

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Baekjoon
- DPO
- COT
- RAG
- Python
- Noise Robustness
- fine-tuning
- GPT
- retrieval
- Statistics
- Embedding
- Transformer
- NLP
- LLM
- Algorithm
- Parametric RAG
- moe
- reranking
- coding test
- Do it
- SFT
- Noise
- odds
- qwen
- lora
- 파인튜닝
- Document Augmentation
- DyPRAG
- Hallucination
- Retriever
Archives
- Today
- Total
왕구아니다
[논문 리뷰] LoRA: Low-Rank Adaptation of Large Language Models 본문
Paper Review/NLP
[논문 리뷰] LoRA: Low-Rank Adaptation of Large Language Models
Psalms 12:6-7 2025. 8. 17. 16:30본 논문 리뷰는 저의 개인적인 해석과 의견을 바탕으로 작성된 글입니다.
내용 중 해석의 오류나 개념적인 착오가 있다면, 망설이지 마시고 댓글로 혼내주시면 감사하겠습니다~
Preview
- 이 논문은 대규모 언어 모델을 효율적으로 미세 조정하는 새로운 방법인 LoRA(Low-Rank Adaptation)를 제안
- 기존의 full fine-tuning은 엄청난 GPU 메모리와 시간이 필요했지만, LoRA는 가중치 행렬을 저차원 행렬 곱으로 분해해 소수의 파라미터만 학습한다는 아이디어로 이 문제를 해결
- 이를 통해 메모리 사용량을 획기적으로 줄이면서도 성능 저하 없이 모델을 효율적으로 재적응(fine-tuning)할 수 있음을 보여줌
Link
- 논문 : https://arxiv.org/abs/2106.09685
- 코드 : https://github.com/microsoft/LoRA
GitHub - microsoft/LoRA: Code for loralib, an implementation of "LoRA: Low-Rank Adaptation of Large Language Models"
Code for loralib, an implementation of "LoRA: Low-Rank Adaptation of Large Language Models" - microsoft/LoRA
github.com
📍0. Abstract
- 본 논문 이전에 기본적으로 특정 작업이나 도메인에 특화된 모델을 만들기 위해서는 대용량의 범용성 있는 데이터로 사전 학습(Pretrain)을 시키고 사용자가 원하는 작업이나 도메인에 맞게 적응시키는 것(Fine-tuning)이 NLP의 주요 패러다임 중 하나였음
- 그러나 모델이 커질수록 모든 파라미터 전체를 재학습시키는 것은 실용성이 떨어짐
- 예) GPT-3 175B 모델을 튜닝한다고 했을 때, 1,750억 개의 파라미터를 재학습시키는 것은 매우 고비용적이고 효율성이 떨어짐
- 그렇다면 LLM도 CNN 모델 처럼 마지막 레이어만 학습을 시키는 부분 재학습 방법을 적용하면 되지 않을까? 왜 전체 파라미터를 학습시켜야 하는가?
- 위 질문은 그냥 논문 첫 부분을 읽으면서 든 생각이다..근데 모델 아키텍처를 생각해 보니 Transformer는 CNN과 달리 각 레이어가 self-attention을 통해 전체적으로 연결되어 있어서 마지막 레이어만 튜닝한다고 전체적인 표현 학습이 잘 이루어지지 않을 것 같다..
- 그리고 LLM 같은 언어모델의 경우 하위 레이어에서는 문법적/구조적 정보를 학습하고 상위 레이어에서는 의미적/추상적 정보를 학습하는데 하위 레이어는 고정하고 상위 레이어만 학습한다고 했을 때 새로운 도메인의 특수한 문법 구조를 학습할 수 없다는 문제도 존재할 것 같다..(같은 단어라도 상황에 따라 다른 의미로 쓰이는 것이 언어의 특성이기 때문..)
- 따라서 본 논문에서는 사전학습된 가중치를 고정하고, Transformer 구조의 각 계층에 학습 가능한 저랭크 행렬을 삽입하여, 후속 작업에서 학습해야 할 파라미터 수를 크게 줄이는 학습법인 LoRA를 제안함
- 실험결과 기존처럼 Adam을 이용해 GPT-3 175B를 파인튜닝할 때와 비교하면, LoRA는 학습 파라미터 수를 최대 10,000배 줄이고, GPU 메모리 요구량을 3배 줄일 수 있었음
📍1. Introduction
- 기본적으로 많은 자연어 처리(NLP) 분야에서 하나의 대규모 사전학습 언어 모델을 여러 다운스트림 작업에 적응시키는 방식에 의존함
- 위 방식을 수행하기 위해 사전학습된 모델의 모든 파라미터를 업데이트하는 Full Fine-tuning을 시도하거나
- 일부 파라미터만 튜닝시키거나, 외부 모듈을 학습시키는 방법을 시도해왔음
- 그러나 기존 기법들은 종종 모델의 깊이를 늘려 추론 지연을 유발하거나, 사용할 수 있는 시퀀스 길이를 줄이는 문제가 있었고
- 특히 일부 파라미터만 튜닝할 경우에 Full 파인튜닝의 성능을 따라가지 못해, 효율성과 품질 간의 트레이드오프 문제가 발생했음

- 따라서 본 논문을 쓴 저자들은 "과적합된 모델이 실제로는 낮은 고유 차원(low intrinsic dimension)에 존재한다"에서 영감을 받아 LoRA 학습법을 제안함
- 즉, 위 문장이 LoRA의 핵심 아이디어라고 할 수 있음
위 문장은 직독직해를 한 문장이기 때문에 풀어서 설명을 해보겠습니다.
결론적으로 LoRA는 기존 사전학습된 파라미터는 고정한 채 낮은 차원의 가중치 metrcis만 학습하는 방법론입니다.
그렇다면 이 아이디어는 어디서 시작했을까?를 살펴보면 저자들은 "과적합된 모델이 실제로는 낮은 고유 차원(low intrinsic dimension)에 존재한다"에서 시작했다고 합니다. 대체 무슨 말인가....
먼저 "과적합된 모델"이란 "파라미터 수가 데이터 수보다 훨씬 많은 모델" (예: GPT-3처럼 1,750억 개의 파라미터를 가진 모델)이라고 할 수 있습니다.
그리고 "낮은 고유 차원"이란 "모델이 실제로 학습에 필요한 정보의 차원은 매우 낮다"라고 표현할 수 있습니다. 다시 말해, "1,000차원 공간에 있는 데이터라도, 실제로는 어떤 10차원 평면 위에 거의 다 분포해 있을 수 있다"라는 뜻입니다.
위 두 의미를 합쳐보면 "겉보기엔 파라미터가 엄청 많아도, 실제 학습에 기여하는 ‘정보 변화 방향’은 몇 가지 핵심 축(방향)에 집중되어 있다"라고 해석할 수 있을 것 같습니다. 그리고 논문에서 Li et al. (2018), Aghajanyan et al. (2020) 등의 연구를 인용한 것으로 보아 좀 더 구체적으로 이해해보고 싶으시다면 관련 논문들을 찾아보시기 바랍니다.
암튼, 결국 LLM 전체를 다 학습시킬 필요 없이, ‘저차원 방향’만 잘 조정하면 좋은 성능을 낼 수 있다는 뜻이고 우리가 원하는 특정 작업(A → B 변환)을 수행하기 위해 실제로 바꿔야 하는 건 그중 극히 일부 방향일 수 있다는 뜻입니다.
위 아이디어를 바탕으로 LoRA를 살펴보면, “어차피 모델 변화는 저차원 공간에서 일어나니까, 전체 가중치를 바꾸지 말고 저랭크 행렬(B × A)로 변화만 표현하자!”가 될 것 같습니다. 그래서 Figure1처럼 기존 가중치는 고정(freeze)하고, 변화는 작고 얇은 저랭크 행렬들만 학습하는 구조가 나오게 된 겁니다.
간단히 식으로 살펴보면,
1) 기존 Full Fine-Tuning의 경우 아래와 같이 나타낼 수 있고
# 원래 가중치 (고정됨)
W = [12288 × 12288] # 1.5억 개 파라미터
# 파인튜닝 시 전체를 업데이트
# ΔW도 12288 × 12288
W_new = W + ΔW
2) LoRA 방식의 경우는 아래와 같이 나타낼 수 있습니다.
# 원래 가중치 (고정됨)
W = [12288 × 12288] # 변경 안 함!
