

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- RAG
- COT
- Do it
- moe
- odds
- Noise Robustness
- coding test
- lora
- Parametric RAG
- Hallucination
- Noise
- Embedding
- Document Augmentation
- DyPRAG
- fine-tuning
- DPO
- GPT
- Statistics
- Algorithm
- Retriever
- retrieval
- LLM
- Transformer
- qwen
- Python
- SFT
- NLP
- reranking
- 파인튜닝
- Baekjoon
Archives
- Today
- Total
왕구아니다
[논문 리뷰] RAFT : Adapting Language Model to Domain Specific RAG 본문
Paper Review/RAG
[논문 리뷰] RAFT : Adapting Language Model to Domain Specific RAG
Psalms 12:6-7 2025. 5. 20. 01:37본 논문 리뷰는 저의 개인적인 해석과 의견을 바탕으로 작성된 글입니다.
내용 중 해석의 오류나 개념적인 착오가 있다면, 망설이지 마시고 댓글로 혼내주시면 감사하겠습니다~
Preview
- RAFT는 "Open-book" 도메인 설정에서 질문과 관련 없는 문서는 무시하도록 모델을 학습시켜 답변의 성능을 높이는 학습법
- 전체 질문 데이터에서 P%는 golden 문서 + distractor 문서, (1-p)%는 distractor 문서로만 구성
- 답변은 CoT 형식으로 구성하고 질문에 대한 명확한 근거를"##begin_quote## and ##end_quote##" 사이에 넣어줌
Link
- 논문 : https://arxiv.org/abs/2403.10131
- 블로그 : https://gorilla.cs.berkeley.edu/blogs/9_raft.html
- 코드 : https://github.com/ShishirPatil/gorilla
GitHub - ShishirPatil/gorilla: Gorilla: Training and Evaluating LLMs for Function Calls (Tool Calls)
Gorilla: Training and Evaluating LLMs for Function Calls (Tool Calls) - ShishirPatil/gorilla
github.com
자 드가보자 😁😎
📍0. Abstract
- 지금까지 downstream한 application에 LLM을 사용하기 위해서 fine-tuning과 RAG 기법을 사용함
- 그러나 무엇이 최적의 방법인지는 open question으로 남아 있는 상태
- 본 논문에서 특정 도메인에서 ‘open-book’을 바탕으로 한 질문에 잘 대답하는 모델의 능력을 향상시키는 Retrieval Augmented Fine Tuning(RAFT)를 제안
- RAFT의 학습 과정은, 질문과 검색된 문서들을 주고 모델이 대답에 필요없는 문서를 무시하게 학습함
- 모델이 질문에 적합한 대답을 생성할 때 관련 있는 문서에서 알맞은 sequence를 문자 그대로 인용함으로써 RAFT를 수행
📍1. Introduction

- 기존 LLM은 방대한 양의 공개 데이터로 학습했기 때문에 일반적인 지식 추론 작업에서는 상당한 성능을 발휘함
- 그러나 요즘 LLM은 특정한 도메인에 많이 활용되고 있으며 이때 일반적인 지식 추론보다는 주어진 문서를 바탕으로 정확하게 답변을 생성해내는 정확도가 중요해지고 있음
- 이 논문의 시발점이 된 질문
- 특정 도메인에 특화된 RAG를 위해, 사전학습된 LLM을 어떻게 활용할 수 있을까?
- 특정 도메인에 특화된 LLM을 적용하는 두 가지 방법론
- RAG = Open-Book Exam
- 고정된 도메인 설정과 테스트할 문서(test documents)에 대한 초기 접근으로 제공되는 학습 기회를 활용하지 못함( = 훈련 과정에서 모델이 해당 도메인에 더 깊이 적용하고(adapt), 학습 기회를 최대한 활용하는 것에 제한적일 수 있음)
- Supervised Fine-Tuning = Close-Book Exam
- 문서의 더 일반적인 패턴을 학습하고 최종 작업 및 사용자 선호도에 더 잘 맞추는 기회를 제공하지만,
- 시험 시간(test time)에 문서를 활용하지 못하거나 훈련 중 검색 과정의 불완전성을 고려하지 못함
- RAG = Open-Book Exam
- RAFT = instruction fine-tuning + RAG
- 목표 : fine-tuning을 통해 model이 domain-specific 한 지식만 학습할 뿐만 아니라 검색된 distracting 한 정보들로부터 강건함을 보장
📍2. LLMs for Open-Book Exam

