

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- RAG
- SFT
- fine-tuning
- moe
- Statistics
- DyPRAG
- Hallucination
- LLM
- Python
- Retriever
- coding test
- Transformer
- Baekjoon
- Document Augmentation
- lora
- odds
- qwen
- DPO
- Noise
- GPT
- Parametric RAG
- 파인튜닝
- reranking
- Embedding
- Do it
- retrieval
- NLP
- Noise Robustness
- Algorithm
- COT
Archives
- Today
- Total
왕구아니다
Note 4. 정렬 본문
"Do it! 알고리즘 코딩 테스트 파이썬 편 [개정판]"을 기반으로 공부한 내용을 정리한 포스팅입니다 📚
1️⃣ 버블 정렬

데이터의 인접 요소끼리 비교하고, swap 연산을 수행하며 정렬하는 방식
- 시간 복잡도 : O(n^2)
[수행 과정]
1) 비교 연산이 필요한 루프 범위 설정
2) 인접한 데이터 값 비교
3) swap 조건에 부합하면 swap 연산 수행
4) 루프 범위가 끝날 때까지 2)~3) 반복
- 안쪽 for 문 전체를 돌 때(1~n-i까지) swap이 일어나지 않았다는 것은 이미 모든 데이터가 정렬됐다는 의미
- If Question : 안쪽 for 문이 몇 번 수행됐는지 구하는 문제?
- 이를 다르게 생각하면, 특정 데이터가 안쪽 루프에서 swap의 왼쪽으로 이동할 수 있는 최대 거리는 1. 즉, 데이터의 정렬 전
index와 정렬 후 index를 비교해 왼쪽으로 가장 많이 이동한 값을 찾으면 됨
- ex) 배열: [10, 1, 5, 2, 3]
- 이 배열을 오름차순 정렬한다고 가정하면 정렬 결과는 [1, 2, 3, 5, 10]
- 숫자 2 (작은 수): index 3에 있음. 정렬 후에는 index 1로 가야함(총 2칸 왼쪽 이동 필요)
- 버블 정렬 1회전 후: [1, 5, 2, 3, 10] (2는 index 2로 1칸 이동)
- 버블 정렬 2회전 후: [1, 2, 5, 3, 10] (2는 index 1로 도착). 즉, 왼쪽으로 2칸 가야 한다면 최소 2번의 루프가 필요
- 왼쪽으로 가장 많이 이동해야 하는 거리가 곧 버블 정렬이 수행되어야 하는 횟수
- 이동 거리 = 정렬 전 Index - 정렬 후 Index. 이 값이 양수(왼쪽 이동)인 것 중 최댓값을 찾으면, 그게 바로 버블 정렬의 루
프 횟수
- (번외) 코테 문제에서 정렬이 끝났음을 확인하는 단계를 횟수에 포함할 경우 최댓값 + 1
: +1 하는 경우 (90% 이상) : 문제 코드가 "Swap이 없으면 break" 하는 구조이고, "몇 번째 루프에서 끝나는가(몇 단계
인가)"를 물을 때.(정렬 완료 루프) + (확인 루프) = Max + 1
: +1 안 하는 경우 : 순수하게 "데이터가 이동한 횟수"만 물을 때. 혹은 문제에서 "정렬 상태를 확인하는 패스는 횟수에서
제외한다"는 조건이 있을 때
5) 정렬된 영역 설정. 다음 루프를 실행할 때는 이 영역 제외
6) 비교 대상이 없을 때까지 1)~5) 반복
- sort() 함수의 시간 복잡도 : O(nlogn)
2️⃣ 선택 정렬

대상 데이터에서 최대나 최소 데이터를 데이터가 나열된 순으로 찾아가며 선택하는 방법
- 구현이 복잡하고 시간 복잡도가 O(n^2)으로 비효율적이라 코테에서 많이 사용하지 않음(응용 문제 나올 수 있음)
- 최솟값 또는 최댓값을 찾고, 남은 정렬 부분의 가장 앞에 있는 데이터와 swap
[수행 과정]
1) 남은 정렬 부분에서 최솟값 또는 최댓값 찾기
2) 남은 정렬 부분에서 가장 앞에 있는 데이터와 선택된 데이터를 swap
3) 가장 앞에 있는 데이터의 위치를 변경해(index++) 남은 정렬 부분의 범위를 축소
4) 전체 데이터 크기만큼 index가 커질 때까지, 즉 남은 정렬 부분이 없을 때까지 반복
3️⃣ 삽입 정렬