# 작은 행렬 두 개만 학습
# r = 4
B = [12288 × 4] # 49,152 파라미터
A = [4 × 12288] # 49,152 파라미터
# 총: 98,304 파라미터 (원래의 0.065%!)
# 실제 계산
output = W(x) + B(A(x))
또한 LoRA를 적용할 때 설정하는 중요한 하이퍼파라미터 r은 저랭크 차원 수로, 이는 전체 파라미터 공간 중에서 학습에 필요한 핵심 변화 방향의 수를 뜻합니다. 일반적으로 이 값은 매우 작게 설정되며, 모델의 압축 효율성과 성능 간의 균형을 조절하는 중요한 요소입니다.
- LoRA의 장점은 다음과 같음
- 테스크 전환 용이 : LoRA는 공유된 하나의 거대한 사전 학습 모델을 바탕으로, 작업별로 작고 가벼운 LoRA 모듈(A, B)만 바꿔 끼우면 되기 때문에, 저장 공간을 아끼고 빠르게 태스크 전환도 가능하게 해 줌
- 하드웨어 절약 : LoRA는 전체 모델 파라미터가 아닌, 아주 작은 저랭크 행렬(A와 B)만 학습하므로, 대부분의 파라미터에 대한 기울기 계산과 옵티마이저 상태 저장이 필요 없음. 덕분에 훈련 시 GPU 메모리 사용량이 크게 줄고, 적응형 옵티마이저(예: Adam)를 사용할 때도 훈련이 훨씬 더 빠르고 가볍게 진행됨. 실제로는 동일한 모델을 학습하는 데 필요한 하드웨어 자원을 최대 3분의 1까지 줄일 수 있음
- 선형구조 : LoRA는 모든 연산을 선형(linear) 구조로 설계했기 때문에, 학습이 끝난 뒤에는 새롭게 학습한 저랭크 행렬들을 기존 가중치에 미리 병합(merge) 해둘 수 있음. 이렇게 하면 모델을 배포할 때 기존처럼 단순한 행렬곱만으로 추론이 가능하므로, 추론 속도나 구조에 전혀 영향을 주지 않음. Full Fine-Tuning과 비교했을 때, 추론 latency가 없음
- 유연성 : LoRA는 기존 파인튜닝 기법들과 충돌하지 않고 함께 사용할 수 있다는 점에서 매우 유연함. 예를 들어, 입력에 특수 토큰을 추가하는 Prefix-Tuning과도 병렬 적용이 가능함
## 3번 선형 구조 장점에 대한 간단한 예시
# 기존 가중치 -> W_q: (12288 x 12288)
# LoRA에서 trainable metrics -> A: (4 x 12288), B: (12288 x 4)
# LoRA가 학습한 BA (기존 가중치는 freeze하고 trainable metrics만 학습:
delta_W = B @ A # (12288 x 12288)
# 기존 weight에 병합
W_q_prime = W_q + delta_W
# 추론 시
q = W_q_prime @ x # 기존과 동일한 한 번의 연산
## 즉, 선형 구조이기 때문에 학습이 끝난 후에는 기존 가중치에 LoRA의 변화량을 사전에 병합해 둘 수 있고,
## 추론 시에는 기존과 똑같이 한 번의 행렬곱만으로 결과를 계산할 수 있습니다.- 용어 및 기본 설정
- d_model : Transformer 계층의 입력 및 출력 차원 크기
- Wq : self-attention 모듈에서 쿼리
- Wk : self-attention 모듈에서 키
- Wv : self-attention 모듈에서 벨류
- Wo : self-attention 모듈에서 출력
- W 또는 W₀ (위 Wo와 다름) : 사전학습된(weight) 가중치 행렬
- ΔW : adaptation 과정 (사전학습(pretrained)된 모델을 특정 작업(task)이나 도메인(domain)에 맞게 조정(fine-tuning)하는 과정 전체를 의미) 중 누적된 gradient update = LoRA로 새로운 작업에 맞게 adaptation 시키면서 생긴 업데이트 값
- r : LoRA 모듈의 랭크(저랭크 차원 수)
- 모델 최적화에는 Adam 옵티마이저를 사용
- Transformer의 MLP(feedforward) 계층의 차원은 일반적으로 d_ffn = 4 × d_model로 설정
📍2. Problem Statement
- LoRA 학습법은 language model에 국한된 것이 아니지만, language model에 초점을 맞춰 설명할 예정이며 먼저 언어 모델링 문제가 무엇인지, 특히 특정 과제에 맞는 프롬프트(prompt)가 주어졌을 때 조건부 확률을 어떻게 최대화하는지에 대한 간략한 설명하겠음
- 라는 파라미터로 구성된, 사전 학습된 'Autoregressive Language Model' PΦ(y∣x)가 있다고 가정해 보자 (이 모델은 입력 컨텍스트 가 주어졌을 때 출력 를 생성할 확률을 계산함)
- 예를 들어, 이 모델은 트랜스포머 아키텍처를 기반으로 하는 GPT와 같이, 여러 작업을 수행할 수 있는 범용 모델일 수 있음
- 이제 이 사전 학습된 모델을 요약, 기계 독해(MRC), 자연어를 SQL 쿼리로 변환(NL2SQL)하는 것과 같은 특정 '조건부 텍스트 생성' 과제(downstream task)에 적용(adaptation)하는 상황을 생각해 보자
- 각각의 특정 과제는 컨텍스트()와 타겟() 쌍으로 이루어진 학습 데이터셋 Z={(xi,yi)} / i=1,..,N로 표현되며, 여기서 와 는 모두 토큰(단어 또는 하위 단어)의 시퀀스를 의미
- 예를 들어, NL2SQL 과제에서는 가 자연어 질문이고 는 그에 해당하는 SQL 명령어이고, 요약 과제에서는 가 기사 본문이고 는 그 요약문임
- 만약 이 사전학습된 모델(PΦ(y∣x))을 Full Fine-tuning 한다고 생각해보자
- 모델의 가중치를 사전 학습된 가중치인 로 시작하여, 조건부 언어 모델링 목표 함수(아래 수식)를 최대화하기 위해 그래디언트(gradient)를 따라 반복적으로 업데이트하여 최종적으로 상태로 만듦

- 그런데 여기서 Full Fine-tuning의 단점이 한가지 존재
- 각각의 새로운 과제마다 기존 모델의 전체 파라미터()와 동일한 크기()를 갖는 파라미터 변화량()을 새로 학습해야 한다는 점
- 따라서 GPT-3처럼 사전 학습된 모델의 크기가 매우 크다면(약 1,750억 개의 파라미터), 각 과제별로 파인튜닝된 모델의 독립적인 인스턴스를 모두 저장하고 배포하는 것은 현실적으로 매우 어렵거나 불가능할 수 있음
- 위 단점을 개선하기 위해 본 논문에서는 특정 과제를 위해 필요한 파라미터의 변화량()을, 원본 모델의 파라미터()보다 훨씬() 작은 크기의 새로운 파라미터 집합 로 표현(encoding)하는 것인 '파라미터 효율적인(parameter-efficient)' 접근법을 채택함
- 결과적으로, 거대한 를 직접 찾는 대신, 훨씬 작은 를 최적화하는 문제로 바뀌게 됨

📍3. Aren't Existing Solutions Good Enough?
