- 외부에서 가져온 지식과 LLM이 파라미터에 저장하고 있는 기억이 서로 충돌하는 경우가 자주 생기는데, 이런 충돌이 현재의 RAG 시스템의 성능을 약화시킴
- ( = RAG 시스템이 의도한 대로 외부 지식에 의존해서 답을 생성하지 못하고, LLM이 원래 알고 있던 잘못된 정보에 끌려가는 문제가 생김)
- 검색된 지식의 부정적인 영향을 줄이기 위해 많은 연구들이 있음
- Reranking
- 문제점 = 각각의 문서들 안에 있는 noise를 간과함
- query-focused summarization
- 문제점 = 쿼리와 문서의 관련성을 간과 = 요약본에 관련 없는 내용 추가됨
- Reranking
- Chain-of-Note 논문
- LLM이 주어진 질문에 답할 때, 질문과 관련된 메모(note)를 먼저 작성하게 유도하는 방법을 시도
- 답을 바로 생성하지 않고 노트 정리하면서 지식 정제 과정을 추론하는 단계 안에 통합시킴
- LLM의 순수한 능력에 너무 의존하는 문제 있음
- Modular RAG systems
- 다른 모듈에서 LLM을 이용해 외부 지식을 정제하는 과정을 거침
- Self-RAG
- 각기 다른 태그의 검색기를 써서 self-reflection을 통해 지식을 정제
- DPO 방식도 있음
📍3. Methodology

- 3.1은 RAG 시스템 내에서 지식을 어떻게 정제하는지를 설명
- 3.2는 LLM이 더 효과적인 CoT를 생성하여 지식을 정제할 수 있도록 최적화하는 방법
3.1 Preliminary of Knowledge Refinement in Retrieval-Augmented Generation Systems
- 먼저 RAG 시스템 안에서 지식을 정제해 답변을 생성하는 흐름을 살펴보겠음
- D= {d1, d2,..., dn} : 검색된 문서들
- MGen : 모델
- yGen : 답변
- MKR : 지식 정제 모델
- yKR : 정제된 문서들



- 이제 MKR을 어떻게 구현하느냐에 따라 Reranking, Summarization, RankCoT 방식으로 나뉨
Reranking

- D안에 있는 각 문서 dᵢ에 대해 LLM이 q와 얼마나 관련 있는지 판단하여 “YES/NO” 이진값 yᵢRerank를 예측

Summarization
- 검색된 전체 문서 집합 D에서 q와 관련 있는 문서를 뽑는 것을 목표로 질문에 맞는 요약본 생성

RankCoT
- 기존 Summarization 방식과 비슷하게 D 전체를 넣지만, CoT 스타일의 요약본 생성

- 여기서 기존 Summarization 방식과 중요한 차이점
- RankCoT는 noise 문서의 영향력을 줄이기 위해 CoT 생성 과정에 reranking mechanism도 통합 (3.2절에서 설명)
3.2 Knowledge Refinement through Ranking Chain-of-Thoughts
- RankCoT는 CoT를 생성하는 과정에서 reranking을 포함해 LLM 최적화
- RankCoT를 학습할 때 원하지 않은 CoT형식으로 과적합 되는 것을 막기 위해 CoT 결과를 refine 하는 self-reflection 방법 소개
3.2.1 Reranking Modeling in CoT Generation
앞서 설명한 "CoT 생성 과정에 reranking을 통합했다" 무슨 뜻일까? -> RankCoT 모델을 학습시킨 방법에 답이 있다
- 질문(q)과 검색된 전체 문서 집합(D)을 주고 CoT 스타일 요약본을 생성하도록 LLM에게 지시하되, 미리 DPO 방식으로 학습을 진행하여, LLM이 CoT를 생성 시 어떤 문서 기반 CoT가 정답을 포함할 가능성이 높은지 학습하게 하고, 결국 "정답이 포함된 CoT"를 더 잘 생성하고 선호하도록 최적화한다
- RankCoT의 yKR은 단순한 요약이 아니라, reranking signal이 내재된 고품질 CoT 기반 요약본
- 데이터 준비
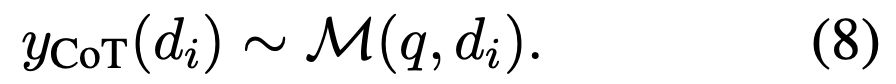

