

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- fine-tuning
- 파인튜닝
- Transformer
- qwen
- moe
- DPO
- GPT
- RAG
- Python
- lora
- DyPRAG
- Retriever
- Statistics
- Noise Robustness
- Hallucination
- Baekjoon
- retrieval
- Parametric RAG
- LLM
- Document Augmentation
- reranking
- odds
- NLP
- Noise
- coding test
- SFT
- Embedding
- COT
- Do it
- Algorithm
Archives
- Today
- Total
왕구아니다
[논문 리뷰] FACTGUARD : DETECTING UNANSWERABLE QUESTIONS IN LONG-CONTEXT TEXTS FOR RELIABLE LLM RESPONSES 본문
Paper Review/Synthetic Dataset
[논문 리뷰] FACTGUARD : DETECTING UNANSWERABLE QUESTIONS IN LONG-CONTEXT TEXTS FOR RELIABLE LLM RESPONSES
Psalms 12:6-7 2026. 2. 24. 00:22본 논문 리뷰는 저의 개인적인 해석과 의견을 바탕으로 작성된 글입니다.
내용 중 해석의 오류나 개념적인 착오가 있다면, 망설이지 마시고 댓글로 혼내주시면 감사하겠습니다~
Preview
- FactGuard는 장문 문맥(Long-context) 환경에서 LLM이 답할 수 없는 질문에 대해 환각을 생성하는 문제를 해결하기 위해, answerable과 현실적인 unanswerable 질문을 자동으로 생성하는 협업적 다중 작업 프레임워크를 제안
- 이를 통해 구축된 FactGuard-Bench(25,220개 예시)는 4K~128K 길이의 문맥에서 모델이 “답할 수 없음”을 추론 기반으로 설명하며 거부하는 능력을 평가하도록 설계되었으며, 실험 결과 기존 LLM들은 answerable과 unanswerable 사이에 큰 성능 격차를 보이고 문맥이 길어질수록 성능이 감소함
- 그러나 FactGuard-Bench로 fine-tuning할 경우 다양한 모델 규모에서 unanswerable 처리 및 추론 기반 거부 능력이 크게 향상되었고, 다른 벤치마크(SQuAD 2.0)에서도 일반화 성능을 보이며 LLM 신뢰성 향상에 효과적인 전략임을 입증함
Link
- 논문 : https://openreview.net/forum?id=c4nZkkyl6E
FactGuard: Detecting Unanswerable Questions in Long-Context Texts...
Large language models (LLMs) have demonstrated significant advances in reading comprehension. However, a persistent challenge lies in ensuring these models maintain high accuracy in answering...
openreview.net
📍0. Abstract
- 대형 언어 모델(LLM)은 독해 능력(reading comprehension)에서 상당한 발전을 보여주었음에도 불구하고 질문에 대해 높은 정확도를 유지하면서 동시에 답할 수 없는 질문(unanswerable queries)을 신뢰성 있게 인식하도록 보장하는 것은 여전히 지속적인 과제이다.
- 이 문제를 해결하기 위해, FactGuard라는 협업적 다중 작업 워크플로우를 제안하며, 이는 근거 기반의 질문-답변 쌍을 자동 생성하고 체계적으로 답할 수 없는 질문을 구성한다.
📍1. Introduction
- 이전 Unanswerable 관련 데이터셋
- SelfAware(Yin et al., 2023)는 LLM이 답할 수 없는 질문을 탐지하고, “The answer is unknown”과 같은 사전 정의된 응답을 사용하도록 유도하는 단순한 접근 방식을 사용한다.
- KUQ(Amayuelas et al., 2024)는 독해 기반 질문이 아니라, 개방형 질의응답 시나리오에서 Known-Unknown 질문을 다룬다.
- Self-Aligned 방법(Deng et al., 2024)은 주로 답할 수 없는 질문에 대한 추론 응답에 초점을 맞추며, 장문 문맥을 고려하지 않고, 수동으로 라벨링된 질문을 시드 데이터로 요구한다.
- 위의 한계를 극복하기 위해, 자동 데이터 증강을 가능하게 하는 협업적 다중 작업 워크플로우 프레임워크를 사용하는 새로운 접근법을 제안한다.
- 따라서 FactGuard-Bench를 소개하며, 이는 25,220개의 질문(8,829개는 답 가능, 16,391개는 답 불가능)으로 구성된 독해 데이터셋으로, 문맥 길이는 4K에서 128K까지이며 협업적 다중 작업 워크플로우 프레임워크를 통해 구축되었다.