- 사실 LoRA 이전에도 다양한 Parameter-Efficient 접근 방식의 연구들이 제안되었음
- 언어 모델링을 예로 들면, 효율적인 적용(adaptation = tuning)을 위한 두 가지 주요 전략이 있음
- 바로 '어댑터 레이어(adapter layers)'를 추가하는 방식과, 입력층의 활성화 값(activations)을 최적화하는 방식
- 하지만 이 두 가지 전략 모두, 특히 대규모 모델을 사용하며 응답 속도(latency)가 매우 중요한 실제 서비스 환경(production scenario)에서는 각자의 한계를 가짐
Adapter Layers Introduce Inference Latency
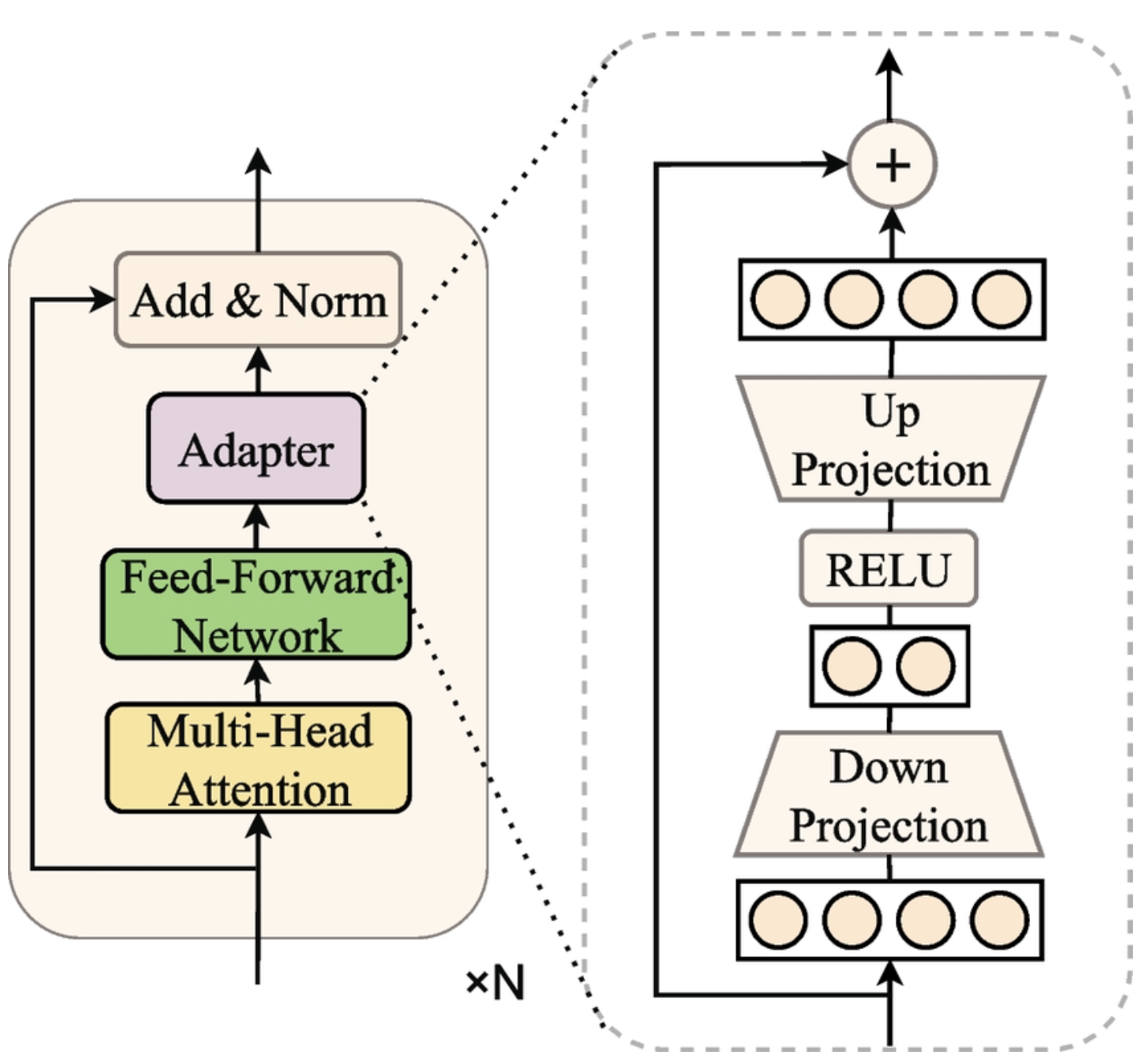
- Adapter Layer는 위 그림처럼 LLM의 본체 가중치(Φ)는 동결하고, 블록 안에 아주 작은 잔차 모듈만 추가해 그 모듈 파라미터만 학습하는 방법. 쉽게 말해, 큰 네트워크를 건드리지 않고 저차원 병목(r)을 통해 필요한 변화만 학습함
입력 → [원래 LLM 레이어 (동결)] → Adapter Module → 출력
↓
[차원 축소 (d→r)]
↓
[비선형 변환]
↓
[차원 확대 (r→d)]
예를 들어, 768차원 → 16차원 → 768차원으로 압축했다 복원하는 과정에서 task-specific한 지식을 학습함- 계산량(FLOPs)만 봤을 때는 Full Fine-tuning에 비해 '차원 축소'와 '차원 확대'라는 두 단계의 병목 구조에 맞춰서만 계산이 이뤄지기 때문에 현지 적음
- 그러나 본 논문 저자들은 계산량에 집중하지 않고 모델 추론 과정에서 병목 구조 특성상 발생하는 Latency에 주목함
- 기본적으로 트랜스포머 구조를 가진 LLM은 RNN과 다르게 입력 문장을 병렬로 처리할 수 있다는 장점을 가지고 있음
"나는 학생 입니다" 입력 시:
RNN 방식 (순차 처리):
나는 → 학생 → 입니다 (하나씩 차례로)
Transformer 방식 (병렬 처리):
[나는] [학생] [입니다] (동시에 처리!)
↓ ↓ ↓
K,Q,V K,Q,V K,Q,V → Attention 계산- 그러나 Adapter Layer 구조는 입력 문장을 병렬로 처리한다고 해도 Adapter Layer를 만나는 순간 순차적으로(sequentially) 처리해야 하기 때문에 실시간 서비스(batch size = 1)에서는 응답 속도 저하라는 치명적인 단점을 가지고 있음
병렬 처리 → [Adapter 병목] → 병렬 처리
↑
여기서 순차 처리 발생!- 이 문제는 모델을 여러 GPU에 나누어 올리는 모델 샤딩(sharding) 기술을 사용할 때 더욱 심각해짐
# Model Sharding : 거대한 모델을 여러 GPU에 나눠서 올리는 기술
GPU 1: Layer 1-4
GPU 2: Layer 5-8
GPU 3: Layer 9-12- Adapter로 인해 모델의 깊이가 깊어지면, 여러 GPU 간에 데이터를 동기화(GPU 간 통신 증가)하기 위한 All-Reduce나 Broadcast 같은 작업이 더 많이 필요해지기 때문(이 문제를 피하려면 Adapter 파라미터를 여러 번 중복 저장해야 하는 비효율이 발생함)
- 추가적으로 Adapter 안에는 비선형 함수가 존재하기 때문에 원래 모델 가중치와 사전에 합칠 수 없어, GPU 병렬 처리의 이점을 충분히 활용할 수 없고 추론 latency가 증가함
# 1) 선형 변환 예시
# 기본 성질
f(x + y) = f(x) + f(y) # 덧셈에 대한 분배
f(ax) = a·f(x) # 스칼라 곱에 대한 분배
# 행렬 곱셈 예시
W = [[2, 0], x = [1, y = [2,
[0, 3]] 1] 1]
W(x + y) = W[3, 2] = [6, 6]
Wx + Wy = [2, 3] + [4, 3] = [6, 6] ✓ 같음!
# 2) 비선형 변환 예시
# ReLU 함수: max(0, x)
x = 2, y = -3
# 왼쪽: 먼저 더하고 ReLU 적용
ReLU(x + y) = ReLU(2 + (-3)) = ReLU(-1) = 0
# 오른쪽: 각각 ReLU 적용 후 더하기
ReLU(x) + ReLU(y) = ReLU(2) + ReLU(-3) = 2 + 0 = 2
# 결과: 0 ≠ 2 → 분배 법칙 성립 안 함! ❌
→ 1 ≠ 2 (분배 법칙 성립 안 함!)
# 3) 선형 변환인 LoRA와의 차이점
# 선형 (LoRA): 미리 합치기 가능 ✓
최종 결과 = (W + BA)x = W_merged·x # 한 번의 연산
# 비선형 (Adapter): 미리 합치기 불가 ❌
최종 결과 = W_up·ReLU(W_down·x) + x # 각 단계를 거쳐야 함
↑ 이 부분 때문에 합칠 수 없음
# 비선형 함수는 "먼저 계산하고 합치기"와 "합치고 나서 계산하기"의 결과가 달라서, 반드시 순차적으로 처리해야 함
Directly Optimizing the Prompt is Hard
- 다른 접근법인 Prefix Tuning으로 대표되는 방식은 또 다른 종류의 어려움에 직면함
- Prefix Tuning은 최적화하기가 까다로우며, 학습 가능한 파라미터의 수를 늘린다고 해서 성능이 꾸준히 향상되지도 않음(비단조적 변화)
- 더 근본적인 문제는, 모델 적응(adaptation)을 위해 입력 시퀀스 길이의 일부를 학습 가능한 프롬프트에 할당하게 되면, 필연적으로 실제 과제(downstream task)를 처리하는 데 사용할 수 있는 시퀀스 길이가 줄어든다는 점
# 일반적인 입력
입력: "Translate to Korean: Hello world"
# Prefix Tuning
입력: [P1][P2][P3][P4][P5] "Translate to Korean: Hello world"
↑________________↑
학습 가능한 prefix 토큰들 (가상의 프롬프트)
# Transformer의 각 레이어에서 각 레이어마다 prefix에 해당하는 key, value 벡터를 학습
- Layer 1: P_k1, P_v1
- Layer 2: P_k2, P_v2
- ...