- DPO 학습
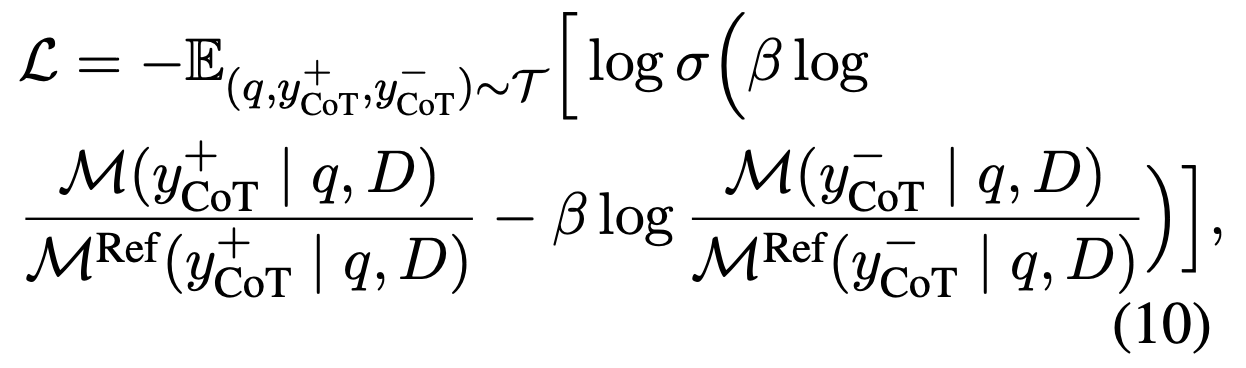
- DPO 학습 시 입력값 설명
- q: 질문
- D: 검색된 문서 집합
- y+CoT: 긍정적인 chain-of-thought 결과 (Positive Refinement)
- y-CoT: 부정적인 chain-of-thought 결과 (Negative Refinement)
- B : 스케일링 하이퍼파라미터 (score 차이에 민감도를 조절)
- M : 학습시키는 모델(LLM)
- MRef : 참조 모델(학습 과정에서 비교 기준으로 사용하는 고정된 모델)
- 수식의 동작 구조
- Positive/Negative 결과의 로그 확률 비율을 비교 (모델이 참조 모델보다 얼마나 더 좋은 응답에 대해 확신하는지를 측정)
- 시그모이드로 로짓 비교
- 전체 손실을 음수 expectation으로 정의하여, 이 값이 작아지도록 (= 확률 차이가 커지도록) 학습
- 결론 : Positive/Negative 결과의 로그 확률 비율 클수록(최대화) → 시그모이드 값은 1에 가까워짐 → 로그는 0에 가까워짐 → 손실은 작아짐
3.2.2 CoT Refinement through Self-Reflection
- 기본적으로 LLM한테 "CoT 스타일 답변 생성해 줘"라고 프롬프팅을 하면 “According to the document” 와 “the rea-soning process is” 같은 불필요한 문구도 포함이 됨
- 본 논문에서는 이러한 불필요한 문구들이 학습 도중 해당 데이터에 대한 과적합을 만드는 요소라고 이야기함
- 그래서 위에서 설명한 DPO에 사용할 데이터들을 Self-Reflection 과정을 거쳐서 만듦
- CoT 정제(Self-Reflection) 과정
- 논문 저자들은 같은 LLM한테 스스로 생성한 CoT를 넣어줌으로써 Self-Reflection 효과(최종적으로 좀 더 query에 관련 있는 내용을 추축)가 있다고 말함 ((12) 번 과정)