📍2. FACTGUARD METHODOLOGY

- FactGUARD는 3단계로 구성되어 있다.
- Preparation Stage
- Answerable QA Generation Stage
- Unanswerable QA Generation Stage
2.1 PREPARATION STAGE
- 원본의 긴 문서를 여러 개의 짧은 텍스트 조각(fragment)으로 분할한다.
- 윈도우 크기는 500~1000 토큰으로 유지하며, 분할은 문단 단위로 수행된다.
- 이후의 하위 단계들을 위해 Fragment X를 무작위로 선택한다. (모든 fragment를 다 쓰는 게 아니라 랜덤 샘플링을 통해 다양성 확보)
- Quality Scoring
- LLM을 사용하여 Fragment X를 유창성(fluency), 일관성(coherence), 논리성(logicality) 측면에서 평가하고, 1~5점 척도의 품질 점수를 부여한다.
- Fluency → 문장이 자연스러운가?
- Coherence → 문맥이 연결되어 있는가?
- Logicality → 논리적으로 말이 되는가?
- 점수가 4점 미만인 fragment는 높은 품질을 보장하기 위해 폐기한다.
- LLM을 사용하여 Fragment X를 유창성(fluency), 일관성(coherence), 논리성(logicality) 측면에서 평가하고, 1~5점 척도의 품질 점수를 부여한다.
- Topic Labeling
- 이후 LLM을 사용하여 Fragment X로부터 구조화된 정보(예: 시간 표현, 수치 값, 개체, 장소, 조직, 사건 등)를 추출하여 주제 라벨로 활용한다.
- 명확한 구조화 정보가 없는 fragment는 폐기한다.
- 구조 정보(structured information)가 없으면 질문 만들기 어려움, evidence 명확하지 않음, entity substitution 불가능, impossible condition 삽입 불가능
- Preparation 단계 이후, 원본 장문 문서로부터 명확한 구조 정보를 갖춘 고품질 fragment들을 확보하게 된다.
2.2 ANSWERABLE QA GENERATION STAGE
- Answerable QA 생성 단계에서는 Preparation 단계에서 확보한 고품질 fragment를 기반으로 질문, 답변, 그리고 근거(evidence)를 생성한다.
- 여기서 evidence는 답변을 뒷받침하는 fragment 내의 특정 텍스트 구간으로 구성된다. (반드시 원문 fragment의 일부)
- LLM 생성 결과에는 유창하지 않은 질문이나, evidence가 fragment에서 나오지 않는 등의 저품질 결과가 존재하므로, answerable QA 생성 이후 품질 판단을 통해 이를 필터링한다.
- QA 생성 단계를 거치면, 원본 텍스트로부터 파생된 답 가능한 질문, 답변, 그리고 근거를 얻을 수 있다.
2.3 UNANSWERABLE QA GENERATION STAGE
- Unanswerable QA 생성 단계에서는, 이전 QA 생성 단계에서 이미 생성된 answerable 질문을 기반으로 답할 수 없는 질문과 그에 대응하는 답변을 생성한다.
- Answerable QA를 출발점으로 삼는다. (완전히 무작위로 unanswerable 생성하는 게 아니라 원래는 답이 있었던 질문을 변형)
- Unanswerable questions of lacking evidence
- 단순히 fragment에서 evidence를 제거하여, 정보 부족으로 인해 질문이 답할 수 없도록 만든다.
- 즉, context에서 답을 뒷받침하는 핵심 문장만 제거. 그러면 질문은 여전히 문맥과 관련 있어 보이지만 실제로는 답을 찾을 수 없음. 이게 “Lack of Evidence” 타입
- 거부 응답의 경우, LLM에게 질문을 반영한 합리적인 거부 응답을 생성하도록 요청하며, 이후 문서의 주요 내용을 언급하여 해당 답이 텍스트에서 찾을 수 없음을 증명하도록 한다.
- 단순히 “The answer is unknown.”가 아닌 왜 없는지 설명 & 문서 내용과 연결해서 설명
- 단순히 fragment에서 evidence를 제거하여, 정보 부족으로 인해 질문이 답할 수 없도록 만든다.
- Unanswerable questions of misleading evidence
- LLM을 사용하여 질문을 개체 치환(entity substitution)이나 불가능한 조건 삽입(impossible condition insertion)을 통해 재작성하여 오도된 질문을 만든다.