- Layer 12: P_k12, P_v12
# Attention 계산 시
Attention(Q, [P_k; K], [P_v; V])
↑ ↑
prefix를 앞에 concatenate📍4. Our Method
4.1 Low-Rank-Parametrized Udate Matrices
- 신경망(Neural Network)은 행렬 곱셈을 수행하는 많은 밀집층(dense layer)을 포함하고 있음. 이러한 층들의 가중치 행렬은 일반적으로 full-rank
- Aghajanyan et al. (2020) 연구는 특정 과제에 적응할 때, 사전 훈련된 언어 모델들은 낮은 "고유 차원(intrinsic dimension)"을 가지며 더 작은 부분 공간으로 무작위 투영됨에도 불구하고 여전히 효율적으로 학습할 수 있음을 이 보여줌
- 이에서 영감을 받아, 저자들은 가중치에 대한 업데이트 역시 적응(튜닝) 과정에서 낮은 "고유 랭크(intrinsic rank)"를 가질 것이라고 가정함
- 따라서 저자들은 사전 훈련된 가중치 행렬 (W_0 ∈Rd×k)에 대해, 업데이트를 저차원 분해 (low-rank decomposition) W_0+ΔW = W_0+BA로 표현하여 제약을 가함. 여기서 B ∈Rd×r, A∈Rr×k, (rank)r ≪min(d,k)
- 훈련 동안 W_0는 동결(freeze)되어 그래디언트 업데이트를 받지 않는 반면, A와 B는 훈련 가능한 파라미터를 포함함
- W_0와 는 모두 동일한 입력과 곱해지며, 각각의 출력 벡터는 좌표별로 합산됨
- 입력 데이터가 원래의 가중치(W_0)를 통과해서 결과를 냄
- 동시에, 입력 데이터가 작은 LoRA 모듈(A와 B)을 통과해서 '수정용 결과'를 냄
- 마지막에 이 두 결과를 그냥 더해줌
- 에 대해, 저자가 수정한 순전파(forward pass)는
- 그리고 α/r로 스케일링을 적용하여 다양한 랭크 값(r)에 대해 일관된 학습을 진행
A Generalization of Full Fine-tuning
- 이 부분에서 저자들이 LoRA가 어떻게 기존의 full fine-tuning을 포괄할 수 있는 일반적인 방식인지 설명함
- 파인튜닝의 일반화된 형태는, 사전학습된 파라미터 중 일부만을 훈련하도록 허용하는 방식
- LoRA는 한 걸음 더 나아가, 적응(adaptation) 과정에서 가중치 행렬의 누적 gradient 업데이트가 full-rank일 필요없음. 다시 말해, 변화량 ΔWx가 꼭 원래 행렬과 동일한 차원(rank)을 가질 필요가 없다는 것
- 이는 LoRA를 모든 가중치 행렬에 적용하고 bias까지 모두 학습시킨다면, LoRA의 랭크 r를 사전학습된 가중치 행렬의 랭크와 동일하게 설정할 경우 full fine-tuning과 유사한 표현력을 회복할 수 있다는 것을 의미함. 즉, r = rank(W_0)이면 LoRA는 사실상 full fine-tuning과 동일한 학습 범위
- 다시 말해, 학습 가능한 파라미터의 수를 늘려가면, LoRA 학습은 결국 원래 모델 전체를 학습하는 방식으로 수렴하게 됨
- 반면, 어댑터(adapter) 기반 방법은 단순한 MLP 구조로 수렴하고, pre-fix 기반 방법은 긴 입력 시퀀스를 처리할 수 없는 모델로 수렴하게됨
No Additional Inference Latency
- 이 부분에서는 LoRA가 추론 시 지연(latency)을 전혀 증가시키지 않는다는 점을 설명함
- LoRA를 실제 운영 환경에 배포할 때는, 미리 W = W_0 + BA를 계산해서 저장해두고, 일반적인 방식으로 추론을 수행할 수 있음. 즉, 학습 시에는 원래 가중치 W_0에 LoRA의 변화량 BA를 더해 새로운 가중치로 만들고, 추론 시에는 이 합쳐진 가중치 W만 사용하기 때문에, 모델이 LoRA를 사용했는지 여부는 추론 시점에서는 전혀 차이가 없음. 참고로 W_0와 BA 모두 Rd×k의 동일한 차원
- 그리고 다른 태스크로 전환해야 할 경우, BA를 빼고 다른 태스크의 B’A’를 더하는 방식으로 빠르게 전환할 수 있으며, 이 연산은 메모리 부담이 거의 없음(모델 전체를 교체하지 않고, LoRA 모듈만 교체하면 됨)
4.2 Applying LoRA To Transformer
- 원칙적으로는, LoRA는 신경망 내의 어떤 가중치 행렬에도 적용 가능하며, 이를 통해 학습해야 하는 파라미터 수를 줄일 수 있음
- Transformer에서 각 레이어는 self-attention과 feedforward(MLP)로 구성되어 있기 때문에 Transformer 구조에서는, self-attention 모듈에 4개의 가중치 행렬 (W_q, W_k, W_v, W_o)가 있고, MLP 모듈에도 2개가 존재함
- 출력 차원이 보통 여러 개의 attention head로 나뉘어 있어도, W_q, W_k, W_v는 각각 d(model) X d(model)크기의 단일 행렬로 간주함
- 본 논문에서는 간단함과 파라미터 효율성 측면에서, downstream task에서는 attention weight만 LoRA로 학습하고, MLP 모듈은 고정(freeze)시킴
Practical Benefits and Limitations
- LoRA는 파라미터를 덜 학습하므로 가장 큰 잠점은 VRAM과 디스크 용량 절감 효과
- Adam 옵티마이저로 학습할 때, 대부분의 파라미터를 고정(freeze)하므로 optimizer 상태(momentum, variance)를 저장할 필요가 없어 VRAM 사용량이 최대 3분의 2까지 감소할 수 있음
- 예를 들어 GPT-3 175B 모델의 경우, 학습 중 VRAM 사용량을 1.2TB에서 350GB로 줄일 수 있었음
- r = 4이고 query(Wq)와 value(Wv) 가중치만 LoRA로 학습했을 때, 체크포인트 크기는 350GB → 35MB로 약 10,000배 줄어듦
- 또 다른 장점은, 배포된 상태에서 전체 파라미터를 바꾸는 것이 아니라 LoRA 가중치만 교체함으로써 여러 태스크를 쉽게 전환할 수 있다는 점
- 이는 미리 VRAM에 사전학습 가중치를 올려놓은 상태에서, LoRA 모듈만 바꿔가며 다양한 맞춤형 모델을 실시간으로 교체할 수 있게 해줌
- 또한 GPT-3 175B 모델을 학습할 때, 대부분의 파라미터에 대해 gradient를 계산하지 않기 때문에 전체 파인튜닝보다 학습 속도가 25% 빨라짐
- 한계점으로는, LoRA는 태스크마다 다른 모듈을 사용하기 때문에 서로 다른 A, B를 사용하는 여러 태스크의 입력을 한 번의 forward pass로 배치 처리하기는 어려움 (특히, 추론 지연을 없애기 위해 A, B를 미리 W에 합쳐놓은 경우라면 더욱 그렇다고 함)
- 하지만 latency(지연)가 크게 중요하지 않은 상황에서는, W_0와 LoRA 모듈을 합치지 않고 각 샘플마다 동적으로 다른 LoRA 모듈을 적용하는 방식도 가능함