[Closed-Book Exam]
- 이미 학습된 데이터를 바탕으로 모델이 답변 생성
[Open-Book Exam]
- 외부 소스(website or book chapter)를 바탕으로 답변
- k개의 문서를 검색하고 사용자의 프롬프트와 더함
- 검색한 문서로부터 domain-specific한 정보를 얻음
- retriever 성능에 LLM 퍼포먼스가 달려있음
[Domain-Specific Open-Book Exam]
- LLM이 테스트될 도메인을 사전에 알고 있고, 특정 도메인 내 정보를 활용하여 질문에 답변
- 이 논문에서는 아래 내용들을 연구
- domain-specific open book setting
- 어떻게 사전 학습된 LLM을 적용시킬 것인지
- 어떻게 모델을 검색된 다양한 문서(관련 O, 관련 X)에 강건하게 만들 것인지
📍3. RAFT
[Supervised Finetuning]

- 기존 LLM에 SFT 후 RAG에 적용 과정 : 먼저 QA 데이터 준비 → 학습 → RAG에 적용
[RAFT]

- 데이터 준비
- 질문(Q)
- 관련 문서들(Dk)
- chain-of-though style answer(A*)
- 환각을 방지하기 위해 답변에서 **##begin_quote##**와 **##end_quote##**를 사용하여 context에서 직접 복사한 인용구의 시작과 끝을 나타냄
- 문서를 준비할 때 두 가지로 준비함
- golden(D*)→ 질문에 관련 있음 → 하나 이상의 문서 준비
- distractor(Di) → 관련 없음
- 데이터 중 P% 질문에는 golden document와 distractor document를 섞어서 보여주면서 답변을 생성하게 학습
- 나머지 1-P% 데이터에는 distractor document만 포함시킴
- 학습 quality를 향상시킬 수 있는 주요 원인은 reasoning process에 있음. CoT 방식처럼

📍4. Evaluation
- 본 논문에서 사용한 데이터셋과 베이스라인 그리고 결과
[Datasets]
- Common knowledge based on Wikipedia
- NQ
- Trivia QA
- HotpotQA
- API
- HuggingFace
- Torch Hub
- TensorFlow Hub
- Medical
- PubMed QA
[Baselines]
- LlaMA2-7B-chat model with 0-shot prompting
- 일반적인 instruction-tuning된 QA용 모델
- 명확한 질문에는 답하지만 참고 문서 없이 작동
- LlaMA2-7B-chat model with RAG (Llama2 + RAG)
- 위 모델과 동일하지만, 참고 문서 포함
- 도메인 특화 QA에서 자주 사용되는 방법
- Domain-Specific Finetuning with 0-shot prompting (DSF)
- 특정 도메인에 대해 지도학습 방식으로 파인튜닝
- 문서는 사용하지 않음
- 모델의 답변 스타일을 도메인에 맞게 조정하거나, 문맥에 익숙해지게 하는 데 유용
- Domain-Specific Finetuning with RAG (DSF + RAG)
- 도메인 특화로 학습된 모델에 외부 지식(RAG)을 추가
- 모델이 모르는 내용이 나오면 RAG를 통해 문서를 참조할 수 있도록 구성
[Results]
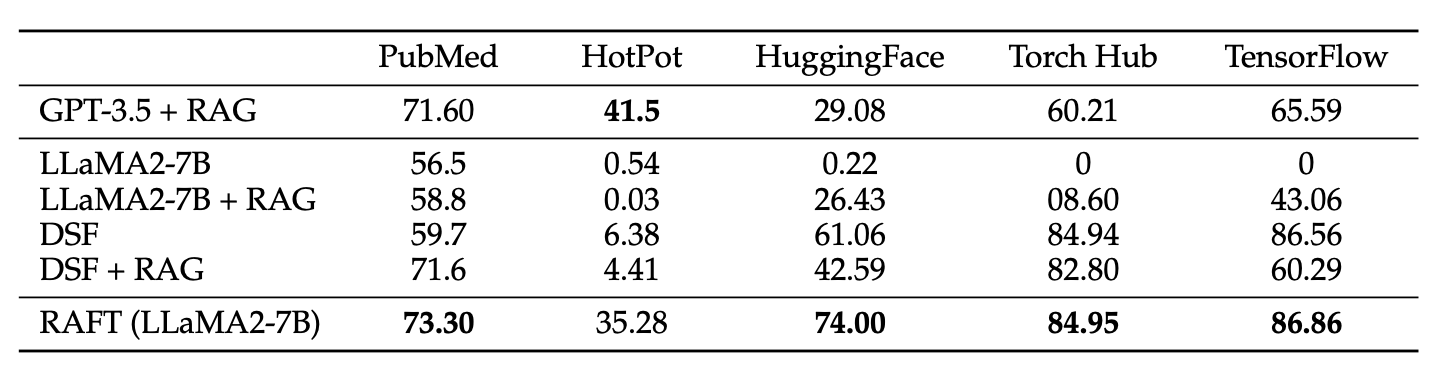
- RAFT는 질문에 대한 답변을 잘할(Fine-Tuning)뿐만 아니라 Document processing capabilities(RAG)를 향상시킴
[Effect of CoT]