- 질문을 개체 치환으로 재작성할 때, LLM이 생성하는 거부 응답에서 문서에 등장하는 내용이 치환 이전의 개체와 관련이 있음을 명시하고, 치환 이후 개체와는 관련이 없음을 분명히 하도록 요구한다.
- 질문을 불가능한 조건 삽입을 통해 재작성할 경우, LLM이 먼저 해당 조건이 원문에 존재하지 않음을 설명하고, 이후 원래 질문에 대한 답을 제공하도록 요구한다.
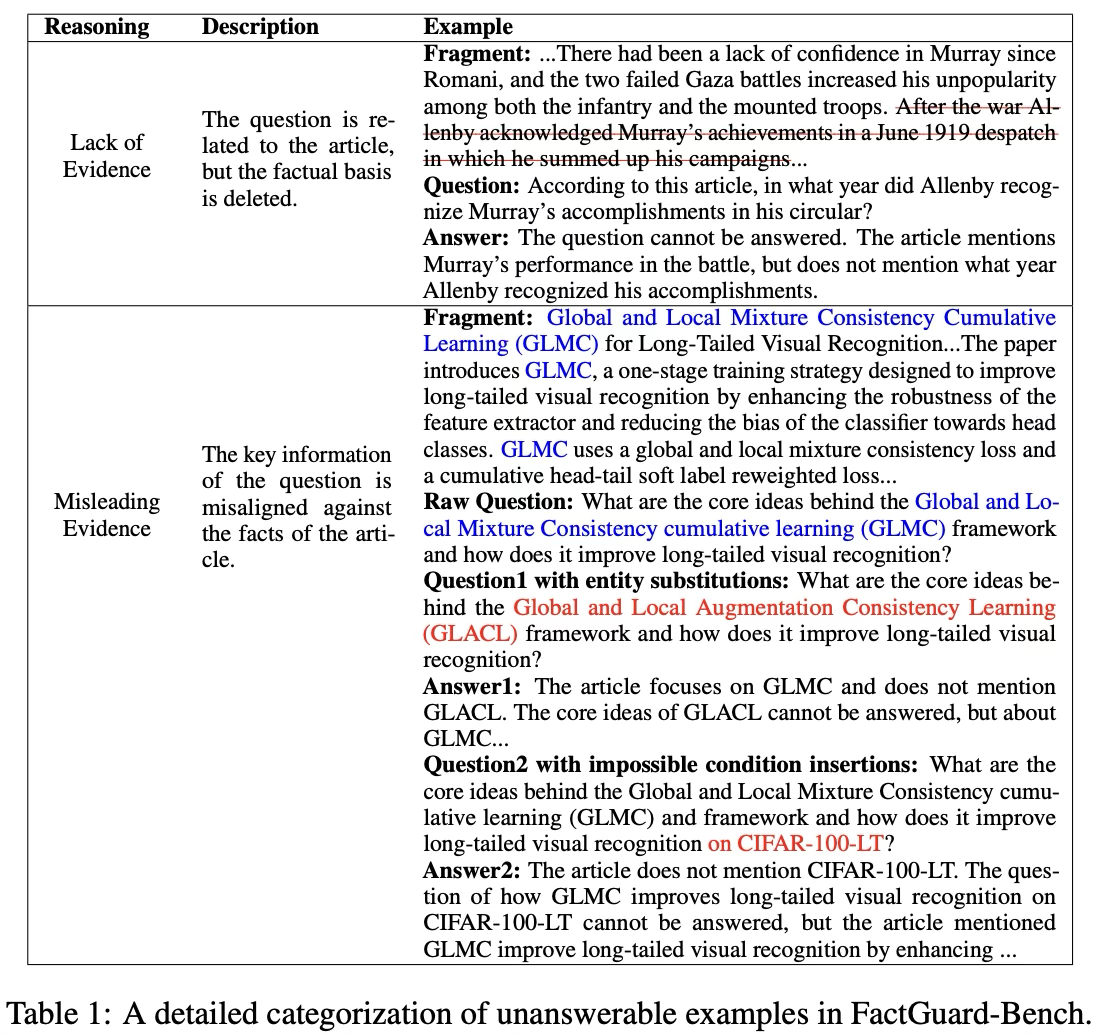
- [Table 1 참고] 앞서 말한 것처럼, 근거 부족형 unanswerable 질문의 경우, 원래 fragment에서 evidence를 제거한다. 오도된 근거형 unanswerable 질문의 경우, fragment는 그대로 유지하고 질문만 개체 치환 또는 불가능한 조건 삽입으로 재작성한다.