이미 정렬된 데이터 범위에 정렬되지 않은 데이터를 적절한 위치에 삽입시켜 정렬하는 방식
- 시간 복잡도 : O(n^2)
[수행 과정]
1) 현재 index에 있는 데이터 값을 선택
2) 현재 선택한 데이터가 정렬된 데이터 범위에 삽입될 위치를 탐색
3) 삽입 위치부터 index에 있는 위치까지 shift 연산 수행
4) 삽입 위치에 현재 선택한 데이터를 삽입하고 index ++ 연산을 수행
5) 전체 데이터의 크기만큼 index가 커질 때까지, 즉 선택할 데이터가 없을 때까지 반복
# 삽입 정렬 구현
N = 5
for i in range(1,N):
# 1) 현재 값
insert_idx = i
insert_value = A[i]
# 2) 현재 값들을 기준으로 이전 값들과 비교하면서 넣을 위치 찾기
for j in range(i-1,-1,-1):
if A[j] < A[i]:
insert_idx = j+1 # 현재 값 위치는 작은 이전값의 바로 오른쪽
break
# 3) 만약 이전값들이 다 현재값보다 크다 = 리스트 맨 앞에 현재값 삽입
if j == 0:
insert_idx = 0
# 4) 넣을 인덱스 찾았으니 이전 값들을 오른쪽으로 밀면서 공간 만들기
for k in range(i,insert_idx,-1):
A[k] = A[k-1]
# 5) 삽입
A[insert_idx] = insert_value4️⃣ 퀵 정렬