📍5. Empirical Experiments
- 저자들은 LoRA를 RoBERTa, DeBERTa, GPT-2에서 평가한 뒤, GPT-3 175B로 확장해 실험함
- 실험은 자연어 이해(NLU)부터 자연어 생성(NLG)에 이르기까지 다양한 task를 포함
- 특히 RoBERTa와 DeBERTa는 GLUE 벤치마크로 성능을 측정
- GPT-2에서는 Li & Liang (2021)의 실험 설정을 그대로 따랐고, GPT-3에서는 WikiSQL(NL→SQL 변환)과 SAMSum(대화 요약) 데이터를 추가로 사용
- 모든 실험은 NVIDIA Tesla V100 GPU에서 수행
5.1 Baselines
Fine-Tuning(FT)
- 전체 파인튜닝(Fine-Tuning)은 가장 일반적인 적응 방식으로, 사전학습된 가중치와 바이어스로 모델을 초기화한 후, 모든 파라미터를 업데이트함
- 그 변형으로, 일부 레이어만 업데이트하고 나머지는 고정(freeze)하는 방식도 있음
- GPT-2 관련 실험에서는 Li & Liang (2021)이 보고한 “FTTop2”, 즉 마지막 두 개 레이어만 업데이트하는 방식도 비교군으로 포함함
Bias-only or BitFit
- BitFit은 전체 모델에서 bias 항만 학습하고, 나머지 파라미터는 모두 고정하는 매우 간단한 방법
Prefix-embedding tuning (PreEmbed)
- Prefix-embedding tuning은 입력 토큰 사이에 특수 토큰을 삽입하고 이들의 임베딩만 학습하는 방식
- 이 특수 토큰은 학습 가능한 임베딩을 가지며, 보통 원래 모델의 어휘(vocab)에는 없는 토큰. 또한 어디에 배치하느냐에 따라 성능에 영향을 줌
- 저자들은 토큰을 앞(prefix) 또는 중간(infix)에 넣는 방식에 주목함
- l_p, l_i는 각각 prefix와 infix 토큰의 개수를 의미
- 학습 가능한 파라미터 수는 |Θ| = L x d(model) x (l_p+ l_i)
Adapter tuning
- Adapter tuning은 Transformer의 self-attention과 MLP 사이에 작은 어댑터 레이어를 삽입하는 방식
- 하나의 Adapter는 두 개의 fully-connected layer + 비선형 함수 + bias로 구성. 이 기본 구조를 AdapterH라 부름
- 다양한 Adapter 모델들을 비교군으로 넣음
- AdapterL : 은 Lin et al.이 제안한 MLP 이후 + LayerNorm 이후에만 어댑터를 넣는 구조
- AdapterP : Pfeiffer et al.이 제안
- AdapterD : 일부 어댑터 레이어를 생략(drop)하는 방식
- 학습 가능한 파라미터 수는 |Θ| = L_adapter x (2 x d(model) x r + r + d(model)) + 2 x L_LN x d(model)
- L_adapter : adapter layer 수
- L_LN : 학습 가능한 LayerNorm 수
LoRA
- 기존 가중치에 저랭크 행렬 B, A 쌍을 병렬로 추가하여 학습 가능한 구조
- 대부분의 실험에서는 단순화를 위해 Wq, Wv (쿼리/밸류 가중치)에만 LoRA를 적용
- LoRA의 파라미터 수는 랭크 r과 원래 가중치의 크기에 따라 결정됨
- 학습 가능한 파라미터 수는 |Θ| = 2 x L_LoRA x d(model) x r
5.2 RoBERTa BASE / LARGE
- RoBERTa는 BERT에서 제안된 사전학습 방식을 최적화한 모델로, 파라미터 수를 크게 늘리지 않으면서도 성능을 개선한 모델
- HuggingFace Transformers 라이브러리에서 제공하는 RoBERTa-base (125M) 및 RoBERTa-large (355M) 모델을 사용하여, GLUE 벤치마크의 여러 과제들에 대해 LoRA와 다른 적응 방법의 성능을 비교 평가 진행
- 어댑터 방식들과 공정하게 비교하기 위해, LoRA 실험에 두 가지 중요한 설정 변경을 적용
- 첫째, 모든 태스크에 대해 동일한 배치 크기(batch size)와 시퀀스 길이 128을 사용하여 어댑터 기준과 동일하게 설정
- 둘째, MRPC, RTE, STS-B 태스크에 대해서는 사전학습(pretrained)된 모델로 초기화했고, MNLI에 먼저 fine-tune된 모델을 재활용하지 않음
- Houlsby et al.의 제한된 설정을 따른 실험 결과는 † 기호로 표시


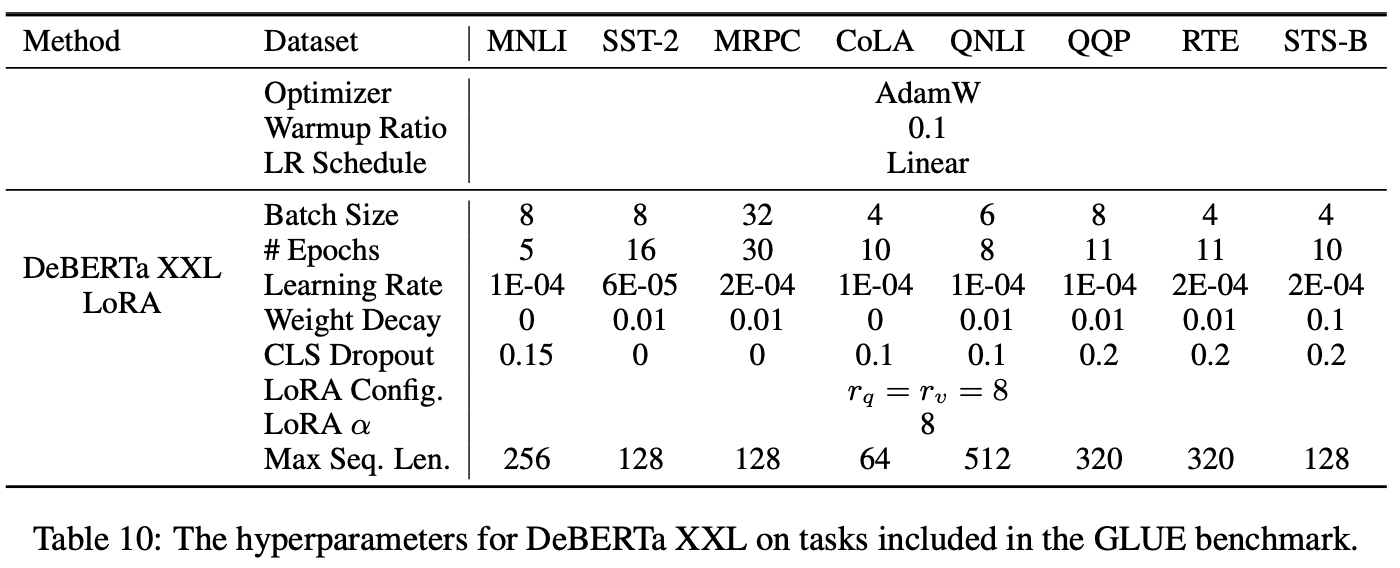
5.3 DeBERTa XXL
- DeBERTa(He 외, 2021)는 BERT의 최근 변형 중 하나로, 훨씬 더 대규모로 학습되었으며 GLUE(Wang 외, 2019) 및 SuperGLUE(Wang 외, 2020)와 같은 벤치마크에서 매우 경쟁력 있는 성능을 보임
- 저자들은 LoRA가 전체 파인튜닝된 DeBERTa XXL(15억 개 파라미터)의 성능과 GLUE 벤치마크에서 여전히 대등한 성능을 낼 수 있는지를 평가 (위 Table 2 참고)
5.4 GPT-2 Medium/Large

- 저자들은 위에서 실험한 것처럼 LoRA가 자연어 이해(NLU) 분야에서 전체 파인튜닝의 경쟁력 있는 대안이 될 수 있음을 보여준 이후, LoRA가 GPT-2 Medium 및 Large(Radford 외) 같은 자연어 생성(NLG) 모델에서도 여전히 효과적인지를 알아보고자 함

5.5 Scaling up to GPT-3 175B

- LoRA의 마지막 테스트로, 파라미터 수가 1,750억 개인 GPT-3 모델로 실험을 확장
- Table 4에서 볼 수 있듯이, LoRA는 세 가지 데이터셋 모두에서 전체 파인튜닝 성능을 동일하거나 능가함


- 그러나 Figure 2에서 볼 수 있듯이, 모든 방법이 학습 가능한 파라미터 수가 많아질수록 성능이 계속 좋아지는 것은 아님
- prefix-embedding tuning에서 256개, prefix-layer tuning에서 32개 이상의 special token을 사용할 경우 성능이 뚜렷하게 하락하는 것을 관찰함 (Table 15 참고)
- 위 현상에 대한 철저한 조사는 본 논문의 범위를 벗어나지만, 저자들은 special token이 많아지면 입력 분포가 사전 학습 시의 분포와 더 멀어지기 때문이라고 추측함 (사전학습된 LLM은 일반적인 자연어 분포를 기준으로 학습되어 있는데, 특수 토큰을 너무 많이 주입하면 분포가 깨져서 일반화 성능이 떨어진다 뜻)

- 추가적으로 데이터가 적은 상황에서의 다양한 적응 방식 성능은 Table 16 참고
📍6. Related Works
Transformer Language Models
- 트랜스포머 모델은 자연어처리(NLP)의 핵심 구조로, 입력과 출력을 연결하는 sequence-to-sequence 아키텍처이며 self-attention 메커니즘을 중심으로 작동함