- 여기서 중요한 건 완전히 unrelated 질문이 아니라 여전히 문서와 관련된 질문
- 답 가능한 질문과 답 불가능한 질문의 품질을 보장하기 위해, 생성된 데이터를 검토하는 과정에서 RAG 기법을 활용한다.
- 이 접근 방식은 긴 문서에서 상위 N개의 관련 문단을 추출하여 짧은 독해 형태로 검토할 수 있게 하며, 서로 충돌하는 답변을 포함하는 데이터를 걸러낼 수 있도록 한다.
- 즉, “한 fragment만 보고 QA를 만들었는데, 문서 다른 부분에 다른 답이 있으면 어떻게 할 것인가?”
- LLM이 fragment 단위로 QA를 생성하면 → 문서 전체 문맥(global context)와 충돌할 수 있음. RAG 검증은 이 global consistency를 보장하는 장치
- 또한 상식적 지식을 필터링하기 위해 웹(World Wide Web)을 활용하며, 이를 통해 문맥 충실성(context-faithfulness)과 상식 정확성(common-sense accuracy) 사이의 본질적인 충돌을 효과적으로 회피한다.
- 예를 들어, 문서에 “The Earth has two moons.” 라고 적혀 있다면?
- 문맥 기준으로는 답은 two moons (context-faithful)
- 하지만 상식적으로는 틀림 (지구는 1개)
- LLM은 여기서 딜레마에 빠진다. 문맥을 따를 것인가? 상식을 따를 것인가?
- 따라서 외부 웹 검증을 통해 명백히 상식적으로 틀린 경우 제거. 즉, synthetic data가 상식적으로 말이 안 되는 경우 필터링
📍3. BENCHMARK CONSTRUCTIONS
- FactGuard는 다중 작업 협업 과정을 활용하여 답 가능한 질문과 답 불가능한 질문을 동적으로 생성한다.
- 전체 과정의 기반이 되는 LLM은 Qwen2.5-72B-Instruct이다.
- 프로세스의 초기 입력으로 오픈소스 커뮤니티에서 원시(raw) 장문 텍스트를 수집한다.
- 이 텍스트들은 중국어와 영어를 모두 포함하며, 법률과 서적 등 다양한 도메인을 아우른다.
- 구체적으로, 데이터셋에는 Pile of Law, Tiger Law와 같은 법률 데이터셋, Gutenberg 서적 데이터셋, 공개 저작권 중국어 서적 등이 포함된다.
3.1 CHARACTERISTICS
- FactGuard 프레임워크를 사용하여 장문 문맥(long context) 기반의 대규모 데이터셋 FactGuard-Bench를 구축하였다.
- FactGuard-Bench는 16,742개의 텍스트로부터 생성된 25,220개의 데이터 예시를 포함한다.


3.2 MANUAL REVIEW
- 합성 데이터의 품질을 검증하기 위해, 480개의 예시를 무작위로 샘플링하여 수동 검토를 수행하였다.
- 각 예시는 세 명의 주석자가 독립적으로 평가하였으며, 인간 평가 가이드라인에 따라 해당 예시를 적합(qualified) 또는 부적합(unqualified)으로 분류하였다.

- Fleiss의 Kappa로 측정한 평가자 간 일치도는 κ = 0.64로 상당한 수준이었으며, 이는 인간 판단이 신뢰할 만함을 의미한다.
- FactGuard-Bench의 전체 품질은 93.96%

📍4. EXPERIMENTS
4.1 IMPLEMENTATION DETAILS
- FactGuard-Bench에서 LLM의 성능을 평가하기 위해, Supervised Fine-Tuning(SFT)과 Reinforcement Learning from Human Feedback(RLHF)을 통해 instruction-tuned된 여러 오픈소스 모델을 포함하여 실험을 수행하였다.
- Mistral-Large-Instruct-2411 (123B), DeepSeek-V3-0324 (685B), Llama3.3-70B-Instruct, 그리고 Qwen2.5 시리즈 모델
- 한 여러 상용(proprietary) 모델에 대해 API 호출을 통해 평가 결과를 얻었다.