기준값(pivot)을 선정해 해당 값보다 작은 데이터와 큰 데이터로 분류하는 것을 반복해 정렬하는 알고리즘
- pivot을 중심으로 계속 데이터를 2개의 집합으로 나누면서 정렬하는 것이 퀵 정렬의 핵심
- 기준값을 어떻게 선정하는지가 시간 복잡도에 많은 영향을 미침
- 평균적인 시간 복잡도 : O(nlogn)
- 최악의 경우 : O(n^2)
[수행 과정]
1) pivot 설정
2) start가 가리키는 데이터가 pivot 보다 작으면 start를 오르쪽으로 1칸 이동
3) end가 가리키는 데이터가 pivot 보다 크면 end를 왼쪽으로 1칸 이동
4) start가 가리키는 데이터가 pivot 보다 크고, end가 가리키는 데이터가 pivot 보다 작으면 start,end가 가리키는 데이터를 swap하고 start를 오른쪽, end는 왼쪽으로 1칸 이동
5) start와 end를 만날 때까지 반복
6) 끝나면 분리 집합에서 각각 다시 pivot 선정
7) 분리 집합의 요소가 1개 이하가 될 때까지 반복
# 재귀 퀵 정렬 전체 코드 (Hoare 방식)
def quicksort(A, left, right):
if left < right:
p = partition(A, left, right)
quicksort(A, left, p)
quicksort(A, p + 1, right)
def partition(A, left, right):
pivot = A[(left + right) // 2] # 가운데 값을 pivot으로
i = left - 1
j = right + 1
while True:
# 왼쪽에서 pivot보다 큰 값 찾기
i += 1
while A[i] < pivot:
i += 1
# 오른쪽에서 pivot보다 작은 값 찾기
j -= 1
while A[j] > pivot:
j -= 1
# 포인터가 교차되면 분할 완료
if i >= j:
return j
# 값 교환
A[i], A[j] = A[j], A[i]4️⃣ 병합 정렬
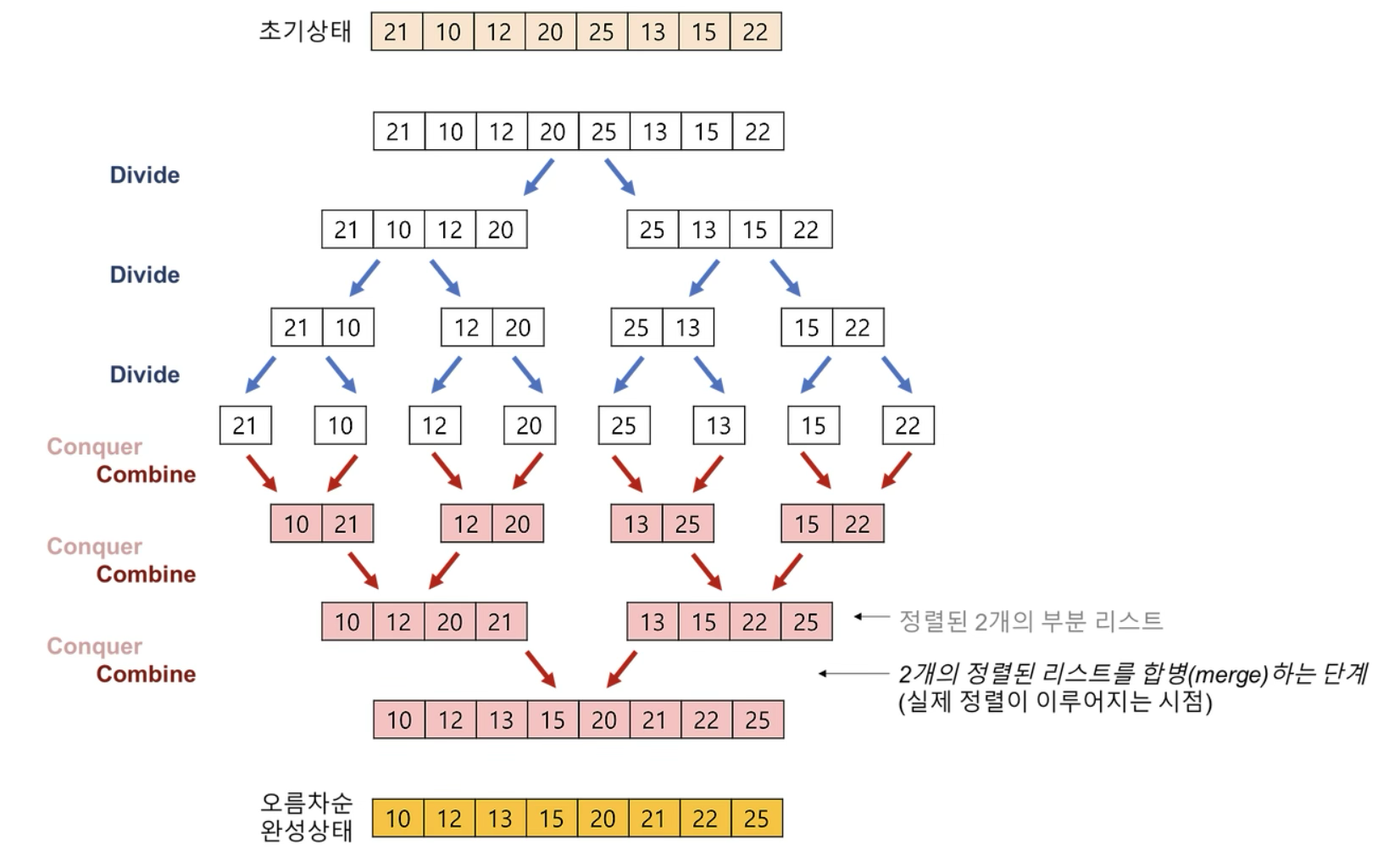
분할 정복 방식을 사용해 데이터를 분할하고 분할한 집합을 정렬하며 합치는 알고리즘
- 시간 복잡도 : O(nlogn)
[2개의 그룹을 병합하는 과정]
- 투 포인터 개념을 사용하여 병합 진행
- ex) [24,32,42,60, | 5,15,45,90] 이런 리스트가 있다고 해보자. 지금 | 기준으로 두 개의 그룹으로 나눠져 있다
- 1) 투 포인터를 사용해 각 그룹에서 첫 번째 인덱스를 시작값으로 사용 (24, 5)
- 2) 투 포인터로 지정된 값들을 비교해서 작은 값을 새로운 배열에 추가 (24 vs 5 = 5가 새로운 리스트에 저장됨) [5,]
- 3) 이렇게 비교한 값 중 작은 데이터를 가리킨 포인터를 오른쪽으로 한 칸 이동. 그럼 이젠 (24 vs 15 비교 진행)
- 4) 이렇게 투 포인터로 지정된 데이터를 비교하며 작은 값을 새로운 리스트에 저장하게 되면 결국 오름차순으로 정렬된 리스트가 나옴 [5,15,24,32,42,45,60,90]
# 병합 정렬 구현 코드
# 로직 : 분할 -> 정렬 -> 병합
def merge_sort(arr:list,temp:list,start_idx,end_idx):
# 0) 원소가 0개 또는 1개인 구간은 이미 정렬된 상태
if end_idx - start_idx <= 1:
return
# 1) 분할
mid_idx = start_idx + (end_idx + start_idx) // 2
# 2) 재귀적으로 정렬
merge_sort(arr,temp,start_idx,mid_idx)
merge_sort(arr,temp,mid_idx,end_idx)
# 3) 병합
i, j, k = start_idx, mid_idx,start_idx
# 양쪽 구간 모두 아직 남은 원소가 있을 때까지 비교하며 병합
while i < mid_idx and j < end_idx:
if arr[i] < = arr[j]:
temp[k] = arr[i]
i += 1
else:
temp[k] = arr[j]
j += 1
k += 1
# 왼쪽 구간에 원소가 남아있다면 그대로 tmp에 복사
while i < mid_idx:
temp[k] = arr[i]
i += 1
k += 1
# 오른쪽 구간에 원소가 남아있다면 그대로 tmp에 복사
while j < end_idx:
temp[k] = arr[j]
j += 1
k += 1
# 4) tmp 결과를 원본 arr로 반영
arr[start_idx:end_idx] = temp[start_idx:end_idx]4️⃣ 기수 정렬