- 트랜스포머의 디코더를 여러 층 쌓아 autoregressive language modeling함으로써 다양한 NLP 작업에서 최고 성능을 기록하고 사실상 현재까지 표준이 되었음
- 그리고 BERT와 GPT-2의 등장으로 ’사전학습 → 미세조정(fine-tuning)’이라는 새로운 패러다임이 자리잡았음. 먼저 범용 데이터를 대규모로 학습하고, 이후 특정 작업에 맞게 미세조정하는 방식이 기존의 단일 작업 학습보다 훨씬 더 뛰어난 성능을 보여줌
- 트랜스포머 모델의 크기를 키우면 일반적으로 성능이 향상되어 왔고 대표적으로 GPT-3는 무려 1,750억 개의 파라미터를 가진 현재까지(논문 작성 연도 기준) 가장 큰 단일 트랜스포머 언어 모델임
Prompt Engineering and Fine-Tuning
- GPT-3처럼 초거대 모델은 몇 가지 예시만으로도 특정 작업에 적응할 수 있지만, 성능은 입력 문장(prompt)의 구성에 크게 의존함. 즉, ‘어떻게 질문하느냐’가 성능을 좌우함
- 그래서 특정 작업에서 좋은 성능을 끌어내기 위해 프롬프트를 구성하고 포맷팅하는 노하우가 중요해졌고, 이를 'prompt engineering' 혹은 'prompt hacking'이라 부름
- 반면, 파인튜닝은 사전학습된 모델을 특정 작업에 맞게 전체 혹은 일부 파라미터를 다시 학습시키는 방법
Parameter-Efficient Adaptation
- Fine-Tuning의 고비용 문제를 해결하기 위한 방안으로, 기존 신경망 층 사이에 소규모 'adapter layers'를 삽입해 파라미터 수를 줄이는 방식이 제안되었음
- LoRA 또한 비슷한 ‘병목 구조(bottleneck structure)’를 활용하지만, 업데이트를 저랭크(low-rank) 행렬로 제한하는 방식으로 동작함
- Adapter Layers의 방식과 LoRA의 핵심적인 차이점은, LoRA는 학습된 저랭크 파라미터를 추론 시 기존 파라미터에 통합할 수 있기 때문에 별도의 연산 지연이 없다는 점
Low-Rank Structures in Deep Learning
- 딥러닝에서 ‘저랭크 구조’는 흔하게 나타나는 특성 중 하나
- 특히 파라미터가 많은 과적합 상태의 신경망은 학습 후에도 저랭크 특성을 갖는 경향이 있다는 것으로 알려져있음
- 이전에는 처음부터 저랭크 제약을 걸고 학습을 수행한 연구들도 있었지만, 사전학습된 모델을 동결한 상태에서 ‘저랭크 업데이트’만으로 다운스트림 작업에 적응하는 방식은 본 논문이 처음이라고 함
📍7. Understanding the Low-Rank Updates
- 5절에서 LoRA가 실험적으로 뛰어난 성능을 보인 만큼, 이번 절에서는 저랭크(low-rank) 방식이 실제로 어떤 성질을 가지고 학습되는지 더 깊이 들여다보고자 함
7.1 Which Weight Matrices In Transformer Should We Apply LoRA To?
- 만약 파라미터 수에 제한이 있다면, 트랜스포머 구조 중 어떤 가중치 행렬에 LoRA를 적용해야 최고의 성능을 낼 수 있을까?

- 4.2절에서 언급했듯이, 저자들은 Self-Attention 모듈의 가중치에만 LoRA를 적용함
- 전체 파라미터 수가 18MB(FP16인 경우 35MB)을 넘지 않도록 설정. 업데이트하는 파라미터의 용량을 제한하기 위해 한 가지 종류의 가중치 매트릭스를 사용한다면 rank=8로 설정하고, 두 가지 종류의 가중치 매트릭스를 사용한다면 rank=4로 설정함
- 특히 ∆Wq(쿼리)나 ∆Wk(키)에만 LoRA를 적용하면 성능이 크게 떨어졌고, 쿼리(Wq)와 밸류(Wv) 둘 다에 LoRA를 적용했을 때 성능이 가장 뛰어남 (Table 5 참고)
- 이는 ’랭크(r)’가 작더라도 여러 가중치에 고르게 분배하는 것이, 특정 가중치에만 높은 랭크를 쓰는 것보다 효과적이라는 것을 시사함
왜 서로 다른 어텐션 가중치 행렬에 LoRA를 적용했을 때 성능이 다를까?
아마 각각의 어텐션 가중치 행렬의 특성과 의미를 잘 생각하면 이해하기 쉬울 것 같다.
∆Wq : Query 가중치 행렬
- 각 단어가 다른 단어들과 어떤 관계를 맺으려 하는지, 즉 ‘내가 알고 싶은 정보는 무엇인가?’라는 질문을 스스로 생성합니다.
- 문장 속에서 “이 단어는 다른 단어들과 어떤 상호작용을 기대하는가?“를 결정합니다. 예를 들어, “학생이 책을 읽는다”라는 문장에서 “학생”이라는 단어는 “누가 무엇을 하는가?“라는 질문을 던지고, 이에 대한 대상은 “책”이 될 수 있습니다.
- LoRA에서 ∆Wq를 조정하는 것은 모델이 어떤 기준으로 관계를 탐색하는지를 바꾸는 것이므로, 문맥 이해의 방향성을 조절한다고 볼 수 있습니다.
∆Wk : Key 가중치 행렬
- Query가 던진 질문에 대해, 각 단어가 자신이 얼마나 관련이 있는지를 표현하는 키(key) 역할을 합니다.
- 즉, “내가 가진 정보는 너의 질문과 관련이 있어!“라고 주장하는 각 단어의 응답 준비도를 나타냅니다.
- Query와 Key의 내적(dot product)을 통해 어텐션 점수가 계산되며, 이 점수가 높을수록 해당 단어가 중요한 것으로 간주됩니다.
- ∆Wk를 조정하면 ‘어떤 단어를 더 중요하게 볼지’에 대한 기준을 미세하게 조정할 수 있어, 특정 문맥에서 더 민감하게 반응하도록 만들 수 있습니다.
∆Wv : Value 가중치 행렬
- 실제로 그 단어가 문맥 속에서 전달하려는 정보, 즉 실질적인 의미 콘텐츠를 담고 있습니다.
- 앞의 Query와 Key는 ‘누가 누구를 주목할 것인가’를 정했다면, Value는 실제로 주목받은 단어가 전달하는 정보 자체입니다.
- LoRA에서는 ∆Wv 조정이 매우 중요합니다.
- 대부분의 실험에서 Query와 함께 Value만 조정해도 성능 향상이 충분히 가능했습니다.
- 즉, LoRA는 의미 표현(∆Wv)과 관계 탐색 기준(∆Wq)을 미세 조정함으로써, 문맥의 정확한 의미 전달력을 높이는 방식으로 작동합니다.
∆Wo : Output 가중치 행렬
- 어텐션 연산의 결과를 다음 레이어로 전달하는 역할을 합니다. 일종의 결과 요약 및 전달자입니다.
- 여러 단어 간의 상호작용을 통해 계산된 최종 어텐션 값들을 다시 모델이 이해할 수 있는 형태로 정리해서 내보내는 단계입니다.
- ∆Wo를 LoRA로 조정하면, 어텐션 결과를 얼마나 강조하거나 변형해서 다음 층에 보낼지를 조절할 수 있습니다.
- 논문에서는 Wq, Wv만으로도 대부분의 효과를 얻지만, 실험적으로 Wo까지 조정하면 추가적인 성능 향상 여지가 있는 경우도 있음이 밝혀졌습니다.
7.2 What Is The Optimal Rank r For LoRA?
- LoRA에서 사용하는 랭크(r)의 크기가 성능에 어떤 영향을 주는가?