- 여기에는 OpenAI의 GPT-4o와 Gemini1.5 Pro가 포함된다.
- FactGuard-Bench의 효과를 검증하기 위해, Qwen2.5 시리즈 모델에 대해 전체 파라미터를 업데이트하는 SFT 학습을 수행하였다.
- AdamW 옵티마이저를 사용하였으며, 학습률은 2 × 10⁻⁵로 설정하고 2 epoch 동안 full-parameter SFT를 수행하였다. warm-up 비율을 0.1로 설정하고, weight decay는 0.1로 설정하였다.
4.2 EVALUATION SETTINGS AND METRICS
- 모델의 예측 답변과 정답 간의 일관성(consistency)을 평가함으로써 모델의 능력을 측정하며, 임계값 조정이 필요한 Exact Match(EM)나 F1과 같은 지표에 의존하지 않는다.
- LLM-as-Judge 접근법의 판별 능력을 활용하여, answerable 질문과 unanswerable 질문을 구분하여 평가한다.
- Answerable 질문의 경우, 예측 답변이 정답의 올바른 정보 조각을 포함하면 1점을 부여하고, 그렇지 않으면 0점을 부여한다.
- Unanswerable 질문의 경우, 응답이 질문이 답할 수 없음을 적절히 인식하면(예: 거부 응답), 1점을 부여하고, 환각 내용을 생성하면 0점을 부여한다.
- 실험에서 판별 모델(discriminant model)로 Qwen2.5-72B-Instruct를 선택하였다.
- LLM 기반 평가의 정확도는 인간 평가 이후 약 94% 수준

4.3 EXPERIMENTAL RESULTS
4.3.1 ANSWER CONSISTENCY EVALUATION

- “answer consistency”는 Answerable → 정답 정보 포함 여부, Unanswerable → 적절한 거부 여부
- Table 3에서 상용 모델과 오픈소스 모델 모두 answerable 질문과 unanswerable 질문 사이에 상당한 성능 격차가 있음을 명확히 확인할 수 있다.
- 예를 들어, GPT-4o는 중국어 answerable 질문에서 87.89% 정확도를 달성하지만, lack of evidence 유형의 unanswerable에서는 37.06%, misleading evidence에서는 30.3%에 불과하다.
- 이러한 경향은 현재 LLM이 unanswerable 질문을 처리하는 데 한계를 가지고 있음을 보여준다.
4.3.2 SCALING COMPARISON EVALUATION

- Qwen 시리즈 모델에 대해 SFT 실험을 수행하였으며, 그 결과는 Table 4
- 결과는 다양한 규모의 모델들이 SFT 이후에 성능이 크게 향상되었음을 보여준다.
- 예를 들어, Qwen2.5-3B-Instruct는 SFT 이후 전체 정확도가 45.39%에서 78.94%로 상승하였다.
- 주목할 점은, 모델 규모가 증가함에 따라 전체 정확도가 향상되며, 모든 규모의 모델이 unanswerable 질문에서 상당한 개선을 달성했다는 것이다.
- 또한, SFT 실험은 FactGuard-Bench로 fine-tuning할 때 내재된(trade-off) 성능 상충 관계가 존재함을 보여준다.
- 이는 Qwen2.5-14B-Instruct의 중국어 성능에서 확인할 수 있는데, unanswerable 질문에 대한 능력은 향상되었지만 answerable 질문에서는 약간의 성능 감소가 발생하였다.

- Figure 3에서는 다양한 규모의 Qwen 시리즈 모델이 영어 unanswerable 질문에서 보이는 예측 정확도를 제시한다.
- 모델 규모가 증가함에 따라 Qwen 모델이 unanswerable 질문에서 점진적으로 더 강한 성능을 보인다는 것을 명확히 확인할 수 있으며, 특히 lack of evidence 유형에서 그 경향이 두드러진다.
- 또한 FactGuard-Bench로 SFT 이후, 다양한 규모의 모델들이 일관되게 unanswerable 질문에서 강한 성능을 달성하였다.