📍4. Experimental Methodology
Datasets
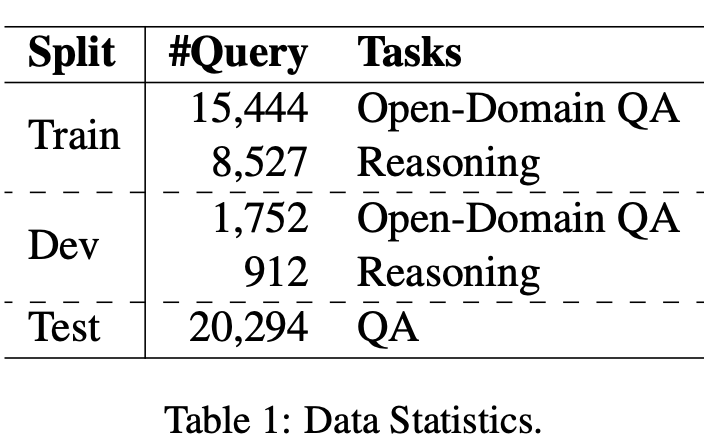
- MS MARCO V2.1 데이터 collection 안에서 BGE-large retriever 사용해 문서 검색
- 총 6개의 평가 데이터셋 사용
- NQ
- HotpotQA
- Trivia QA
- PopQA
- ASQA
- MARCO QA
Baselines
- Vanilla RAG (5개 문서 검색)
- Reranking + Vanilla RAG (LLM 프롬프팅을 통해 질문과 관련 있는 문서는 "yes" / "no" 출력시키고 "yes"인 문서만 남김)
- Summarization + Vanilla RAG
- CoT + Vanilla RAG
- 추가적으로 MiniCPM3-4B, Qwen2.5-14B-Instruct처럼 다양한 크기의 모델을 사용해 RankCoT의 일반화 성능을 점검
Evaluation Metrics
- MARCO QA task에서는 Rouge-L을 평가 metric으로 사용
- ASQA에서는 String-EM을 평가 metric으로 사용
- 다른 task에서는 Accuracy를 사용
Implementation Details
- Llama3-8b-Instruct을 backbone model로 사용
- DPO training dataset을 만들기 위해 10개의 검색된 문서들 각각 CoT(답변 전 추론 부분)를 생성(Llama3-8b-Instruct)하고 같은 모델(Llama3-8b-Instruct)에 다시 넣어서 개선(Self-Reflection)
- LoRA 사용했고 B = 0.1 / lr = 2e-5
📍5. Evaluation Result
5.1 Overall Performance

- 결과 보면 summary / CoT보다 rerank 지식 정제 기법이 대부분 성능이 좋음
- 그러나 RankCoT는 rerank 보다 좋음
- 다양한 모델에서도 RankCoT 방식이 좋은 성과 거둠 = 범용성 굿
5.2 Ablation Study

- self-reflection 메커니즘의 효과 실험
- 기본 RAG
- 파인튜닝된 LLM + RAG
- SFT (self-reflection 메커니즘 포함)
- DPO (self-reflection 메커니즘 포함)
- 결론
- QA supervision으로 파인튜닝된 모델은 다양한 프롬프트에 따라 knowledge refinement 결과를 생성할 수 있었지만, 실험 결과, 이 모델들은 기본 RAG보다 효과가 떨어짐
- 반면, LLM이 생성한 self-refined CoT를 학습 신호로 사용한 결과, SFT에서는 Rerank 모델이 가장 좋은 성능, DPO 방식에서는 Summary와 RankCoT 모두 큰 향상
- 특히 RankCoT는 모든 knowledge refinement 모델 중에서 가장 뛰어난 성능을 보임
- 또한 DPO 학습 시 self-refined CoT 대신 초기 CoT(raw CoT)를 사용하면 성능이 1.3% 하락함. 이는 self-reflection 메커니즘의 효과를 잘 보여줌
5.3 Knowledge Usage Performance of Different Refinement Models