- 비교를 위해 세 가지 설정을 실험
- 1) 쿼리
- 2) 쿼리, 밸류
- 3) 쿼리, 키, 밸류, 출력

- Table 6의 결과에 따르면, 놀랍게도 r=1 같이 아주 작은 랭크만으로도 LoRA는 충분히 좋은 성능을 냄. 특히 Wq와 Wv를 함께 적용했을 때 그 효과가 더 큼
- 이는 업데이트 행렬 ∆W가 실제로는 본질적으로 매우 저랭크일 수 있다는 의미 = 파라미터 수가 아무리 많아도 본질적으로 학습시켜야하는 파라미터 수는 저차원 안에 있다
- 하지만 항상 작은 랭크(r)가 모든 작업이나 데이터셋에서 잘 작동한다고 기대할 수는 없음
- 예를 들어, 사전학습에 사용된 언어와 전혀 다른 언어를 대상으로 하는 task를 생각해보면 이 경우에는, 기존에 학습된 지식과 문맥 구조가 새 언어와 크게 다르기 때문에 모델 전체를 재학습(fine-tuning) 하거나 LoRA에서도 r을 d_model 수준(즉, 최대한 크게) 설정하는 것이 작은 r로만 부분적으로 조정하는 것보다 훨씬 나은 성능을 낼 수 있음
- 이 가설(아주 작은 랭크만으로도 LoRA는 충분히 좋은 성능을 냄)을 더 확인하기 위해, 서로 다른 r 값과 시드(seed)를 사용했을 때 학습된 저차원 공간(subspace)이 얼마나 겹치는지도 분석함
- 결론적으로 실제로 r을 늘린다고 해서 더 의미 있는 공간을 학습하는 것은 아니었음. 즉, 작은 r 만으로도 충분히 중요한 정보를 학습할 수 있음. 아래에서 더 자세히 살펴보자
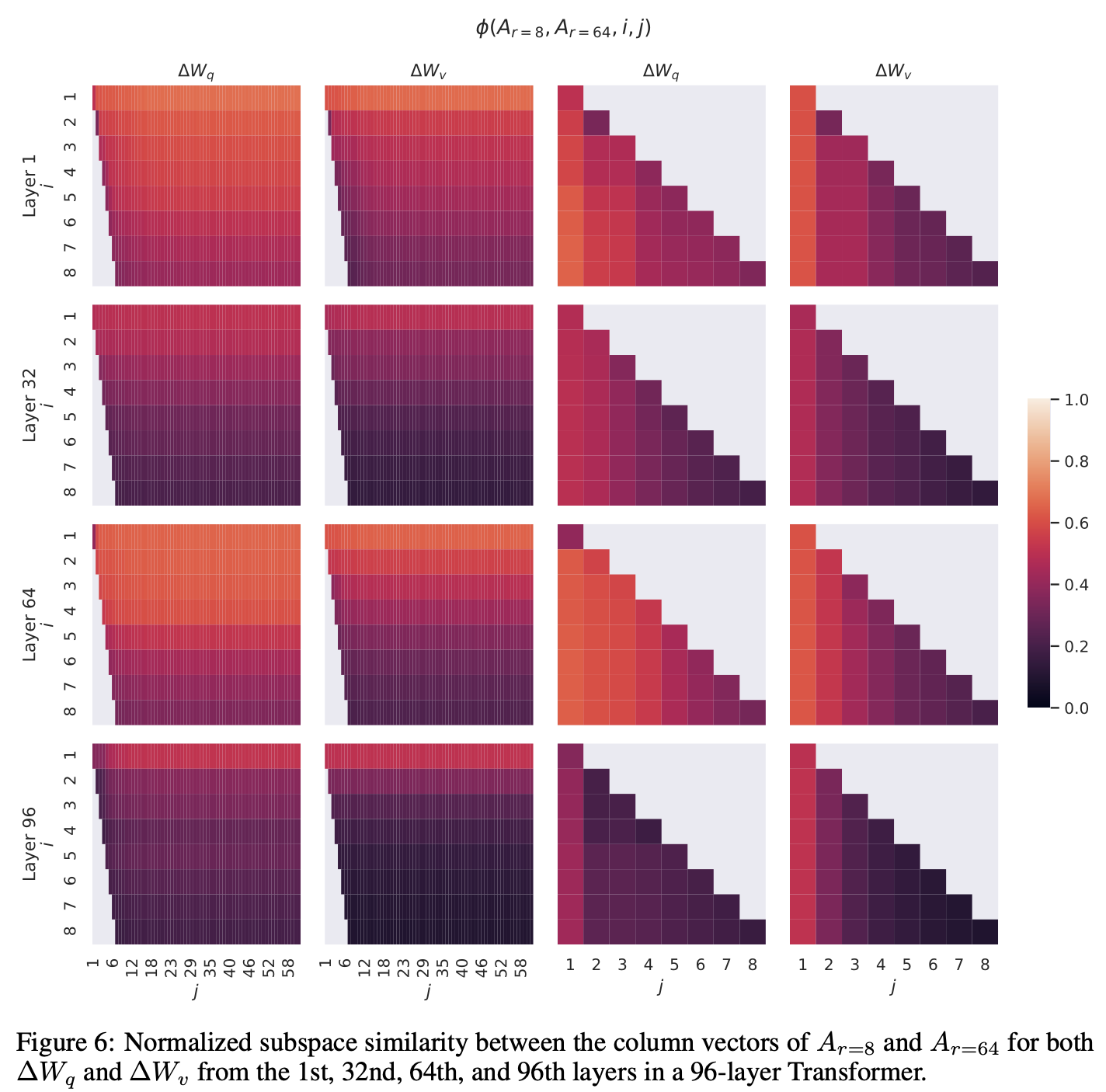
Subspace similarity between different r
- 서로 다른 rank로 학습된 LoRA 행렬이 어떤 공간을 공유하는가
- 같은 사전학습된 모델을 기준으로, 랭크 r = 8과 r = 64로 학습된 LoRA 행렬 Ar를 비교함
- 이 두 행렬에 대해 특이값 분해(SVD)를 수행하여, 각 행렬의 오른쪽 특이벡터 집합(U)을 얻음
- 다음과 같은 질문에 답을 얻기 위해 실험 진행
- r=8에서 얻은 상위 i개의 특이벡터들이 만드는 공간이, r=64에서 얻은 상위 j개의 특이벡터들이 만드는 공간에 얼마나 포함되어 있는가?
- 이 유사도는 Grassmann 거리 기반의 정규화된 부분공간 유사도 φ 로 측정함. 논문에서는 GPT-3의 96개 레이어 중 48번째 층을 분석 대상으로 삼음


- 가장 상위 특이벡터(첫 번째 방향)는 r=8과 r=64 간에 매우 높은 유사도를 보이지만, 그 이외의 방향들은 겹치지 않고 대부분 서로 다름
- 특히, Value 및 Query 가중치에서의 Ar=8과 Ar=64는 1차원 정도의 공통된 부분공간을 공유하며, 유사도 값이 0.5 이상이었음. 이러한 결과는 왜 r=1 같이 매우 작은 랭크로도 꽤 괜찮은 성능이 나오는지 설명해줌
- 이 두 행렬이 같은 사전학습 모델을 기반으로 학습되었다는 점을 감안하면, 공통적으로 학습된 상위 특이벡터 방향들이 가장 의미 있는 정보를 담고 있으며, 나머지 방향들은 훈련 중 우연히 쌓인 잡음(noise)일 가능성이 크다는 것을 시사함
- 따라서, 실제로도 ∆W (업데이트 행렬)는 매우 저랭크로 표현 가능하며, 불필요한 고차원 방향까지 학습할 필요는 없다는 점을 수치적으로 뒷받침함
Subspace similarity between different random seeds
- 같은 r 값에서 랜덤 시드가 다를 때 LoRA가 학습하는 공간은 얼마나 일치하는가?