4.3.3 DIFFERENT LENGTH INTERVALS EVALUATION
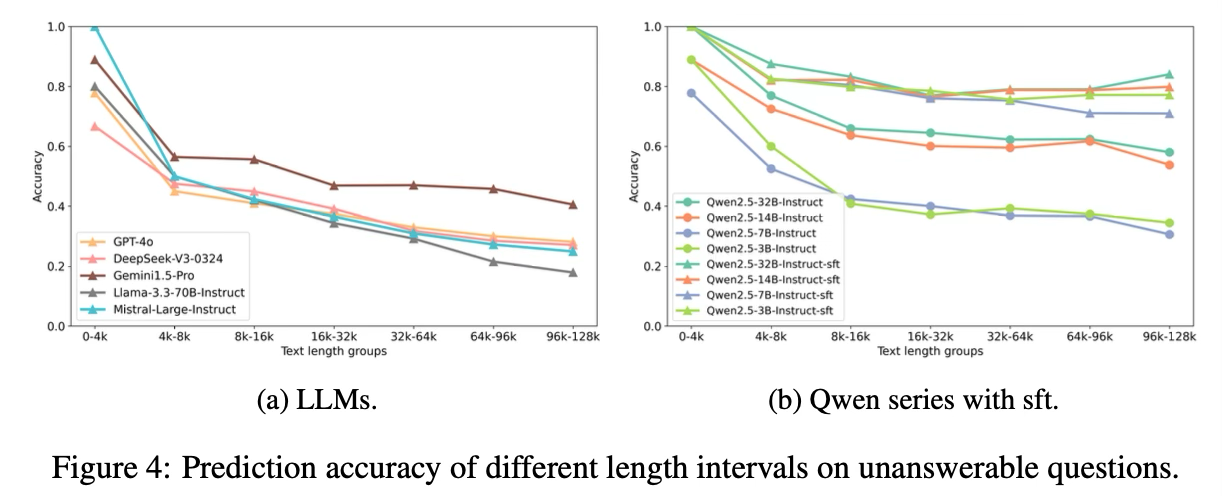
- Figure 4는 다양한 길이 구간에서 unanswerable 질문에 대한 예측 정확도를 제시한다.
- Figure 4a에서 모든 모델이 짧은 텍스트(0–4K)에서 가장 높은 성능을 보이며, 텍스트 길이가 증가함에 따라 성능이 눈에 띄게 감소하는 것을 명확히 확인할 수 있다.
- Figure 4b에서는 Qwen2.5 시리즈 모델에 대한 SFT 결과를 제시한다.
- 결과는 모든 길이 구간에서 unanswerable 질문에 대해 상당한 성능 향상이 나타났으며, baseline 시스템보다 일관되게 더 우수한 성능을 보였다.
- 이러한 결과는 FactGuard-Bench가 모델의 강건성(robustness)을 향상시키는 데 가치가 있음을 강조하며, unanswerable 질문을 처리하는 모델의 평가 및 개발을 촉진하는 벤치마크로서의 효과를 확인해준다.
4.3.4 REASONING ABILITY EVALUATION FOR UNANSWERABLE QUESTIONS
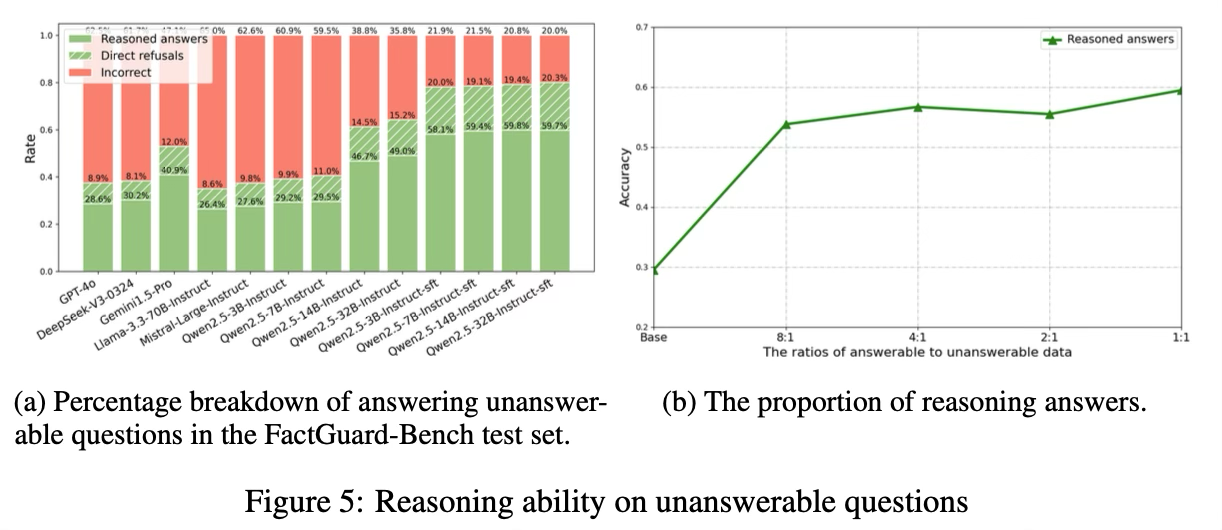
- 모델이 답할 수 없는 질문을 거부하는 능력과, 환각(hallucination) 내용을 생성하지 않는 능력을 평가한다.
