

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Retriever
- RAG
- moe
- DyPRAG
- NLP
- Statistics
- Algorithm
- Python
- SFT
- qwen
- Noise
- Noise Robustness
- fine-tuning
- Do it
- Document Augmentation
- Hallucination
- COT
- lora
- LLM
- Transformer
- odds
- Baekjoon
- Parametric RAG
- Embedding
- 파인튜닝
- retrieval
- coding test
- DPO
- GPT
- reranking
- Today
- Total
왕구아니다
[통계] 가설검정 본문
엄청 딥한 내용보단 용어 정리 느낌으로 포스팅합니다🫡
1️⃣ 가설검정의 기본 개념
가설검정은 관측된 데이터(표본)를 통해 모집단에 대한 주장(가설)을 기각할지 채택할지 결정하는 의사결정 규칙을 만드는 과정입니다.
1.1 가설의 종류와 검정의 원리
- 귀무가설(H0, Null Hypothesis): 기존의 사실이나 무의미한 상태를 나타냅니다. (예: 𝜃 = 1500) "Null"은 '차이가 없다', '효과가 없다'는 의미를 내포합니다.
- 대립가설(H1, Alternative Hypothesis): 입증하고자 하는 새로운 주장입니다. (예: 𝜃 > 1500)
- 검정통계량(Test Statistic): 검정의 기준이 되는 통계량입니다.
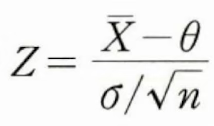
- 기각역(Critical Region): 검정통계량의 관측값이 이 영역에 속하면 H0를 기각합니다.

💡 핵심 원리: H0가 참이라고 가정했을 때, 관측된 데이터가 나올 확률이 희박하다면(기각역에 속한다면), 우리는 H0를 의심하고 기각하게 됩니다.
📝 [예] 전구 수명 문제 (검정의 직관적 이해)
어느 회사의 전구 수명은 정규분포 N(1500, 100^2)를 따른다고 합니다. 연구팀이 수명을 늘린 신제품을 개발했다고 주장하며, 25개를 표본 추출하여 평균 x̄ = 1550시간을 얻었습니다. 이 주장을 받아들일 수 있을까요? (유의수준 5%)

1.2 두 종류의 오류 (Errors)
가설검정은 불확실성 하에서의 결정이므로 오류가 발생할 수 있습니다.

- 유의수준(a): 제1종 오류를 범할 확률의 허용한계. (보통 0.05, 0.01 사용) → 제 1종의 오류는 유의수준에 의해 관리된다

- 베타(b): 제2종 오류를 범할 확률.

- 검정력(Power, 1-b): H1이 참일 때, 올바르게 H0를 기각할 확률. 높을수록 좋습니다.
1.3 p-값 (p-value)
검정통계량의 관측값에 대해 H0를 기각할 수 있는 최소의 유의수준입니다. p-value는 귀무가설이 참일 확률이 아니다. 귀무가설이 참이라는 가정 하에서, 현재 데이터가 얼마나 극단적인지를 나타내는 값이다.
- 해석: H0가 참일 때, 현재의 데이터보다 더 극단적인 결과가 나올 확률.

📝 [예] 전구 수명 문제 (검정의 직관적 이해)
앞선 전구 문제에서 Z=2.5가 나왔습니다. 표준정규분포표에서 Z ≥ 2.5일 확률은 0.006입니다.
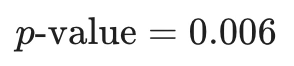
이는 유의수준 0.05보다 훨씬 작으므로, "귀무가설 하에서 이런 데이터가 나올 확률은 0.6%에 불과하다(매우 희박하다)"라고 해석할 수 있습니다.
1.4 검정력 함수 (Power Function)
단순히 a,b 값이 아니라, 모수 𝜃의 변화에 따른 기각 확률을 함수로 나타낸 것입니다.