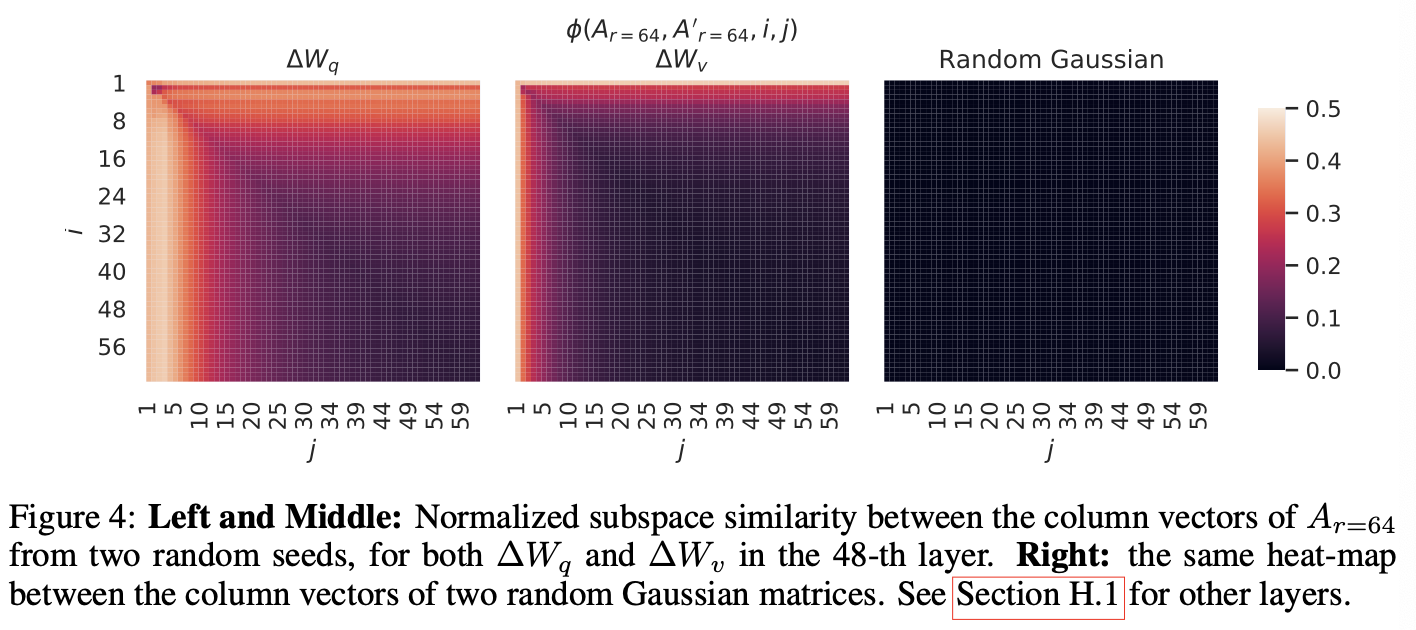
- 동일한 모델과 r=64 설정에서, 다른 랜덤 시드(seed)를 사용한 두 번의 LoRA 학습 결과를 비교함
- 그 결과, Query 가중치(∆Wq)는 Value 가중치(∆Wv)보다 더 많은 공통된 특이벡터 방향을 가지는 것으로 나타남. 이는 Table 6에서 관찰된 바와 같이, ∆Wq가 더 높은 내재적 랭크(intrinsic rank)를 가진다는 실험 결과와도 일치함 = 서로 다른 랜덤 시드로 두 번 학습했는데 Wq에서는 공통된 특이벡터 방향이 발견됬다는 것은 반복적으로 학습되는 정보의 방향이 뚜렷하다는 뜻
- 즉, ∆Wq는 서로 다른 시드에서도 유사한 학습 결과를 반복해서 도출하는 경향이 강하다 뜻
- 비교를 위해 무작위로 생성한 가우시안 행렬 두 개의 유사도도 함께 시각화했는데, 이 경우에는 공통되는 특이벡터 방향이 전혀 나타나지 않았음. 즉, 의미 없는 무작위 행렬들은 서로 완전히 독립된 공간을 형성한다는 것을 보여줌
7.3 How Does The Adaptation Matrix ∆W Compare To W?
- 적응 행렬 ∆W(LoRA BA 행렬)와 원래의 가중치 행렬 W 사이의 관계를 더 깊이 탐구해보자
- 다음 질문에 답하기 위해 실험을 진행
- ∆W는 W와 높은 상관관계를 가지는 걸까?
- 좀 더 수학적으로 말하면, ∆W는 W의 주요 특이값 방향(top singular directions)에 주로 포함되어 있는 걸까?
- 또한, ∆W는 W의 같은 방향 성분과 비교했을 때 얼마나 “크게” 작용하고 있을까?
- 위 질문들에 답하기 위해, 저자들은 ∆W의 r차원 부분공간에 W를 투영하고 이를 위해 UᵀWVᵀ를 계산함. 여기서 U와 V는 각각 ∆W의 왼쪽과 오른쪽 특이벡터 행렬
- 그다음, 투영된 W의 Frobenius norm ‖UᵀWVᵀ‖F와 원래 W의 norm ‖W‖F를 비교
- 비교를 위해, U와 V를 W의 상위 r개의 특이벡터로 바꾸거나 무작위 행렬로 바꾼 경우도 함께 계산

- Table 7을 통해 도출된 결론
- 1) ∆W는 무작위 행렬보다 W와 더 강한 상관관계를 가지고 있으며, 이는 ∆W가 W 안에 이미 존재하는 일부 특성(feature)을 증폭시킨다는 것을 의미
- 2) ∆W는 W의 상위 특이값 방향을 단순히 반복하지 않음. 오히려 W에서 잘 드러나지 않았던 방향을 증폭시키는 역할을 함
- 3) 증폭 계수는 꽤 큼. 예를 들어 r = 4인 경우에는 약 21.5배(6.91 ÷ 0.32). 이는 작은 파라미터로도 높은 성능을 낼 수 있음을 설명함
- 이 결과는 LoRA의 저랭크 적응 행렬(∆W)이 사전학습 모델에서 이미 학습되었지만 크게 강조되지 않았던, 특정 작업에 중요한 특성들을 다시 강조해 주는 역할을 할 수 있음을 시사함
📍8. Conclusion and Future Works
- 거대한 언어 모델을 파인튜닝하는 것은, 다양한 작업마다 독립된 모델 인스턴스를 저장하고 전환하는 데 필요한 하드웨어 자원과 비용이 너무 크기 때문에 현실적으로 어려움
- 이에 대해 본 논문은 LoRA라는 효율적인 적응 전략을 제안함. LoRA는 추론 속도를 느리게 하지 않고, 입력 시퀀스 길이도 줄이지 않으면서도 높은 모델 성능을 유지함
- 특히, LoRA는 대부분의 모델 파라미터를 공유하기 때문에, 서비스로 배포된 상황에서도 다양한 작업 간 빠르게 전환할 수 있음
- 저자들은 Transformer 언어 모델에 초점을 맞췄지만, LoRA의 핵심 원리는 일반적인 밀집층(dense layer)을 가진 어떤 신경망에도 적용할 수 있음
- 향후 연구 방향성
- 1) LoRA는 다른 효율적인 적응 기법들과 결합될 수 있으며, 이로써 서로 보완적인 개선 효과를 낼 수 있음
- 2) 파인튜닝이나 LoRA가 실제로 어떤 방식으로 작동하는지는 아직 명확히 밝혀지지 않음. 사전학습된 특성들이 downstream 작업에서 어떻게 전환되고 작용하는지를 이해할 필요가 있음
- 3) 현재는 어떤 가중치 행렬에 LoRA를 적용할지 경험적 기준(heuristics)에 의존하고 있음. 이걸 더 이론적인 원칙에 따라 결정하는 방법이 있을까?
- 4) ∆W가 저랭크(rank-deficient)라는 점은 원래 가중치 W도 저랭크일 수 있다는 가능성을 시사함
💬 9. Takeaway
단순히 Hugging Face에서 LoraConfig를 활용해 모델을 튜닝할 때 접했던 개념이 실제로 어떤 이론적 배경과 아이디어에서 출발했는지 이해할 수 있었다. 7장에서 제시된 실험 결과들을 완전히 이해하진 못했지만, LoRA가 단순한 효율화 기법을 넘어 대규모 모델 활용의 문턱을 낮추는 중요한 시도라는 점은 확실히 느낄 수 있었다. 앞으로 더 많은 실험과 응용 사례를 접하면서 LoRA의 장점을 실제 프로젝트와 연구에 어떻게 접목할 수 있을지 탐구해보고 싶다.
'Paper Review > NLP' 카테고리의 다른 글
| [논문 리뷰] LoRA Soups : Merging LoRAs for Practical Skill Composition Tasks (1) | 2026.02.01 |
|---|---|
| [논문 리뷰] Editing Models With Task Arithmetic (0) | 2026.01.30 |
| [논문 리뷰] Transformer : Attention Is All You Need (5) | 2025.05.29 |
'Paper Review/NLP' Related Articles
more