값을 비교하지 않는 특이한 정렬. 값을 놓고 비교할 자릿수를 정한 다음 해당 자릿수만 비교
- 시간 복잡도 : O(kn)
- ex) 234,123을 비교하면 4와3, 3과2, 2와1만 비교
- 기수 정렬은 시간 복잡도가 가장 짧은 정렬
- 만약 코테에서 정렬해야 하는 데이터의 개수가 너무 많으면 기수 정렬 알고리즘 생각하자
5️⃣ 계수 정렬

값을 일일히 비교하지 않고, 각 숫자의 개수를 파악해 정렬
- 시간 복잡도 : O(N+K)
- K = 자료 안 가장 큰 원소값
- K가 작으면 문제가 없지만, K가 커질수록 무한대에 가까워질 수 있음
# 백준 10989 풀이
# 계수 정렬로 풀어보자!
# 1) 값들을 입력받으면 해당 값을 인덱스로 사용하고 개수를 입력
# 2) 출력은 개수만큼 해당 값을 출력
N = int(input())
count = [0] * 10001
# 1)
for _ in range(N):
count[int(input())] += 1
# 2)
for i in range(len(count)):
if count[i] != 0:
for _ in range(count[i]):
print((str(i) + '\n'))| N의 크기 (입력 데이터 수) | 허용되는 시간 복잡도 | 대표적인 알고리즘 |
| N <= 20 | O(N!), O(2^N) | 완전 탐색(Backtracking), 재귀 |
| N <= 1,000 | O(N^2) | 2중 for문, 버블/선택/삽입 정렬 |
| N <= 100,000 | O(NlogN) | 병합/퀵/힙 정렬, 이진 탐색 |
| N <= 10,000,000 | O(N) | 투 포인터, 그리디, DP, 해시(Hash) |
| N > 10,000,000 | O(logN), O(1) | 이진 탐색, 수학적 공식 |
‼️ 끝
'Algorithm Study > Notes' 카테고리의 다른 글
| Note 5. 그리디 알고리즘 (0) | 2026.01.27 |
|---|---|
| Note 5. 탐색 (1) | 2026.01.15 |
| Note 3. 자료구조 (0) | 2026.01.01 |
| Note 2. 미리 보는 오답 노트 (0) | 2025.12.23 |
| Note 1. 시간 복잡도 (0) | 2025.11.29 |
'Algorithm Study/Notes' Related Articles
more