- 단지 답변만 제공하는 것은 loss는 줄일 수 있지만 overfiting 발생
- CoT로 답변을 제공하는 것이 모델한테 답변을 하는 가이드를 제공할 뿐만 아니라 모델의 이해도를 향상시킴. 그러다 보니 전반적으로 정확도 올라가고 과적합까지 방지
[Qualitative Analysis]

- 위 예시처럼 단지 QA pairs만 제공하는 것은 제공된 문서에서 관련된 context를 뽑는 능력을 손상시킴
- 결론적으로 training data set에 기본적인 tuning과 문맥 이해도를 반영시키는 것이 중요함(다시 말해 QA set + relevant documents = CoT)
[Should we train the LLM always with the golden context for RAG?]

- 과연 몇 퍼센트의 golden documents를 포함시키는 것(P)이 좋을까?
- 직관적으로 무조건 포함시키는(P=100%) 것이 좋을 것 같지만 그렇지 않음.
- P=80% 일 때 RAG tasks에서 성능 향상
- 논문에서는 training/test에서 4개의 distractor documents를 포함시킴
- 결론적으로 질문과 관련 있는 문서만 주지 말고 관련 없는 문서도 섞어서 주자
📍5. RAFT Generalizes to Top-K RAG
- Top-k RAG를 통해 평가를 진행할 때 RAFT에 몇 개의 distractor documents를 포함시켜 학습을 해야 할까?
- LLM은 irrelevant text에 취약하다는 연구 결과가 있음
- 위 이슈는 top-k RAG에서 LLM+RAG를 활용할 때 치명적임(top-K의 문서를 가져올 때 관련 없는 문서도 있기 때문)

📍6. Conclusion
- RAFT는 특정 도메인 내에서 질문에 답하는 모델의 성능을 ‘오픈북(Open-book)’ 환경에서 향상시키기 위해 고안된 학습 전략
- RAFT 설계에서 몇 가지 핵심적인 결정 사항을 강조
- 혼란을 주는(distractor) 문서들과 함께 모델을 학습시키는 것
- 데이터셋의 일부는 정답(golden) 문서가 문맥에 포함되지 않도록 구성하는 것
- 관련 문장에서 직접 인용하며 Chain-of-Thought 방식으로 답변을 구성하는 것
💬 7. Takeaway
이 논문은 인턴 생활 중 사내 챗봇 개발 업무를 수행하면서, 질문과 무관한 문서가 검색되었을 때 LLM의 판단력을 어떻게 향상시킬 수 있을까 고민하던 중 발견하게 되었다. 사실 RAG 파이프라인에서 이미 상용화된 LLM API를 사용할 경우, 질문과 관련 없는 문서를 어느 정도 스스로 걸러내는 능력은 갖추고 있다. 하지만 그 정확도가 100%는 아니기 때문에, 이에 대한 보완 방법이 필요하다고 느끼고 있었다. 이 논문을 읽으며 이런 방식도 가능하겠구나라는 인사이트를 얻었고, 특히 Synthetic Data와 결합해 현재 인턴십에서 진행 중인 작업에 적용해 볼 수 있는 가능성이 있다는 점에서 흥미롭게 읽었다.
'Paper Review > RAG' 카테고리의 다른 글
'Paper Review/RAG' Related Articles
more