- 구체적으로, LLM을 사용하여 unanswerable 질문에 대한 응답을 세 가지 유형으로 분류한다.
- (1) 잘못된 답변
- (2) 직접적인 거부 응답
- (3) 추론을 포함한 올바른 응답
- Figure 5a의 결과는 baseline 모델들이 거부하거나 추론 기반 응답을 제공하기보다, 잘못된 답변을 생성하는 경향이 지배적임을 보여준다.
- 주목할 점은 SFT 적용 이후 응답 정확도가 향상되었을 뿐 아니라, 추론 기반 응답의 비율도 크게 증가했다는 것이다.
- 또한 Qwen2.5-7B-Instruct의 SFT에서 answerable 대 unanswerable 데이터 비율을 변화시켰을 때 추론 능력이 어떻게 변하는지를 분석하였으며, 이는 Figure 5b에 제시되어 있다.
- 결과는 8:1과 같은 비교적 낮은 비율에서도 추론 성능이 크게 향상됨을 보여준다.
- 이러한 결과는 FactGuard-Bench가 unanswerable 질문에 대한 추론 능력을 효과적으로 향상시킬 수 있음을 보여주며, 이는 질문에 명확한 답이 없는 이유를 선제적으로 설명하고 사용자가 질문을 수정하거나 기대를 조정하도록 돕는 데 중요하다.
4.3.5 CROSS-BENCHMARK GENERATION ABILITY EVALUATION

- 일반화 가능성을 평가하고 합성 데이터에 과적합(overfit)되지 않았음을 확인하기 위해, FactGuard-Bench로 fine-tuning된 Qwen2.5 시리즈 모델을 SQuAD 2.0 데이터셋(완전한 인간 주석 기반 answerable 및 unanswerable 질문 포함)에서 교차 벤치마크 검증을 수행하였다.
- “자동 생성 데이터로 학습했는데, 진짜 사람 데이터에서도 통할까?”
- Table 5에서 보이듯이, FactGuard-Bench로 학습된 모델은 SQuAD 2.0의 dev 세트에서 평가되었으며, 전체 지표에서 개선을 보였고 특히 unanswerable 질문 처리에서 향상이 나타났다.
- 또한 unanswerable 질문 처리 능력은 향상되었지만, answerable 질문에서는 성능 감소가 발생함을 확인할 수 있다.
- Catastrophic Forgetting : 기존 QA 능력 손실 문제
- Data Concentration Effects : Unanswerable 데이터 비율이 너무 높을 경우, 모델이 한 방향으로 치우침
- LoRA Mitigation : Full-SFT 대신 LoRA 사용하면 기존 능력 보존 가능성
- 그리고 모델 규모가 증가할수록 fine-tuning을 통해 개선할 수 있는 여지는 점점 줄어든다.
📍5. Conclusion
- 본 논문에서는 문맥적으로 높은 관련성을 유지하면서 answerable 질문과 현실적인 unanswerable 질문을 동적으로 생성하는 협업적 다중 작업 워크플로우 프레임워크인 FactGuard를 제시하였다.
- 또한 장문 독해 환경에서 LLM이 answerable 및 unanswerable 질문을 처리하는 성능을 평가하기 위해 정교하게 구축된 벤치마크 FactGuard-Bench를 제공하였다.
- 실험 결과, LLM은 answerable 질문과 unanswerable 질문 사이에서 상당한 성능 격차를 보였으며, 짧은 텍스트에서 가장 높은 성능을 보이고 텍스트 길이가 증가할수록 성능이 눈에 띄게 감소하였다.
- FactGuard-Bench로 학습하면 모델의 unanswerable 질문 처리 능력이 추론 기반 응답과 함께 향상되며, 다양한 길이 구간에서도 성능이 개선된다.
'Paper Review/Synthetic Dataset' Related Articles
more