- 𝜃 ∈H0 일 때: π(𝜃) ≤ a (제1종 오류 확률)
- 𝜃 ∈H1 일 때: π(𝜃) = 1 - B(𝜃) (검정력)

📝 [예제] 검정력 함수의 계산
X ~ N(𝜃,4), n=25일 때 H0: 𝜃=0 vs H1: 𝜃 > 0을 검정합니다. 기각역이 x̄ ≥ 0.784로 주어졌다면 검정력 함수는?

- 𝜃 = 0 (귀무가설 참)이면 π(0) = 0.025 (a)
- 𝜃 = 1 (대립가설 참)이면 π(1) ≈ 0.97 (검정력이 매우 높음)
- 이처럼 𝜃가 커질수록 H0를 기각할 확률(검정력)이 높아짐을 곡선으로 보여줍니다.
1.5 확률화 검정 (Randomized Test)
이산형 분포(이항분포, 포아송분포 등)에서는 정확히 5%(0.05) 같은 유의수준을 맞추기 어렵습니다. 이때는 검정함수 φ(x)를 도입하여 경계값에서 동전 던지기처럼 확률적으로 기각 여부를 결정해 a를 정확히 맞춥니다.
- 이론적으로는 중요하지만, 실제 데이터 분석에서는 p-값을 주로 사용하므로 드물게 쓰입니다.
1.6 가설검정과 신뢰구간의 관계 (Duality)
𝜃에 대한 100(1-a)% 신뢰구간이 𝜃0를 포함하지 않으면, 유의수준 a에서 H0: 𝜃=𝜃0를 기각합니다. 둘은 동전의 양면과 같습니다.
2️⃣ 가설검정의 이론
어떤 검정법이 가장 좋을까요? 통계학에서는 유의수준 a를 고정시킨 상태에서 검정력(1-b)을 최대화하는 검정을 최적이라고 봅니다.
2.1 네이만-피어슨 정리 (Neyman-Pearson Lemma)
단순가설(H0: 𝜃 = 𝜃0 vs H1: 𝜃 = 𝜃1)을 검정할 때, 가장 강력한 검정(Most Powerful Test, MP 검정)을 찾는 방법입니다.
- 핵심: 가능도비(Likelihood Ratio)가 기준 k보다 작을 때 기각합니다. (즉, H1에서의 가능도가 H0보다 월등히 클 때 기각)

📝 [예제 5-8] 지수분포의 최강력 검정 도출
X 하나를 관측하여 지수분포의 평균 u를 검정합니다. (H0: u=1 vs H1: u=2 (a=0.1))

2.2 균일 최강력 검정 (UMP Test)
대립가설이 복합가설(H1: 𝜃 > 𝜃0)인 경우, H1의 모든 𝜃 범위에서 검정력이 가장 높은 검정을 UMP(Uniformly Most Powerful) 검정이라 합니다.
- 지수족(Exponential Family) 분포와 같이 단조 가능도비(Monotone Likelihood Ratio, MLR) 성질을 가지면 UMP 검정이 존재합니다. (단, 양측 검정에서는 UMP가 존재하지 않는 경우가 많습니다.)
2.3 가능도비 검정 (Likelihood Ratio Test, LRT)
네이만-피어슨 정리는 단순가설에만 적용되므로, 이를 일반화한 것이 LRT입니다. 가장 널리 쓰이는 만능 도구입니다.

점근 분포: 표본의 크기 n이 클 때, -2lnλ는 자유도가 (전체 모수 개수 - 귀무가설 모수 개수)인 카이제곱 분포를 따릅니다. 이를 이용해 기각역을 설정합니다.
'Long-term Memory > Statistics' 카테고리의 다른 글
| [통계] Confusion Matrix (0) | 2026.01.15 |
|---|---|
| [통계] 범주형자료분석 2 (1) | 2026.01.15 |
| [통계] 범주형자료분석 1 (0) | 2026.01.14 |