- RAG 시스템에서 서로 다른 Knowledge Refinement의 능력을 다음 세 가지 상황에서 실험
- Has-Answer : 검색된 문서가 정답을 포함
- 얼마나 지식 정제 모델들이 효과적으로 문서에서 중요한 정보를 잘 추출하냐
- Miss-Answer : 검색된 문서가 정답을 포함하지 않음
- 얼마나 지식 정제 모델이 검색된 noise를 최소화하냐
- Internal Knowledge
- 내부 지식과 외부 지식의 충돌을 얼마나 잘 다루냐
- Has-Answer : 검색된 문서가 정답을 포함
- 결론
- RankCoT는 정답 추출, 노이즈 제거, 지식 충돌 완화 모두에서 가장 안정적인 성능을 보여줌
- 단순한 요약이나 Rerank 기반보다 정교한 CoT 기반 지식 정제 방식이 효과적임을 입증
5.4 Characteristics of the Refined Knowledge Produced by RankCoT
Refinement Quality

- 질문과의 유사도
- 측정 방법 : BGE 임베딩 모델로 질문과 정제된 지식 간의 텍스트 유사도 측정
- 결과
- RankCoT가 가장 높은 유사도 점수 달성 → 질문과 더 밀접한 정보를 잘 보존함
- 정답 포함 비율 (Hit Rate)
- 측정 방법 : 정제된 지식 안에 gold answer 포함 여부
- 결과
- Rerank > RankCoT > Summary
- Rerank는 관련 문서만 고르기에 정답률이 높고,
- Summary는 요약 과정에서 정답이 누락됨
- RankCoT는 요약 기반임에도 높은 정답 포함률 유지
Length of Knowledge Refinement

- 평균 길이
- 결과
- RankCoT가 가장 짧은 정제 결과 생성 → 프롬프트 토큰 수를 절감하여 효율적
- 결과
- 길이 변화 비율 (training strategy별)
- 분석 : SFT vs DPO
- 결과
- SFT 방식: 출력이 지나치게 짧아지는 경향 → 과적합 신호
- DPO 방식: 더 균형 잡힌 길이 유지, 더 많은 핵심 지식 포함 가능
📍6. Conclusion
- RankCoT는 RAG 시스템에서 검색된 문서의 지식을 더 효과적으로 정제하기 위해 ranking과 summarization의 장점을 결합한 방법
- 실험 결과:
- RankCoT는 외부 지식의 정제에 뛰어난 성능을 보이며,
- LLM이 내부 지식과 외부 지식을 균형 있게 활용할 수 있도록 도와줌
- RankCoT가 생성한 CoT는 질문과의 유사도도 높고, 정답 포함률도 높음
📍7. Limitations
- LLM의 성능에 의존
- DPO 훈련에서 사용되는 좋은/나쁜 CoT 쌍(pair) 생성을 LLM이 직접 수행함
- 따라서 LLM이 충분히 강력하지 않으면 학습 효과가 제한적일 수 있음
- 모델 크기 불일치 시 효과 감소
- RankCoT는 주로 Llama3-8B-Instruct로 구현됨
- RAG 시스템에서 사용하는 생성 모델이 RankCoT보다 훨씬 큰 경우, 이미 강한 내부 지식으로 인해 RankCoT의 정제 효과가 줄어들 수 있음
- 즉, RankCoT와 생성 모델의 파라미터 크기를 맞추는 것이 중요함
💬 8. Takeaway
후... 엄청 어렵진 않은 내용인데 논문이 길었다... 실험이 많아서 그런가...
항상 RAG를 구현할 때면 필수적으로 Reranking을 썼었는데 RankCoT도 한번 써볼까 한다. 그러나 개인적인 생각으로는
얼마나 잘 정제된 CoT를 사용하느냐에 따라 모델의 학습 정도가 갈리게 되고, 결국 RAG의 성능으로 이어지기 때문에 모델과 데이터의 도메인 특성에 따라 기대한 만큼의 성능이 나오지 않을 수도 있을 것 같다.... 아 그리고 DPO 학습법 논문도 제대로 얼렁 읽어야지,,,,
두서없이 이해한 대로 적어봤습니다,,, 읽어주셔서 감사합니다 😎🥹